 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Dual-Trigger Backdoors: Attacking Prompt Tuning in LM-Empowered Graph Foundation Models
Oct 16, 2025The emergence of graph foundation models (GFMs), particularly those incorporating language models (LMs), has revolutionized graph learning and demonstrated remarkable performance on text-attributed graphs (TAGs). However, compared to traditional GNNs, these LM-empowered GFMs introduce unique security vulnerabilities during the unsecured prompt tuning phase that remain understudied in current research. Through empirical investigation, we reveal a significant performance degradation in traditional graph backdoor attacks when operating in attribute-inaccessible constrained TAG systems without explicit trigger node attribute optimization. To address this, we propose a novel dual-trigger backdoor attack framework that operates at both text-level and struct-level, enabling effective attacks without explicit optimization of trigger node text attributes through the strategic utilization of a pre-established text pool. Extensive experimental evaluations demonstrate that our attack maintains superior clean accuracy while achieving outstanding attack success rates, including scenarios with highly concealed single-trigger nodes. Our work highlights critical backdoor risks in web-deployed LM-empowered GFMs and contributes to the development of more robust supervision mechanisms for open-source platforms in the era of foundation models.
A Closer Look on Memorization in Tabular Diffusion Model: A Data-Centric Perspective
May 28, 2025Diffusion models have shown strong performance in generating high-quality tabular data, but they carry privacy risks by reproducing exact training samples. While prior work focuses on dataset-level augmentation to reduce memorization, little is known about which individual samples contribute most. We present the first data-centric study of memorization dynamics in tabular diffusion models. We quantify memorization for each real sample based on how many generated samples are flagged as replicas, using a relative distance ratio. Our empirical analysis reveals a heavy-tailed distribution of memorization counts: a small subset of samples contributes disproportionately to leakage, confirmed via sample-removal experiments. To understand this, we divide real samples into top- and non-top-memorized groups and analyze their training-time behaviors. We track when each sample is first memorized and monitor per-epoch memorization intensity (AUC). Memorized samples are memorized slightly earlier and show stronger signals in early training. Based on these insights, we propose DynamicCut, a two-stage, model-agnostic mitigation method: (a) rank samples by epoch-wise intensity, (b) prune a tunable top fraction, and (c) retrain on the filtered dataset. Across multiple tabular datasets and models, DynamicCut reduces memorization with minimal impact on data diversity and downstream performance. It also complements augmentation-based defenses. Furthermore, DynamicCut enables cross-model transferability: high-ranked samples identified from one model (e.g., a diffusion model) are also effective for reducing memorization when removed from others, such as GANs and VAEs.
Dual-Modality Representation Learning for Molecular Property Prediction
Jan 11, 2025


Molecular property prediction has attracted substantial attention recently. Accurate prediction of drug properties relies heavily on effective molecular representations. The structures of chemical compounds are commonly represented as graphs or SMILES sequences. Recent advances in learning drug properties commonly employ Graph Neural Networks (GNNs) based on the graph representation. For the SMILES representation, Transformer-based architectures have been adopted by treating each SMILES string as a sequence of tokens. Because each representation has its own advantages and disadvantages, combining both representations in learning drug properties is a promising direction. We propose a method named Dual-Modality Cross-Attention (DMCA) that can effectively combine the strengths of two representations by employing the cross-attention mechanism. DMCA was evaluated across eight datasets including both classification and regression tasks. Results show that our method achieves the best overall performance, highlighting its effectiveness in leveraging the complementary information from both graph and SMILES modalities.
Implementing Trust in Non-Small Cell Lung Cancer Diagnosis with a Conformalized Uncertainty-Aware AI Framework in Whole-Slide Images
Dec 28, 2024Ensuring trustworthiness is fundamental to the development of artificial intelligence (AI) that is considered societally responsible, particularly in cancer diagnostics, where a misdiagnosis can have dire consequences. Current digital pathology AI models lack systematic solutions to address trustworthiness concerns arising from model limitations and data discrepancies between model deployment and development environments. To address this issue, we developed TRUECAM, a framework designed to ensure both data and model trustworthiness in non-small cell lung cancer subtyping with whole-slide images. TRUECAM integrates 1) a spectral-normalized neural Gaussian process for identifying out-of-scope inputs and 2) an ambiguity-guided elimination of tiles to filter out highly ambiguous regions, addressing data trustworthiness, as well as 3) conformal prediction to ensure controlled error rates. We systematically evaluated the framework across multiple large-scale cancer datasets, leveraging both task-specific and foundation models, illustrate that an AI model wrapped with TRUECAM significantly outperforms models that lack such guidance, in terms of classification accuracy, robustness, interpretability, and data efficiency, while also achieving improvements in fairness. These findings highlight TRUECAM as a versatile wrapper framework for digital pathology AI models with diverse architectural designs, promoting their responsible and effective applications in real-world settings.
