 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Sep 25, 2024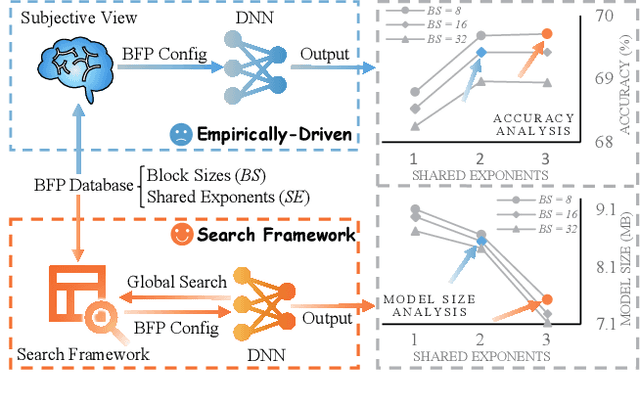
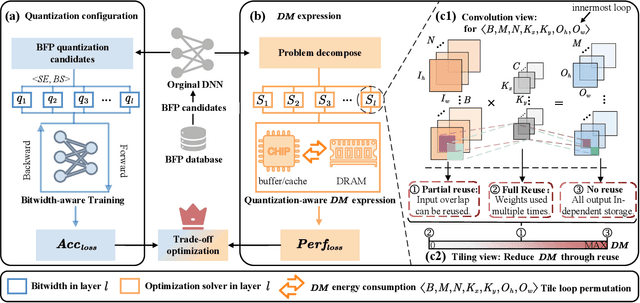

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.
MV-ROPE: Multi-view Constraints for Robust Category-level Object Pose and Size Estimation
Aug 17, 2023



We propose a novel framework for RGB-based category-level 6D object pose and size estimation. Our approach relies on the prediction of normalized object coordinate space (NOCS), which serves as an efficient and effective object canonical representation that can be extracted from RGB images. Unlike previous approaches that heavily relied on additional depth readings as input, our novelty lies in leveraging multi-view information, which is commonly available in practical scenarios where a moving camera continuously observes the environment. By introducing multi-view constraints, we can obtain accurate camera pose and depth estimation from a monocular dense SLAM framework. Additionally, by incorporating constraints on the camera relative pose, we can apply trimming strategies and robust pose averaging on the multi-view object poses, resulting in more accurate and robust estimations of category-level object poses even in the absence of direct depth readings. Furthermore, we introduce a novel NOCS prediction network that significantly improves performance. Our experimental results demonstrate the strong performance of our proposed method, even comparable to state-of-the-art RGB-D methods across public dataset sequences. Additionally, we showcase the generalization ability of our method by evaluating it on self-collected datasets.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Modeling Multimodal Aleatoric Uncertainty in Segmentation with Mixture of Stochastic Expert
Dec 14, 2022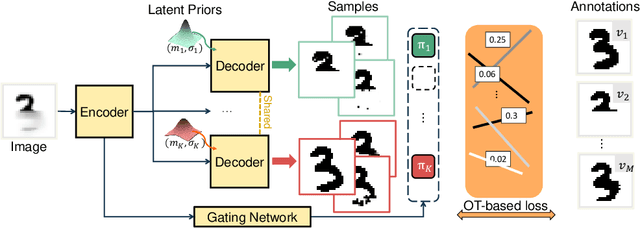

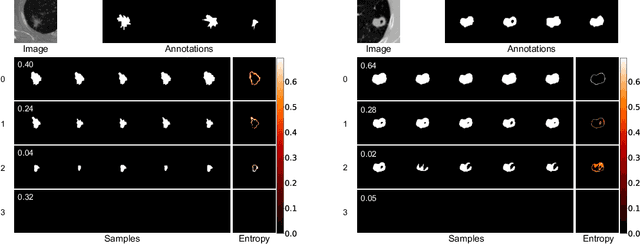

Equipping predicted segmentation with calibrated uncertainty is essential for safety-critical applications. In this work, we focus on capturing the data-inherent uncertainty (aka aleatoric uncertainty) in segmentation, typically when ambiguities exist in input images. Due to the high-dimensional output space and potential multiple modes in segmenting ambiguous images, it remains challenging to predict well-calibrated uncertainty for segmentation. To tackle this problem, we propose a novel mixture of stochastic experts (MoSE) model, where each expert network estimates a distinct mode of the aleatoric uncertainty and a gating network predicts the probabilities of an input image being segmented in those modes. This yields an efficient two-level uncertainty representation. To learn the model, we develop a Wasserstein-like loss that directly minimizes the distribution distance between the MoSE and ground truth annotations. The loss can easily integrate traditional segmentation quality measures and be efficiently optimized via constraint relaxation. We validate our method on the LIDC-IDRI dataset and a modified multimodal Cityscapes dataset. Results demonstrate that our method achieves the state-of-the-art or competitive performance on all metrics.