 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Categorical Data Clustering Guided by Multi-Granular Competitive Learning
Jan 23, 2026Data set composed of categorical features is very common in big data analysis tasks. Since categorical features are usually with a limited number of qualitative possible values, the nested granular cluster effect is prevalent in the implicit discrete distance space of categorical data. That is, data objects frequently overlap in space or subspace to form small compact clusters, and similar small clusters often form larger clusters. However, the distance space cannot be well-defined like the Euclidean distance due to the qualitative categorical data values, which brings great challenges to the cluster analysis of categorical data. In view of this, we design a Multi-Granular Competitive Penalization Learning (MGCPL) algorithm to allow potential clusters to interactively tune themselves and converge in stages with different numbers of naturally compact clusters. To leverage MGCPL, we also propose a Cluster Aggregation strategy based on MGCPL Encoding (CAME) to first encode the data objects according to the learned multi-granular distributions, and then perform final clustering on the embeddings. It turns out that the proposed MGCPL-guided Categorical Data Clustering (MCDC) approach is competent in automatically exploring the nested distribution of multi-granular clusters and highly robust to categorical data sets from various domains. Benefiting from its linear time complexity, MCDC is scalable to large-scale data sets and promising in pre-partitioning data sets or compute nodes for boosting distributed computing. Extensive experiments with statistical evidence demonstrate its superiority compared to state-of-the-art counterparts on various real public data sets.
* This paper has been published in the IEEE International Conference on Distributed Computing Systems (ICDCS 2024)
One-Shot Hierarchical Federated Clustering
Jan 10, 2026Driven by the growth of Web-scale decentralized services, Federated Clustering (FC) aims to extract knowledge from heterogeneous clients in an unsupervised manner while preserving the clients' privacy, which has emerged as a significant challenge due to the lack of label guidance and the Non-Independent and Identically Distributed (non-IID) nature of clients. In real scenarios such as personalized recommendation and cross-device user profiling, the global cluster may be fragmented and distributed among different clients, and the clusters may exist at different granularities or even nested. Although Hierarchical Clustering (HC) is considered promising for exploring such distributions, the sophisticated recursive clustering process makes it more computationally expensive and vulnerable to privacy exposure, thus relatively unexplored under the federated learning scenario. This paper introduces an efficient one-shot hierarchical FC framework that performs client-end distribution exploration and server-end distribution aggregation through one-way prototype-level communication from clients to the server. A fine partition mechanism is developed to generate successive clusterlets to describe the complex landscape of the clients' clusters. Then, a multi-granular learning mechanism on the server is proposed to fuse the clusterlets, even when they have inconsistent granularities generated from different clients. It turns out that the complex cluster distributions across clients can be efficiently explored, and extensive experiments comparing state-of-the-art methods on ten public datasets demonstrate the superiority of the proposed method.
Evo-TFS: Evolutionary Time-Frequency Domain-Based Synthetic Minority Oversampling Approach to Imbalanced Time Series Classification
Jan 03, 2026Time series classification is a fundamental machine learning task with broad real-world applications. Although many deep learning methods have proven effective in learning time-series data for classification, they were originally developed under the assumption of balanced data distributions. Once data distribution is uneven, these methods tend to ignore the minority class that is typically of higher practical significance. Oversampling methods have been designed to address this by generating minority-class samples, but their reliance on linear interpolation often hampers the preservation of temporal dynamics and the generation of diverse samples. Therefore, in this paper, we propose Evo-TFS, a novel evolutionary oversampling method that integrates both time- and frequency-domain characteristics. In Evo-TFS, strongly typed genetic programming is employed to evolve diverse, high-quality time series, guided by a fitness function that incorporates both time-domain and frequency-domain characteristics. Experiments conducted on imbalanced time series datasets demonstrate that Evo-TFS outperforms existing oversampling methods, significantly enhancing the performance of time-domain and frequency-domain classifiers.