Decoupled Sparse Priors Guided Diffusion Compression Model for Point Clouds
Nov 21, 2024



Lossy compression methods rely on an autoencoder to transform a point cloud into latent points for storage, leaving the inherent redundancy of latent representations unexplored. To reduce redundancy in latent points, we propose a sparse priors guided method that achieves high reconstruction quality, especially at high compression ratios. This is accomplished by a dual-density scheme separately processing the latent points (intended for reconstruction) and the decoupled sparse priors (intended for storage). Our approach features an efficient dual-density data flow that relaxes size constraints on latent points, and hybridizes a progressive conditional diffusion model to encapsulate essential details for reconstruction within the conditions, which are decoupled hierarchically to intra-point and inter-point priors. Specifically, our method encodes the original point cloud into latent points and decoupled sparse priors through separate encoders. Latent points serve as intermediates, while sparse priors act as adaptive conditions. We then employ a progressive attention-based conditional denoiser to generate latent points conditioned on the decoupled priors, allowing the denoiser to dynamically attend to geometric and semantic cues from the priors at each encoding and decoding layer. Additionally, we integrate the local distribution into the arithmetic encoder and decoder to enhance local context modeling of the sparse points. The original point cloud is reconstructed through a point decoder. Compared to state-of-the-art, our method obtains superior rate-distortion trade-off, evidenced by extensive evaluations on the ShapeNet dataset and standard test datasets from MPEG group including 8iVFB, and Owlii.
Causally-Aware Spatio-Temporal Multi-Graph Convolution Network for Accurate and Reliable Traffic Prediction
Aug 23, 2024Accurate and reliable prediction has profound implications to a wide range of applications. In this study, we focus on an instance of spatio-temporal learning problem--traffic prediction--to demonstrate an advanced deep learning model developed for making accurate and reliable forecast. Despite the significant progress in traffic prediction, limited studies have incorporated both explicit and implicit traffic patterns simultaneously to improve prediction performance. Meanwhile, the variability nature of traffic states necessitates quantifying the uncertainty of model predictions in a statistically principled way; however, extant studies offer no provable guarantee on the statistical validity of confidence intervals in reflecting its actual likelihood of containing the ground truth. In this paper, we propose an end-to-end traffic prediction framework that leverages three primary components to generate accurate and reliable traffic predictions: dynamic causal structure learning for discovering implicit traffic patterns from massive traffic data, causally-aware spatio-temporal multi-graph convolution network (CASTMGCN) for learning spatio-temporal dependencies, and conformal prediction for uncertainty quantification. CASTMGCN fuses several graphs that characterize different important aspects of traffic networks and an auxiliary graph that captures the effect of exogenous factors on the road network. On this basis, a conformal prediction approach tailored to spatio-temporal data is further developed for quantifying the uncertainty in node-wise traffic predictions over varying prediction horizons. Experimental results on two real-world traffic datasets demonstrate that the proposed method outperforms several state-of-the-art models in prediction accuracy; moreover, it generates more efficient prediction regions than other methods while strictly satisfying the statistical validity in coverage.
