 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-TFS: Evolutionary Time-Frequency Domain-Based Synthetic Minority Oversampling Approach to Imbalanced Time Series Classification
Jan 03, 2026Time series classification is a fundamental machine learning task with broad real-world applications. Although many deep learning methods have proven effective in learning time-series data for classification, they were originally developed under the assumption of balanced data distributions. Once data distribution is uneven, these methods tend to ignore the minority class that is typically of higher practical significance. Oversampling methods have been designed to address this by generating minority-class samples, but their reliance on linear interpolation often hampers the preservation of temporal dynamics and the generation of diverse samples. Therefore, in this paper, we propose Evo-TFS, a novel evolutionary oversampling method that integrates both time- and frequency-domain characteristics. In Evo-TFS, strongly typed genetic programming is employed to evolve diverse, high-quality time series, guided by a fitness function that incorporates both time-domain and frequency-domain characteristics. Experiments conducted on imbalanced time series datasets demonstrate that Evo-TFS outperforms existing oversampling methods, significantly enhancing the performance of time-domain and frequency-domain classifiers.
HWL-HIN: A Hypergraph-Level Hypergraph Isomorphism Network as Powerful as the Hypergraph Weisfeiler-Lehman Test with Application to Higher-Order Network Robustness
Dec 26, 2025Robustness in complex systems is of significant engineering and economic importance. However, conventional attack-based a posteriori robustness assessments incur prohibitive computational overhead. Recently, deep learning methods, such as Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs), have been widely employed as surrogates for rapid robustness prediction. Nevertheless, these methods neglect the complex higher-order correlations prevalent in real-world systems, which are naturally modeled as hypergraphs. Although Hypergraph Neural Networks (HGNNs) have been widely adopted for hypergraph learning, their topological expressive power has not yet reached the theoretical upper bound. To address this limitation, inspired by Graph Isomorphism Networks, this paper proposes a hypergraph-level Hypergraph Isomorphism Network framework. Theoretically, this approach is proven to possess an expressive power strictly equivalent to the Hypergraph Weisfeiler-Lehman test and is applied to predict hypergraph robustness. Experimental results demonstrate that while maintaining superior efficiency in training and prediction, the proposed method not only outperforms existing graph-based models but also significantly surpasses conventional HGNNs in tasks that prioritize topological structure representation.
Federated Unlearning Model Recovery in Data with Skewed Label Distributions
Dec 18, 2024

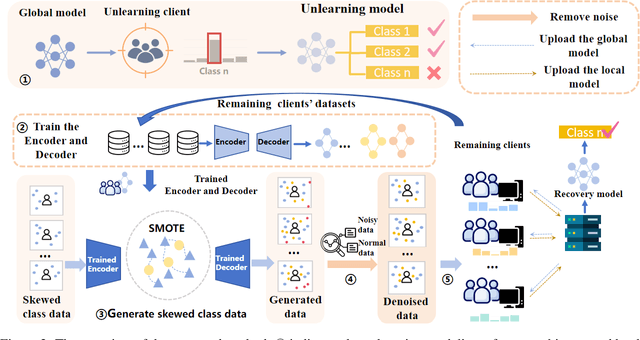

In federated learning, federated unlearning is a technique that provides clients with a rollback mechanism that allows them to withdraw their data contribution without training from scratch. However, existing research has not considered scenarios with skewed label distributions. Unfortunately, the unlearning of a client with skewed data usually results in biased models and makes it difficult to deliver high-quality service, complicating the recovery process. This paper proposes a recovery method of federated unlearning with skewed label distributions. Specifically, we first adopt a strategy that incorporates oversampling with deep learning to supplement the skewed class data for clients to perform recovery training, therefore enhancing the completeness of their local datasets. Afterward, a density-based denoising method is applied to remove noise from the generated data, further improving the quality of the remaining clients' datasets. Finally, all the remaining clients leverage the enhanced local datasets and engage in iterative training to effectively restore the performance of the unlearning model. Extensive evaluations on commonly used federated learning datasets with varying degrees of skewness show that our method outperforms baseline methods in restoring the performance of the unlearning model, particularly regarding accuracy on the skewed class.