EvoSampling: A Granular Ball-based Evolutionary Hybrid Sampling with Knowledge Transfer for Imbalanced Learning
Dec 12, 2024



Class imbalance would lead to biased classifiers that favor the majority class and disadvantage the minority class. Unfortunately, from a practical perspective, the minority class is of importance in many real-life applications. Hybrid sampling methods address this by oversampling the minority class to increase the number of its instances, followed by undersampling to remove low-quality instances. However, most existing sampling methods face difficulties in generating diverse high-quality instances and often fail to remove noise or low-quality instances on a larger scale effectively. This paper therefore proposes an evolutionary multi-granularity hybrid sampling method, called EvoSampling. During the oversampling process, genetic programming (GP) is used with multi-task learning to effectively and efficiently generate diverse high-quality instances. During the undersampling process, we develop a granular ball-based undersampling method that removes noise in a multi-granular fashion, thereby enhancing data quality. Experiments on 20 imbalanced datasets demonstrate that EvoSampling effectively enhances the performance of various classification algorithms by providing better datasets than existing sampling methods. Besides, ablation studies further indicate that allowing knowledge transfer accelerates the GP's evolutionary learning process.
LSROM: Learning Self-Refined Organizing Map for Fast Imbalanced Streaming Data Clustering
Apr 14, 2024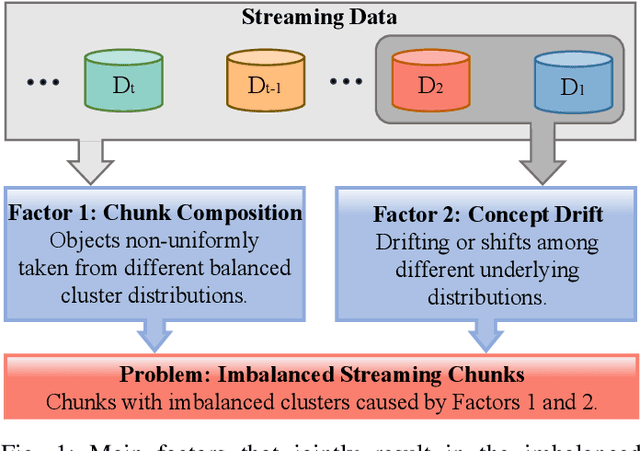
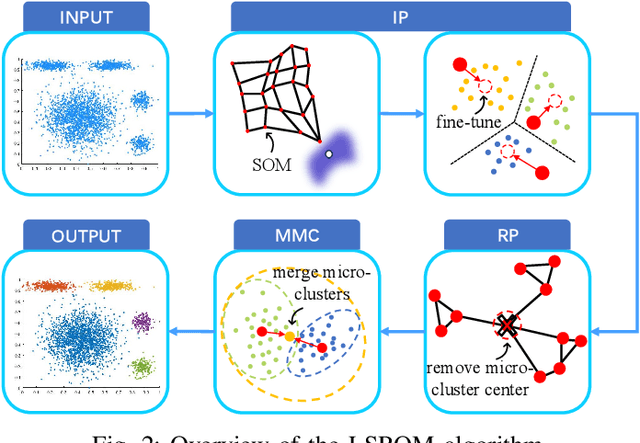

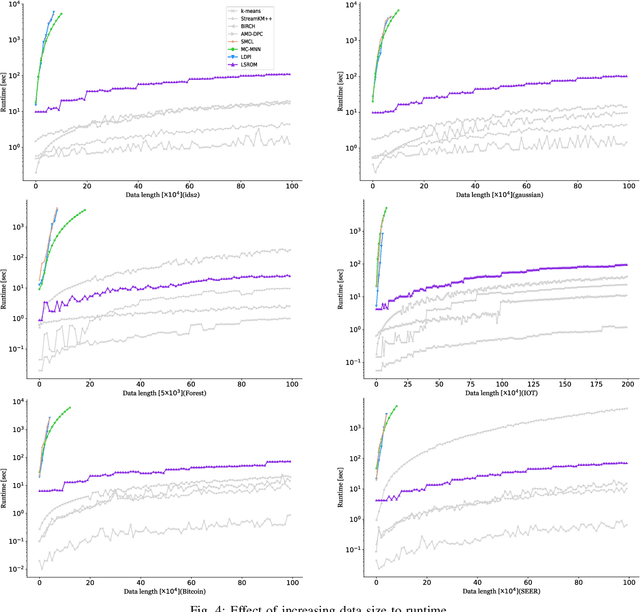
Streaming data clustering is a popular research topic in the fields of data mining and machine learning. Compared to static data, streaming data, which is usually analyzed in data chunks, is more susceptible to encountering the dynamic cluster imbalanced issue. That is, the imbalanced degree of clusters varies in different streaming data chunks, leading to corruption in either the accuracy or the efficiency of streaming data analysis based on existing clustering methods. Therefore, we propose an efficient approach called Learning Self-Refined Organizing Map (LSROM) to handle the imbalanced