 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Sep 25, 2024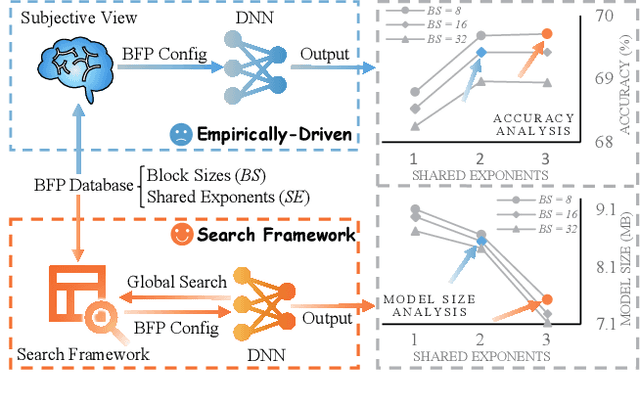
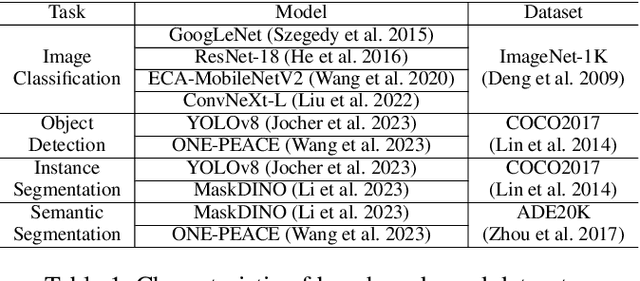
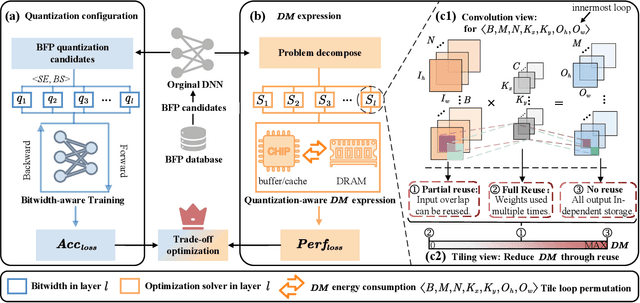

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.
Learning to Discover Knowledge: A Weakly-Supervised Partial Domain Adaptation Approach
Jun 20, 2024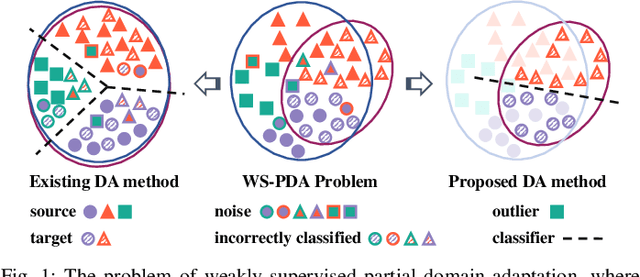



Domain adaptation has shown appealing performance by leveraging knowledge from a source domain with rich annotations. However, for a specific target task, it is cumbersome to collect related and high-quality source domains. In real-world scenarios, large-scale datasets corrupted with noisy labels are easy to collect, stimulating a great demand for automatic recognition in a generalized setting, i.e., weakly-supervised partial domain adaptation (WS-PDA), which transfers a classifier from a large source domain with noises in labels to a small unlabeled target domain. As such, the key issues of WS-PDA are: 1) how to sufficiently discover the knowledge from the noisy labeled source domain and the unlabeled target domain, and 2) how to successfully adapt the knowledge across domains. In this paper, we propose a simple yet effective domain adaptation approach, termed as self-paced transfer classifier learning (SP-TCL), to address the above issues, which could be regarded as a well-performing baseline for several generalized domain adaptation tasks. The proposed model is established upon the self-paced learning scheme, seeking a preferable classifier for the target domain. Specifically, SP-TCL learns to discover faithful knowledge via a carefully designed prudent loss function and simultaneously adapts the learned knowledge to the target domain by iteratively excluding source examples from training under the self-paced fashion. Extensive evaluations on several benchmark datasets demonstrate that SP-TCL significantly outperforms state-of-the-art approaches on several generalized domain adaptation tasks.