 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Paper and Code
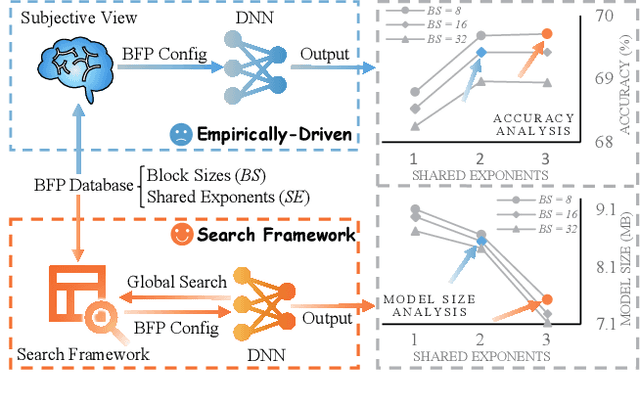
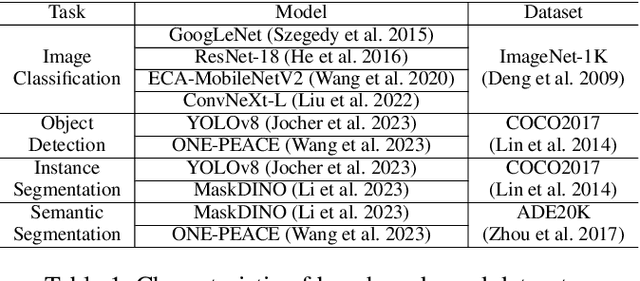
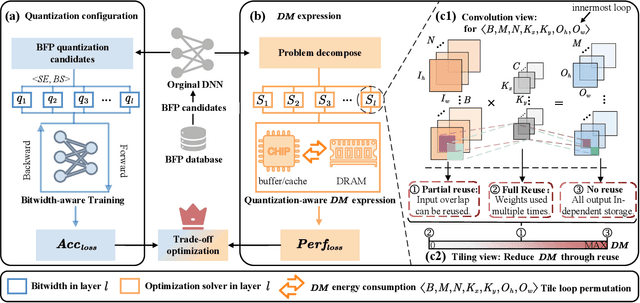

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.