streaming data clustering problem, where we propose an advanced SOM for representing the global data distribution. The constructed SOM is first refined for guiding the partition of the dataset to form many micro-clusters to avoid the missing small clusters in imbalanced data. Then an efficient merging of the micro-clusters is conducted through quick retrieval based on the SOM, which can automatically yield a true number of imbalanced clusters. In comparison to existing imbalanced data clustering approaches, LSROM is with a lower time complexity $O(n\log n)$, while achieving very competitive clustering accuracy. Moreover, LSROM is interpretable and insensitive to hyper-parameters. Extensive experiments have verified its efficacy.
Trustworthy Partial Label Learning with Out-of-distribution Detection
Mar 11, 2024Partial Label Learning (PLL) grapples with learning from ambiguously labelled data, and it has been successfully applied in fields such as image recognition. Nevertheless, traditional PLL methods rely on the closed-world assumption, which can be limiting in open-world scenarios and negatively impact model performance and generalization. To tackle these challenges, our study introduces a novel method called PLL-OOD, which is the first to incorporate Out-of-Distribution (OOD) detection into the PLL framework. PLL-OOD significantly enhances model adaptability and accuracy by merging self-supervised learning with partial label loss and pioneering the Partial-Energy (PE) score for OOD detection. This approach improves data feature representation and effectively disambiguates candidate labels, using a dynamic label confidence matrix to refine predictions. The PE score, adjusted by label confidence, precisely identifies OOD instances, optimizing model training towards in-distribution data. This innovative method markedly boosts PLL model robustness and performance in open-world settings. To validate our approach, we conducted a comprehensive comparative experiment combining the existing state-of-the-art PLL model with multiple OOD scores on the CIFAR-10 and CIFAR-100 datasets with various OOD datasets. The results demonstrate that the proposed PLL-OOD framework is highly effective and effectiveness outperforms existing models, showcasing its superiority and effectiveness.