Enhancing the Performance of Neural Networks Through Causal Discovery and Integration of Domain Knowledge
Dec 01, 2023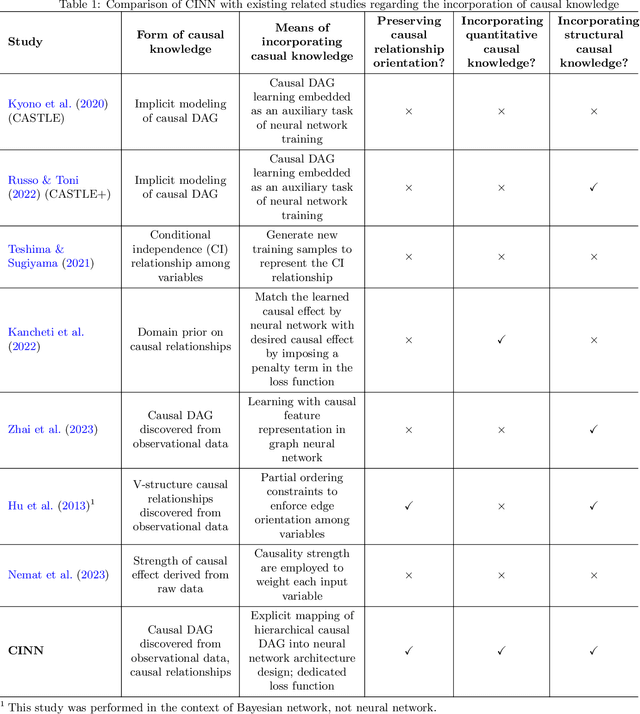
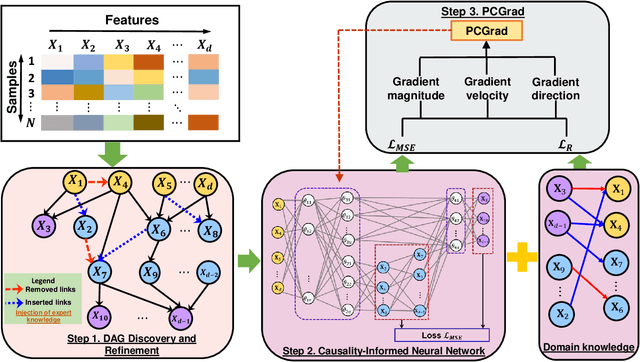
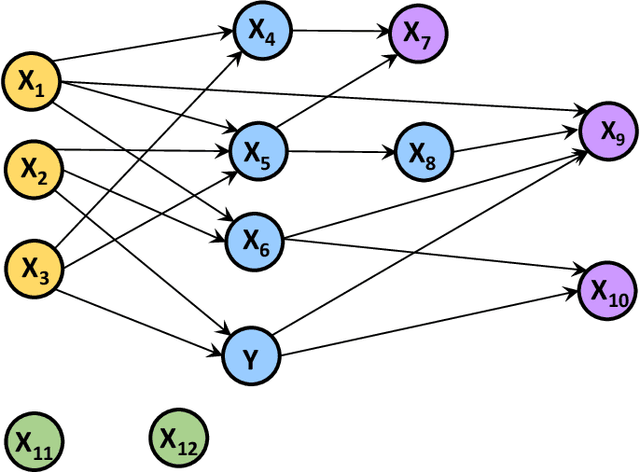

In this paper, we develop a generic methodology to encode hierarchical causality structure among observed variables into a neural network in order to improve its predictive performance. The proposed methodology, called causality-informed neural network (CINN), leverages three coherent steps to systematically map the structural causal knowledge into the layer-to-layer design of neural network while strictly preserving the orientation of every causal relationship. In the first step, CINN discovers causal relationships from observational data via directed acyclic graph (DAG) learning, where causal discovery is recast as a continuous optimization problem to avoid the combinatorial nature. In the second step, the discovered hierarchical causality structure among observed variables is systematically encoded into neural network through a dedicated architecture and customized loss function. By categorizing variables in the causal DAG as root, intermediate, and leaf nodes, the hierarchical causal DAG is translated into CINN with a one-to-one correspondence between nodes in the causal DAG and units in the CINN while maintaining the relative order among these nodes. Regarding the loss function, both intermediate and leaf nodes in the DAG graph are treated as target outputs during CINN training so as to drive co-learning of causal relationships among different types of nodes. As multiple loss components emerge in CINN, we leverage the projection of conflicting gradients to mitigate gradient interference among the multiple learning tasks. Computational experiments across a broad spectrum of UCI data sets demonstrate substantial advantages of CINN in predictive performance over other state-of-the-art methods. In addition, an ablation study underscores the value of integrating structural and quantitative causal knowledge in enhancing the neural network's predictive performance incrementally.
