 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Optical Flow and Textual Prompts Collaborate to Assist in Audio-Visual Semantic Segmentation?
Jan 13, 2026Audio-visual semantic segmentation (AVSS) represents an extension of the audio-visual segmentation (AVS) task, necessitating a semantic understanding of audio-visual scenes beyond merely identifying sound-emitting objects at the visual pixel level. Contrary to a previous methodology, by decomposing the AVSS task into two discrete subtasks by initially providing a prompted segmentation mask to facilitate subsequent semantic analysis, our approach innovates on this foundational strategy. We introduce a novel collaborative framework, \textit{S}tepping \textit{S}tone \textit{P}lus (SSP), which integrates optical flow and textual prompts to assist the segmentation process. In scenarios where sound sources frequently coexist with moving objects, our pre-mask technique leverages optical flow to capture motion dynamics, providing essential temporal context for precise segmentation. To address the challenge posed by stationary sound-emitting objects, such as alarm clocks, SSP incorporates two specific textual prompts: one identifies the category of the sound-emitting object, and the other provides a broader description of the scene. Additionally, we implement a visual-textual alignment module (VTA) to facilitate cross-modal integration, delivering more coherent and contextually relevant semantic interpretations. Our training regimen involves a post-mask technique aimed at compelling the model to learn the diagram of the optical flow. Experimental results demonstrate that SSP outperforms existing AVS methods, delivering efficient and precise segmentation results.
Remember Me: Bridging the Long-Range Gap in LVLMs with Three-Step Inference-Only Decay Resilience Strategies
Nov 13, 2025Large Vision-Language Models (LVLMs) have achieved impressive performance across a wide range of multimodal tasks. However, they still face critical challenges in modeling long-range dependencies under the usage of Rotary Positional Encoding (ROPE). Although it can facilitate precise modeling of token positions, it induces progressive attention decay as token distance increases, especially with progressive attention decay over distant token pairs, which severely impairs the model's ability to remember global context. To alleviate this issue, we propose inference-only Three-step Decay Resilience Strategies (T-DRS), comprising (1) Semantic-Driven DRS (SD-DRS), amplifying semantically meaningful but distant signals via content-aware residuals, (2) Distance-aware Control DRS (DC-DRS), which can purify attention by smoothly modulating weights based on positional distances, suppressing noise while preserving locality, and (3) re-Reinforce Distant DRS (reRD-DRS), consolidating the remaining informative remote dependencies to maintain global coherence. Together, the T-DRS recover suppressed long-range token pairs without harming local inductive biases. Extensive experiments on Vision Question Answering (VQA) benchmarks demonstrate that T-DRS can consistently improve performance in a training-free manner. The code can be accessed in https://github.com/labixiaoq-qq/Remember-me
NCL-CIR: Noise-aware Contrastive Learning for Composed Image Retrieval
Apr 06, 2025Composed Image Retrieval (CIR) seeks to find a target image using a multi-modal query, which combines an image with modification text to pinpoint the target. While recent CIR methods have shown promise, they mainly focus on exploring relationships between the query pairs (image and text) through data augmentation or model design. These methods often assume perfect alignment between queries and target images, an idealized scenario rarely encountered in practice. In reality, pairs are often partially or completely mismatched due to issues like inaccurate modification texts, low-quality target images, and annotation errors. Ignoring these mismatches leads to numerous False Positive Pair (FFPs) denoted as noise pairs in the dataset, causing the model to overfit and ultimately reducing its performance. To address this problem, we propose the Noise-aware Contrastive Learning for CIR (NCL-CIR), comprising two key components: the Weight Compensation Block (WCB) and the Noise-pair Filter Block (NFB). The WCB coupled with diverse weight maps can ensure more stable token representations of multi-modal queries and target images. Meanwhile, the NFB, in conjunction with the Gaussian Mixture Model (GMM) predicts noise pairs by evaluating loss distributions, and generates soft labels correspondingly, allowing for the design of the soft-label based Noise Contrastive Estimation (NCE) loss function. Consequently, the overall architecture helps to mitigate the influence of mismatched and partially matched samples, with experimental results demonstrating that NCL-CIR achieves exceptional performance on the benchmark datasets.
BitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Sep 25, 2024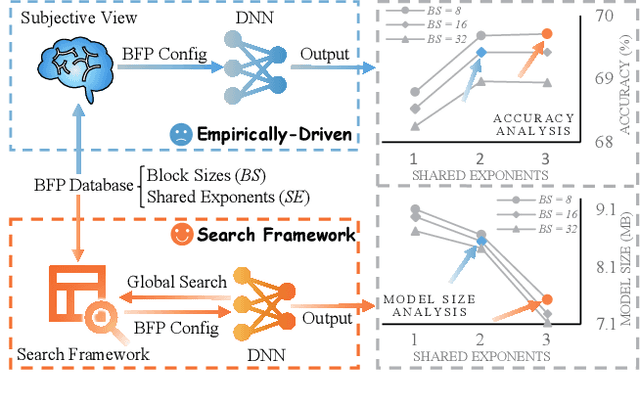
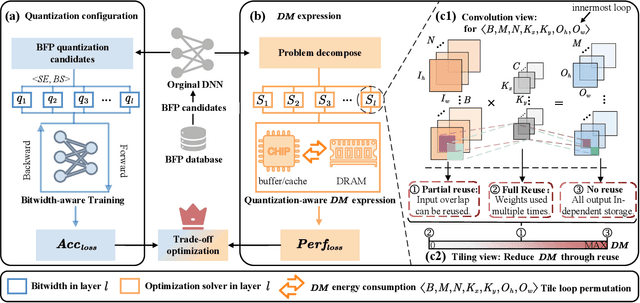