Enhancing the Performance of Neural Networks Through Causal Discovery and Integration of Domain Knowledge
Dec 01, 2023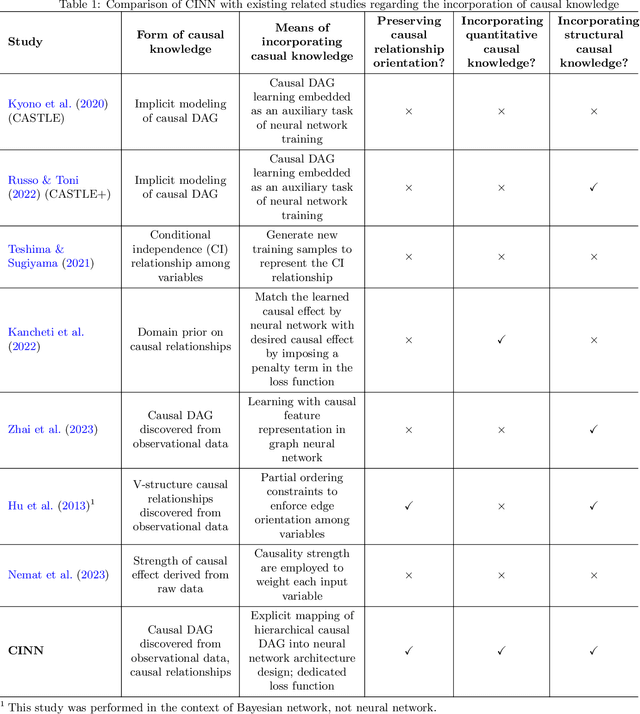
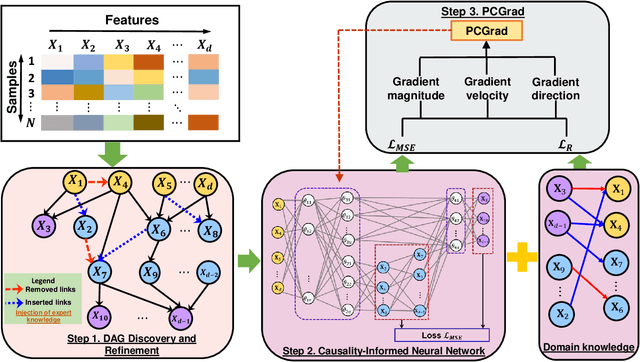
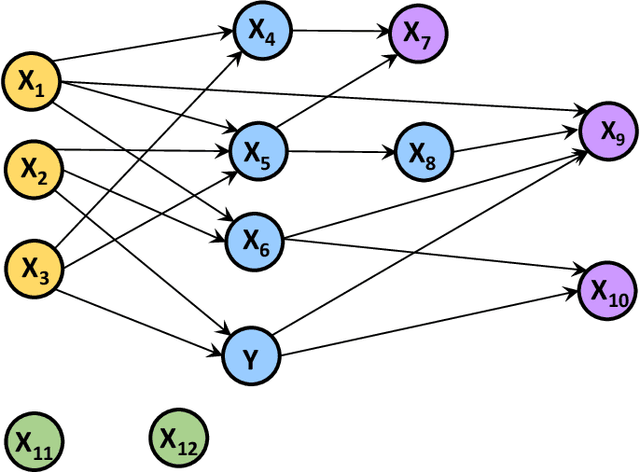

In this paper, we develop a generic methodology to encode hierarchical causality structure among observed variables into a neural network in order to improve its predictive performance. The proposed methodology, called causality-informed neural network (CINN), leverages three coherent steps to systematically map the structural causal knowledge into the layer-to-layer design of neural network while strictly preserving the orientation of every causal relationship. In the first step, CINN discovers causal relationships from observational data via directed acyclic graph (DAG) learning, where causal discovery is recast as a continuous optimization problem to avoid the combinatorial nature. In the second step, the discovered hierarchical causality structure among observed variables is systematically encoded into neural network through a dedicated architecture and customized loss function. By categorizing variables in the causal DAG as root, intermediate, and leaf nodes, the hierarchical causal DAG is translated into CINN with a one-to-one correspondence between nodes in the causal DAG and units in the CINN while maintaining the relative order among these nodes. Regarding the loss function, both intermediate and leaf nodes in the DAG graph are treated as target outputs during CINN training so as to drive co-learning of causal relationships among different types of nodes. As multiple loss components emerge in CINN, we leverage the projection of conflicting gradients to mitigate gradient interference among the multiple learning tasks. Computational experiments across a broad spectrum of UCI data sets demonstrate substantial advantages of CINN in predictive performance over other state-of-the-art methods. In addition, an ablation study underscores the value of integrating structural and quantitative causal knowledge in enhancing the neural network's predictive performance incrementally.