 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Efficiently Acquiring Annotations for Multilingual Models
Paper and Code

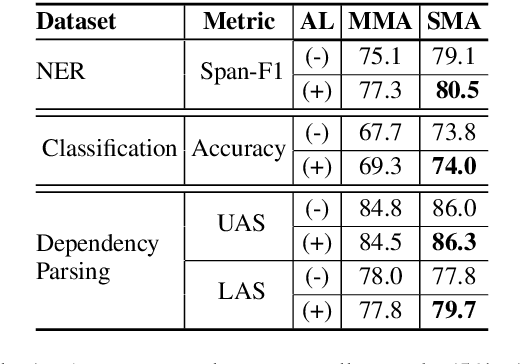


When tasked with supporting multiple languages for a given problem, two approaches have arisen: training a model for each language with the annotation budget divided equally among them, and training on a high-resource language followed by zero-shot transfer to the remaining languages. In this work, we show that the strategy of joint learning across multiple languages using a single model performs substantially better than the aforementioned alternatives. We also demonstrate that active learning provides additional, complementary benefits. We show that this simple approach enables the model to be data efficient by allowing it to arbitrate its annotation budget to query languages it is less certain on. We illustrate the effectiveness of our proposed method on a diverse set of tasks: a classification task with 4 languages, a sequence tagging task with 4 languages and a dependency parsing task with 5 languages. Our proposed method, whilst simple, substantially outperforms the other viable alternatives for building a model in a multilingual setting under constrained budgets.