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.
Dynamic Identity-Guided Attention Network for Visible-Infrared Person Re-identification
May 21, 2024



Visible-infrared person re-identification (VI-ReID) aims to match people with the same identity between visible and infrared modalities. VI-ReID is a challenging task due to the large differences in individual appearance under different modalities. Existing methods generally try to bridge the cross-modal differences at image or feature level, which lacks exploring the discriminative embeddings. Effectively minimizing these cross-modal discrepancies relies on obtaining representations that are guided by identity and consistent across modalities, while also filtering out representations that are irrelevant to identity. To address these challenges, we introduce a dynamic identity-guided attention network (DIAN) to mine identity-guided and modality-consistent embeddings, facilitating effective bridging the gap between different modalities. Specifically, in DIAN, to pursue a semantically richer representation, we first use orthogonal projection to fuse the features from two connected coarse and fine layers. Furthermore, we first use dynamic convolution kernels to mine identity-guided and modality-consistent representations. More notably, a cross embedding balancing loss is introduced to effectively bridge cross-modal discrepancies by above embeddings. Experimental results on SYSU-MM01 and RegDB datasets show that DIAN achieves state-of-the-art performance. Specifically, for indoor search on SYSU-MM01, our method achieves 86.28% rank-1 accuracy and 87.41% mAP, respectively. Our code will be available soon.
LSROM: Learning Self-Refined Organizing Map for Fast Imbalanced Streaming Data Clustering
Apr 14, 2024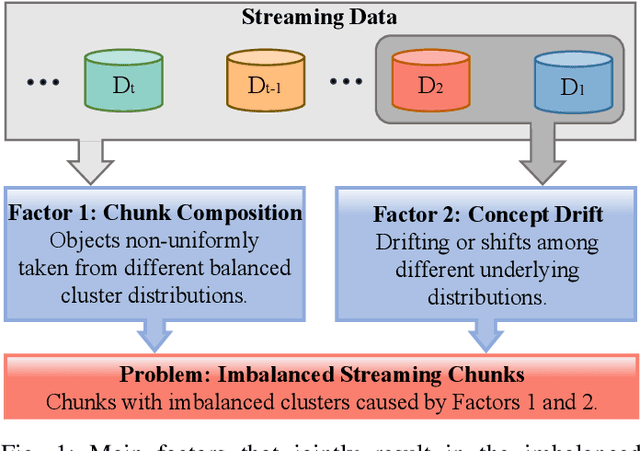
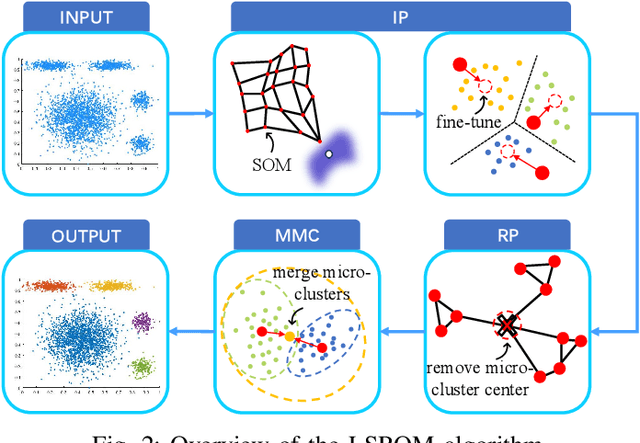

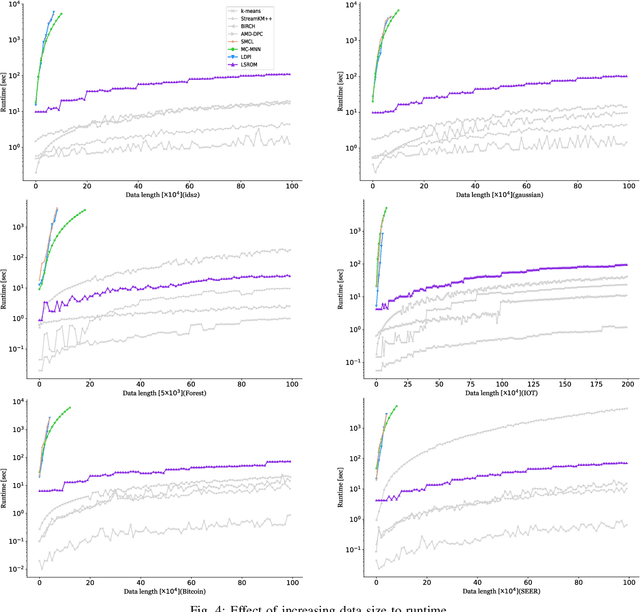
Streaming data clustering is a popular research topic in the fields of data mining and machine learning. Compared to static data, streaming data, which is usually analyzed in data chunks, is more susceptible to encountering the dynamic cluster imbalanced issue. That is, the imbalanced degree of clusters varies in different streaming data chunks, leading to corruption in either the accuracy or the efficiency of streaming data analysis based on existing clustering methods. Therefore, we propose an efficient approach called Learning Self-Refined Organizing Map (LSROM) to handle the imbalanced streaming data clustering problem, where we propose an advanced SOM for representing the global data distribution. The constructed SOM is first refined for guiding the partition of the dataset to form many micro-clusters to avoid the missing small clusters in imbalanced data. Then an efficient merging of the micro-clusters is conducted through quick retrieval based on the SOM, which can automatically yield a true number of imbalanced clusters. In comparison to existing imbalanced data clustering approaches, LSROM is with a lower time complexity $O(n\log n)$, while achieving very competitive clustering accuracy. Moreover, LSROM is interpretable and insensitive to hyper-parameters. Extensive experiments have verified its efficacy.