EvoSampling: A Granular Ball-based Evolutionary Hybrid Sampling with Knowledge Transfer for Imbalanced Learning
Dec 12, 2024



Class imbalance would lead to biased classifiers that favor the majority class and disadvantage the minority class. Unfortunately, from a practical perspective, the minority class is of importance in many real-life applications. Hybrid sampling methods address this by oversampling the minority class to increase the number of its instances, followed by undersampling to remove low-quality instances. However, most existing sampling methods face difficulties in generating diverse high-quality instances and often fail to remove noise or low-quality instances on a larger scale effectively. This paper therefore proposes an evolutionary multi-granularity hybrid sampling method, called EvoSampling. During the oversampling process, genetic programming (GP) is used with multi-task learning to effectively and efficiently generate diverse high-quality instances. During the undersampling process, we develop a granular ball-based undersampling method that removes noise in a multi-granular fashion, thereby enhancing data quality. Experiments on 20 imbalanced datasets demonstrate that EvoSampling effectively enhances the performance of various classification algorithms by providing better datasets than existing sampling methods. Besides, ablation studies further indicate that allowing knowledge transfer accelerates the GP's evolutionary learning process.
UmambaTSF: A U-shaped Multi-Scale Long-Term Time Series Forecasting Method Using Mamba
Oct 15, 2024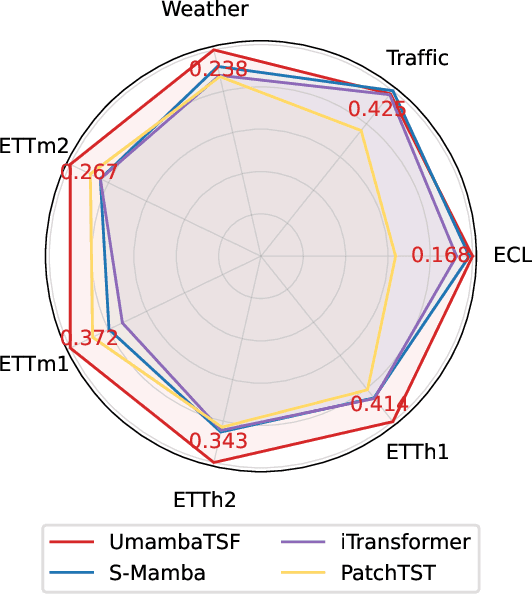
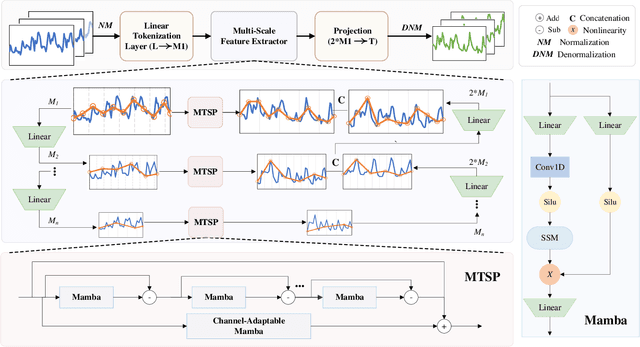
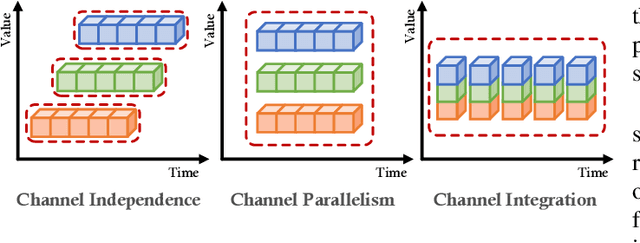
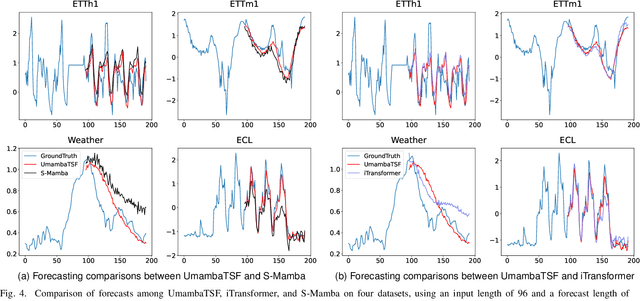
Multivariate Time series forecasting is crucial in domains such as transportation, meteorology, and finance, especially for predicting extreme weather events. State-of-the-art methods predominantly rely on Transformer architectures, which utilize attention mechanisms to capture temporal dependencies. However, these methods are hindered by quadratic time complexity, limiting the model's scalability with respect to input sequence length. This significantly restricts their practicality in the real world. Mamba, based on state space models (SSM), provides a solution with linear time complexity, increasing the potential for efficient forecasting of sequential data. In this study, we propose UmambaTSF, a novel long-term time series forecasting framework that integrates multi-scale