A class-weighted supervised contrastive learning long-tailed bearing fault diagnosis approach using quadratic neural network
Sep 21, 2023



Deep learning has achieved remarkable success in bearing fault diagnosis. However, its performance oftentimes deteriorates when dealing with highly imbalanced or long-tailed data, while such cases are prevalent in industrial settings because fault is a rare event that occurs with an extremely low probability. Conventional data augmentation methods face fundamental limitations due to the scarcity of samples pertaining to the minority class. In this paper, we propose a supervised contrastive learning approach with a class-aware loss function to enhance the feature extraction capability of neural networks for fault diagnosis. The developed class-weighted contrastive learning quadratic network (CCQNet) consists of a quadratic convolutional residual network backbone, a contrastive learning branch utilizing a class-weighted contrastive loss, and a classifier branch employing logit-adjusted cross-entropy loss. By utilizing class-weighted contrastive loss and logit-adjusted cross-entropy loss, our approach encourages equidistant representation of class features, thereby inducing equal attention on all the classes. We further analyze the superior feature extraction ability of quadratic network by establishing the connection between quadratic neurons and autocorrelation in signal processing. Experimental results on public and proprietary datasets are used to validate the effectiveness of CCQNet, and computational results reveal that CCQNet outperforms SOTA methods in handling extremely imbalanced data substantially.
BearingPGA-Net: A Lightweight and Deployable Bearing Fault Diagnosis Network via Decoupled Knowledge Distillation and FPGA Acceleration
Jul 31, 2023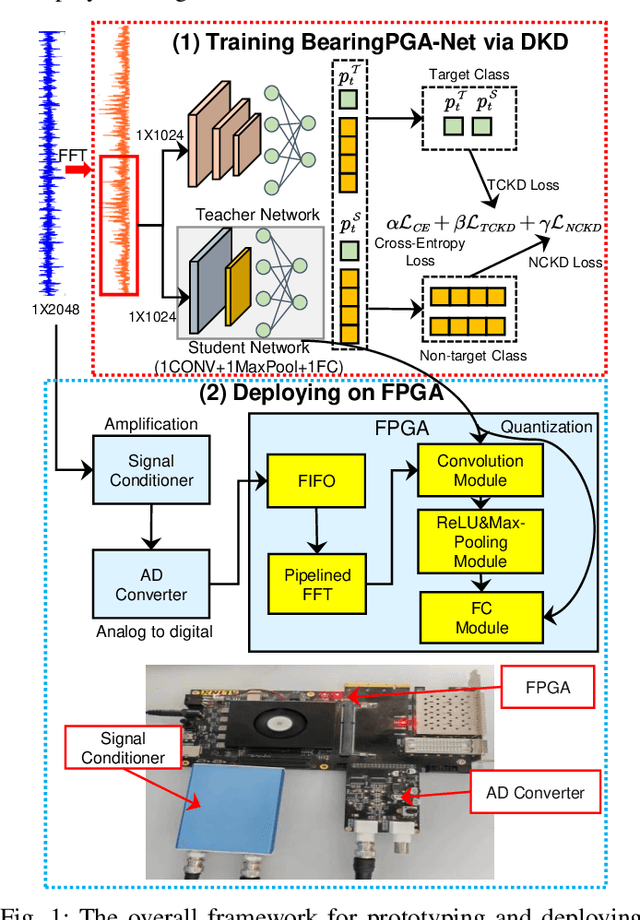

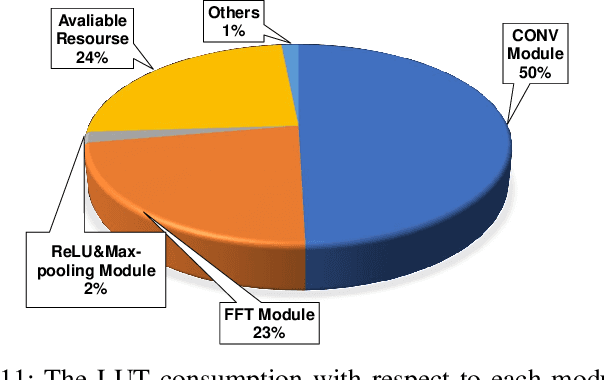
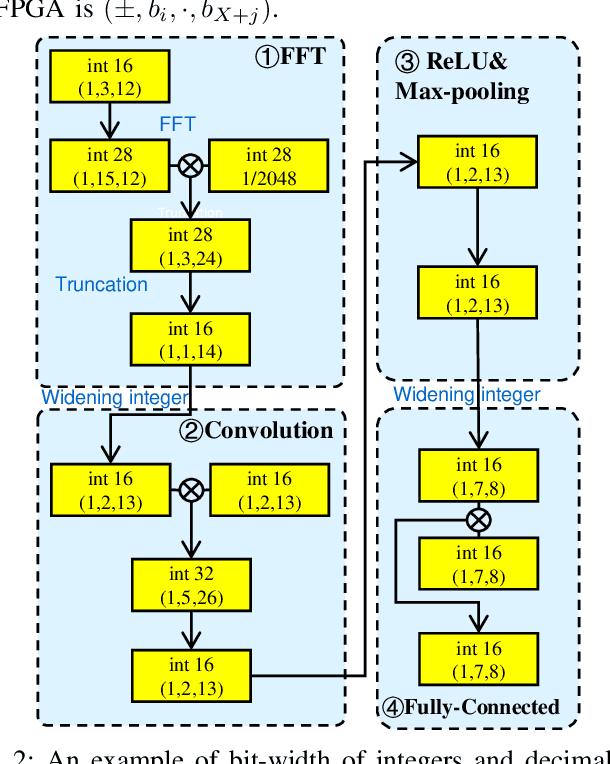
Deep learning has achieved remarkable success in the field of bearing fault diagnosis. However, this success comes with larger models and more complex computations, which cannot be transferred into industrial fields requiring models to be of high speed, strong portability, and low power consumption. In this paper, we propose a lightweight and deployable model for bearing fault diagnosis, referred to as BearingPGA-Net, to address these challenges. Firstly, aided by a well-trained large model, we train BearingPGA-Net via decoupled knowledge distillation. Despite its small size, our model demonstrates excellent fault diagnosis performance compared to other lightweight state-of-the-art methods. Secondly, we design an FPGA acceleration scheme for BearingPGA-Net using