 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIFT Planner: Speedy Hybrid Iterative Field and Segmented Trajectory Optimization with IKD-tree for Uniform Lightweight Coverage
Dec 14, 2024


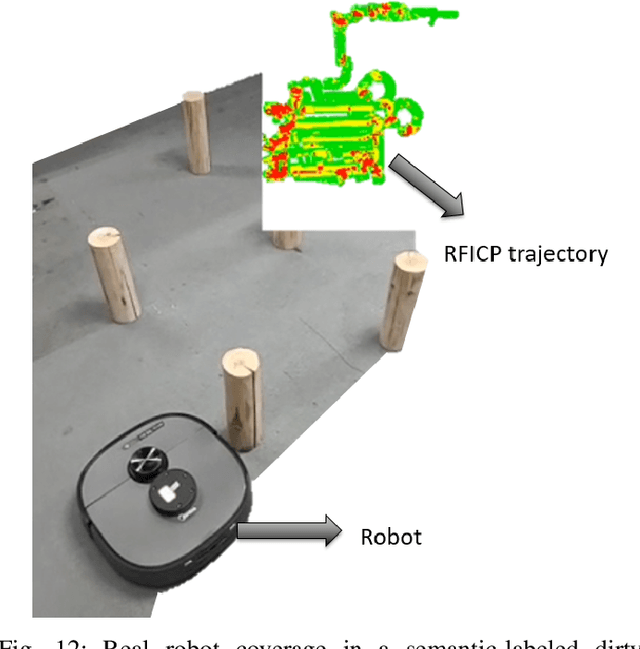
This paper introduces a comprehensive planning and navigation framework that address these limitations by integrating semantic mapping, adaptive coverage planning, dynamic obstacle avoidance and precise trajectory tracking. Our framework begins by generating panoptic occupancy local semantic maps and accurate localization information from data aligned between a monocular camera, IMU, and GPS. This information is combined with input terrain point clouds or preloaded terrain information to initialize the planning process. We propose the Radiant Field-Informed Coverage Planning algorithm, which utilizes a diffusion field model to dynamically adjust the robot's coverage trajectory and speed based on environmental attributes such as dirtiness and dryness. By modeling the spatial influence of the robot's actions using a Gaussian field, ensures a speed-optimized, uniform coverage trajectory while adapting to varying environmental conditions.
MV-ROPE: Multi-view Constraints for Robust Category-level Object Pose and Size Estimation
Aug 17, 2023



We propose a novel framework for RGB-based category-level 6D object pose and size estimation. Our approach relies on the prediction of normalized object coordinate space (NOCS), which serves as an efficient and effective object canonical representation that can be extracted from RGB images. Unlike previous approaches that heavily relied on additional depth readings as input, our novelty lies in leveraging multi-view information, which is commonly available in practical scenarios where a moving camera continuously observes the environment. By introducing multi-view constraints, we can obtain accurate camera pose and depth estimation from a monocular dense SLAM framework. Additionally, by incorporating constraints on the camera relative pose, we can apply trimming strategies and robust pose averaging on the multi-view object poses, resulting in more accurate and robust estimations of category-level object poses even in the absence of direct depth readings. Furthermore, we introduce a novel NOCS prediction network that significantly improves performance. Our experimental results demonstrate the strong performance of our proposed method, even comparable to state-of-the-art RGB-D methods across public dataset sequences. Additionally, we showcase the generalization ability of our method by evaluating it on self-collected datasets.
Scale jump-aware pose graph relaxation for monocular SLAM with re-initializations
Jul 23, 2023Pose graph relaxation has become an indispensable addition to SLAM enabling efficient global registration of sensor reference frames under the objective of satisfying pair-wise relative transformation constraints. The latter may be given by incremental motion estimation or global place recognition. While the latter case enables loop closures and drift compensation, care has to be taken in the monocular case in which local estimates of structure and displacements can differ from reality not just in terms of noise, but also in terms of a scale factor. Owing to the accumulation of scale propagation errors, this scale factor is drifting over time, hence scale-drift aware pose graph relaxation has been introduced. We extend this idea to cases in which the relative scale between subsequent sensor frames is unknown, a situation that can easily occur if monocular SLAM enters re-initialization and no reliable overlap between successive local maps can be identified. The approach is realized by a hybrid pose graph formulation that combines the regular similarity consistency terms with novel, scale-blind constraints. We apply the technique to the practically relevant case of small indoor service robots capable of effectuating purely rotational displacements, a condition that can easily cause tracking failures. We demonstrate that globally consistent trajectories can be recovered even if multiple re-initializations occur along the loop, and present an in-depth study of success and failure cases.