feature extraction capabilities of U-shaped encoder-decoder multilayer perceptrons (MLP) with Mamba's long sequence representation. To improve performance and efficiency, the Mamba blocks introduced in the framework adopt a refined residual structure and adaptable design, enabling the capture of unique temporal signals and flexible channel processing. In the experiments, UmambaTSF achieves state-of-the-art performance and excellent generality on widely used benchmark datasets while maintaining linear time complexity and low memory consumption.
Influence Maximization in Hypergraphs Using A Genetic Algorithm with New Initialization and Evaluation Methods
May 15, 2024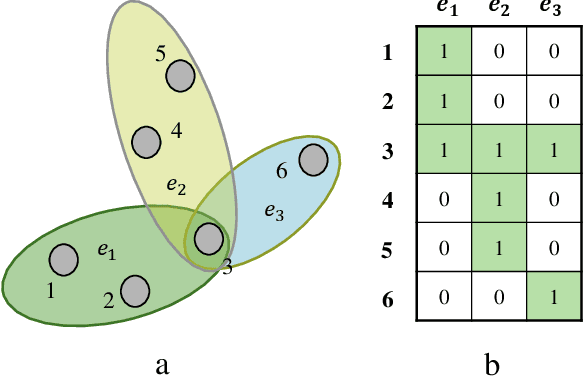
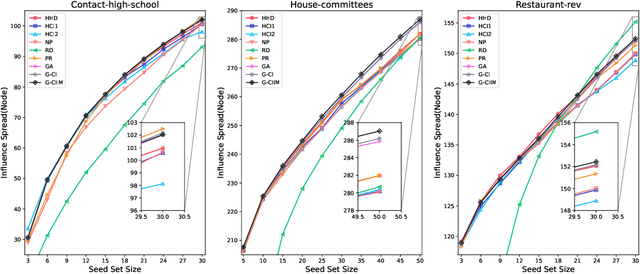
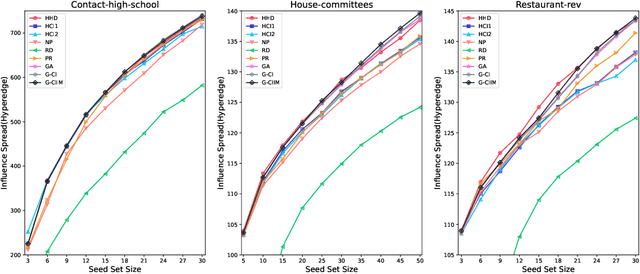
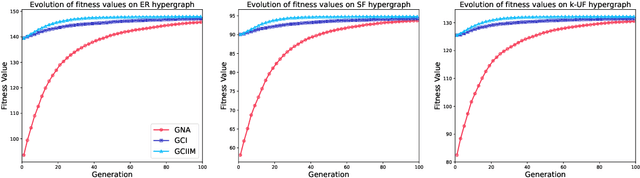
Influence maximization (IM) is a crucial optimization task related to analyzing complex networks in the real world, such as social networks, disease propagation networks, and marketing networks. Publications to date about the IM problem focus mainly on graphs, which fail to capture high-order interaction relationships from the real world. Therefore, the use of hypergraphs for addressing the IM problem has been receiving increasing attention. However, identifying the most influential nodes in hypergraphs remains challenging, mainly because nodes and hyperedges are often strongly coupled and correlated. In this paper, to effectively identify the most influential nodes, we first propose a novel hypergraph-independent cascade model that integrates the influences of both node and hyperedge failures. Afterward, we introduce genetic algorithms (GA) to identify the most influential nodes that leverage hypergraph collective influences. In the GA-based method, the hypergraph collective influence is effectively used to initialize the population, thereby enhancing the quality of initial candidate solutions. The designed fitness function considers the joint influences of both nodes and hyperedges. This ensures the optimal set of nodes with the best influence on both nodes and hyperedges to be evaluated accurately. Moreover, a new mutation operator is designed by introducing factors, i.e., the collective influence and overlapping effects of nodes in hypergraphs, to breed high-quality offspring. In the experiments, several simulations on both synthetic and real hypergraphs have been conducted, and the results demonstrate that the proposed method outperforms the compared methods.