Verilog. This scheme involves the customized quantization and designing programmable logic gates for each layer of BearingPGA-Net on the FPGA, with an emphasis on parallel computing and module reuse to enhance the computational speed. To the best of our knowledge, this is the first instance of deploying a CNN-based bearing fault diagnosis model on an FPGA. Experimental results reveal that our deployment scheme achieves over 200 times faster diagnosis speed compared to CPU, while achieving a lower-than-0.4\% performance drop in terms of F1, Recall, and Precision score on our independently-collected bearing dataset. Our code is available at \url{https://github.com/asdvfghg/BearingPGA-Net}.
Uncertainty Quantification in Machine Learning for Engineering Design and Health Prognostics: A Tutorial
May 07, 2023



On top of machine learning models, uncertainty quantification (UQ) functions as an essential layer of safety assurance that could lead to more principled decision making by enabling sound risk assessment and management. The safety and reliability improvement of ML models empowered by UQ has the potential to significantly facilitate the broad adoption of ML solutions in high-stakes decision settings, such as healthcare, manufacturing, and aviation, to name a few. In this tutorial, we aim to provide a holistic lens on emerging UQ methods for ML models with a particular focus on neural networks and the applications of these UQ methods in tackling engineering design as well as prognostics and health management problems. Toward this goal, we start with a comprehensive classification of uncertainty types, sources, and causes pertaining to UQ of ML models. Next, we provide a tutorial-style description of several state-of-the-art UQ methods: Gaussian process regression, Bayesian neural network, neural network ensemble, and deterministic UQ methods focusing on spectral-normalized neural Gaussian process. Established upon the mathematical formulations, we subsequently examine the soundness of these UQ methods quantitatively and qualitatively (by a toy regression example) to examine their strengths and shortcomings from different dimensions. Then, we review quantitative metrics commonly used to assess the quality of predictive uncertainty in classification and regression problems. Afterward, we discuss the increasingly important role of UQ of ML models in solving challenging problems in engineering design and health prognostics. Two case studies with source codes available on GitHub are used to demonstrate these UQ methods and compare their performance in the life prediction of lithium-ion batteries at the early stage and the remaining useful life prediction of turbofan engines.