Spotlights: Probing Shapes from Spherical Viewpoints
May 25, 2022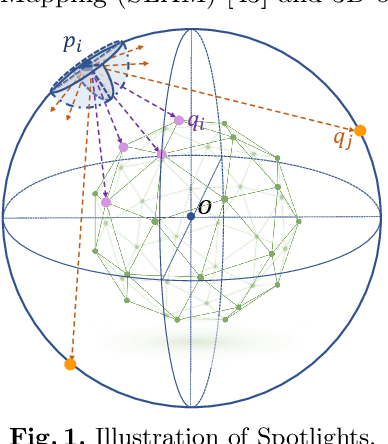
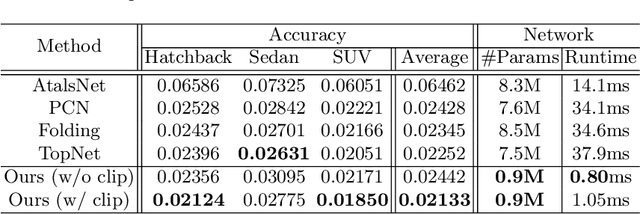
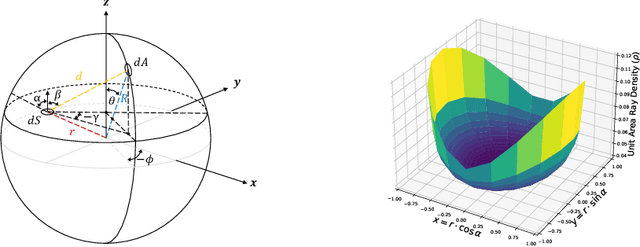
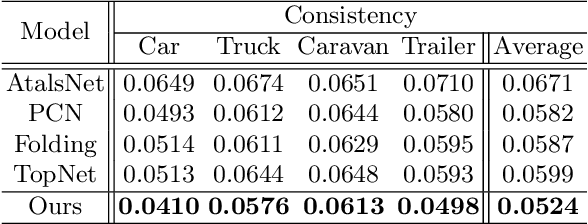
Recent years have witnessed the surge of learned representations that directly build upon point clouds. Though becoming increasingly expressive, most existing representations still struggle to generate ordered point sets. Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. The structured point cloud is hence given implicitly as a function of depths. We provide a detailed geometric analysis of this new sampling scheme and prove its effectiveness in the context of the point cloud completion task. Experimental results on both synthetic and real data demonstrate that our method achieves competitive accuracy and consistency while having a significantly reduced computational cost. Furthermore, we show superior performance on the downstream point cloud registration task over state-of-the-art completion methods.
S3E-GNN: Sparse Spatial Scene Embedding with Graph Neural Networks for Camera Relocalization
May 12, 2022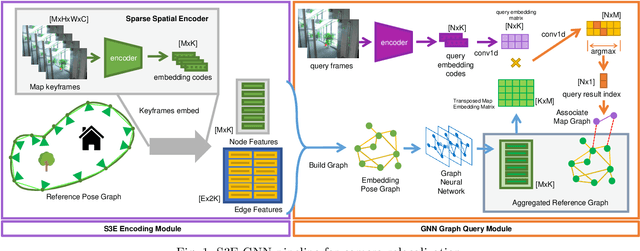
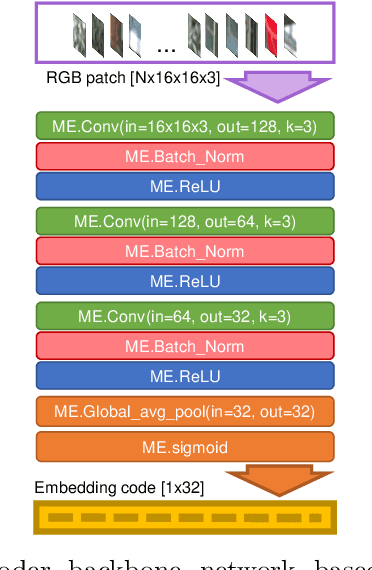
Camera relocalization is the key component of simultaneous localization and mapping (SLAM) systems. This paper proposes a learning-based approach, named Sparse Spatial Scene Embedding with Graph Neural Networks (S3E-GNN), as an end-to-end framework for efficient and robust camera relocalization. S3E-GNN consists of two modules. In the encoding module, a trained S3E network encodes RGB images into embedding codes to implicitly represent spatial and semantic embedding code. With embedding codes and the associated poses obtained from a SLAM system, each image is represented as a graph node in a pose graph. In the GNN query module, the pose graph is transformed to form a embedding-aggregated reference graph for camera relocalization. We collect various scene datasets in the challenging environments to perform experiments. Our results demonstrate that S3E-GNN method outperforms the traditional Bag-of-words (BoW) for camera relocalization due to learning-based embedding and GNN powered scene matching mechanism.