Improving Critical Node Detection Using Neural Network-based Initialization in a Genetic Algorithm
Feb 01, 2024The Critical Node Problem (CNP) is concerned with identifying the critical nodes in a complex network. These nodes play a significant role in maintaining the connectivity of the network, and removing them can negatively impact network performance. CNP has been studied extensively due to its numerous real-world applications. Among the different versions of CNP, CNP-1a has gained the most popularity. The primary objective of CNP-1a is to minimize the pair-wise connectivity in the remaining network after deleting a limited number of nodes from a network. Due to the NP-hard nature of CNP-1a, many heuristic/metaheuristic algorithms have been proposed to solve this problem. However, most existing algorithms start with a random initialization, leading to a high cost of obtaining an optimal solution. To improve the efficiency of solving CNP-1a, a knowledge-guided genetic algorithm named K2GA has been proposed. Unlike the standard genetic algorithm framework, K2GA has two main components: a pretrained neural network to obtain prior knowledge on possible critical nodes, and a hybrid genetic algorithm with local search for finding an optimal set of critical nodes based on the knowledge given by the trained neural network. The local search process utilizes a cut node-based greedy strategy. The effectiveness of the proposed knowledgeguided genetic algorithm is verified by experiments on 26 realworld instances of complex networks. Experimental results show that K2GA outperforms the state-of-the-art algorithms regarding the best, median, and average objective values, and improves the best upper bounds on the best objective values for eight realworld instances.
Explaining Deep Convolutional Neural Networks for Image Classification by Evolving Local Interpretable Model-agnostic Explanations
Nov 28, 2022Deep convolutional neural networks have proven their effectiveness, and have been acknowledged as the most dominant method for image classification. However, a severe drawback of deep convolutional neural networks is poor explainability. Unfortunately, in many real-world applications, users need to understand the rationale behind the predictions of deep convolutional neural networks when determining whether they should trust the predictions or not. To resolve this issue, a novel genetic algorithm-based method is proposed for the first time to automatically evolve local explanations that can assist users to assess the rationality of the predictions. Furthermore, the proposed method is model-agnostic, i.e., it can be utilised to explain any deep convolutional neural network models. In the experiments, ResNet is used as an example model to be explained, and the ImageNet dataset is selected as the benchmark dataset. DenseNet and MobileNet are further explained to demonstrate the model-agnostic characteristic of the proposed method. The evolved local explanations on four images, randomly selected from ImageNet, are presented, which show that the evolved local explanations are straightforward to be recognised by humans. Moreover, the evolved explanations can explain the predictions of deep convolutional neural networks on all four images very well by successfully capturing meaningful interpretable features of the sample images. Further analysis based on the 30 runs of the experiments exhibits that the evolved local explanations can also improve the probabilities/confidences of the deep convolutional neural network models in making the predictions. The proposed method can obtain local explanations within one minute, which is more than ten times faster than LIME (the state-of-the-art method).