 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Battery Lifetime Under Varying Usage Conditions from Early Aging Data
Jul 17, 2023Accurate battery lifetime prediction is important for preventative maintenance, warranties, and improved cell design and manufacturing. However, manufacturing variability and usage-dependent degradation make life prediction challenging. Here, we investigate new features derived from capacity-voltage data in early life to predict the lifetime of cells cycled under widely varying charge rates, discharge rates, and depths of discharge. Features were extracted from regularly scheduled reference performance tests (i.e., low rate full cycles) during cycling. The early-life features capture a cell's state of health and the rate of change of component-level degradation modes, some of which correlate strongly with cell lifetime. Using a newly generated dataset from 225 nickel-manganese-cobalt/graphite Li-ion cells aged under a wide range of conditions, we demonstrate a lifetime prediction of in-distribution cells with 15.1% mean absolute percentage error using no more than the first 15% of data, for most cells. Further testing using a hierarchical Bayesian regression model shows improved performance on extrapolation, achieving 21.8% mean absolute percentage error for out-of-distribution cells. Our approach highlights the importance of using domain knowledge of lithium-ion battery degradation modes to inform feature engineering. Further, we provide the community with a new publicly available battery aging dataset with cells cycled beyond 80% of their rated capacity.
Federated Learning with Uncertainty-Based Client Clustering for Fleet-Wide Fault Diagnosis
Apr 26, 2023Operators from various industries have been pushing the adoption of wireless sensing nodes for industrial monitoring, and such efforts have produced sizeable condition monitoring datasets that can be used to build diagnosis algorithms capable of warning maintenance engineers of impending failure or identifying current system health conditions. However, single operators may not have sufficiently large fleets of systems or component units to collect sufficient data to develop data-driven algorithms. Collecting a satisfactory quantity of fault patterns for safety-critical systems is particularly difficult due to the rarity of faults. Federated learning (FL) has emerged as a promising solution to leverage datasets from multiple operators to train a decentralized asset fault diagnosis model while maintaining data confidentiality. However, there are still considerable obstacles to overcome when it comes to optimizing the federation strategy without leaking sensitive data and addressing the issue of client dataset heterogeneity. This is particularly prevalent in fault diagnosis applications due to the high diversity of operating conditions and system configurations. To address these two challenges, we propose a novel clustering-based FL algorithm where clients are clustered for federating based on dataset similarity. To quantify dataset similarity between clients without explicitly sharing data, each client sets aside a local test dataset and evaluates the other clients' model prediction accuracy and uncertainty on this test dataset. Clients are then clustered for FL based on relative prediction accuracy and uncertainty.
A Comprehensive Review of Digital Twin -- Part 2: Roles of Uncertainty Quantification and Optimization, a Battery Digital Twin, and Perspectives
Aug 27, 2022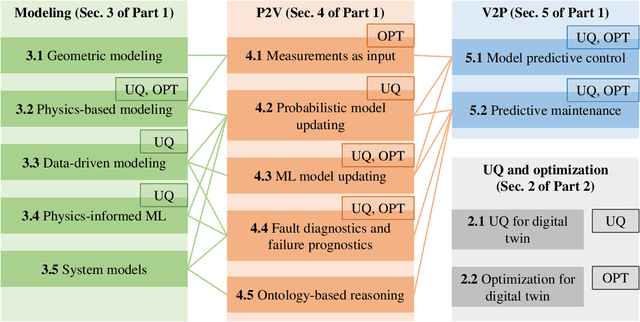
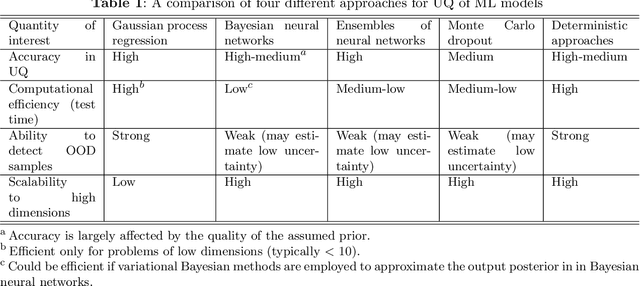
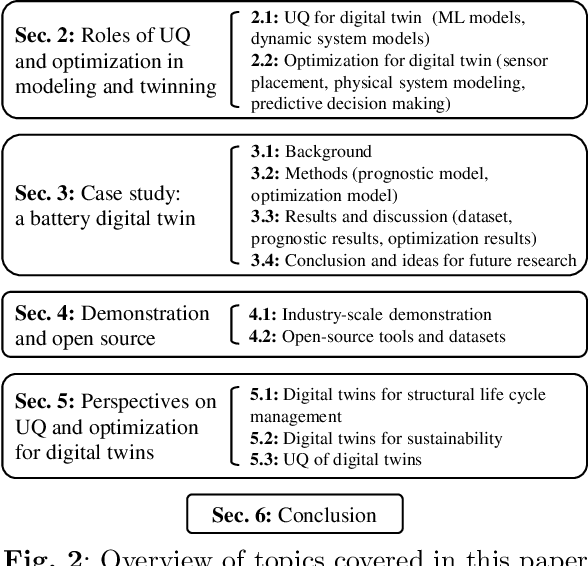
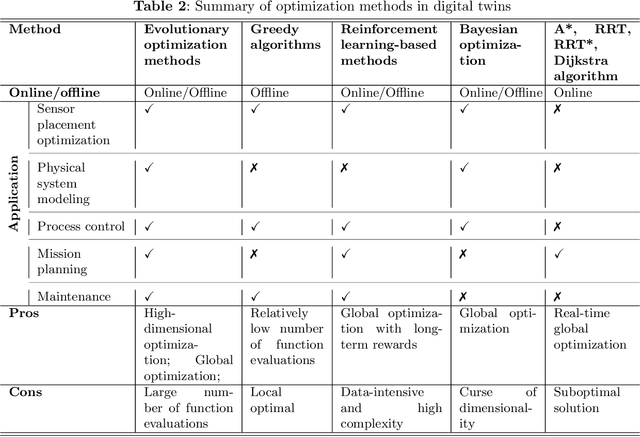
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This second paper presents a literature review of key enabling technologies of digital twins, with an emphasis on uncertainty quantification, optimization methods, open source datasets and tools, major findings, challenges, and future directions. Discussions focus on current methods of uncertainty quantification and optimization and how they are applied in different dimensions of a digital twin. Additionally, this paper presents a case study where a battery digital twin is constructed and tested to illustrate some of the modeling and twinning methods reviewed in this two-part review. Code and preprocessed data for generating all the results and figures presented in the case study are available on GitHub.
A Comprehensive Review of Digital Twin -- Part 1: Modeling and Twinning Enabling Technologies
Aug 26, 2022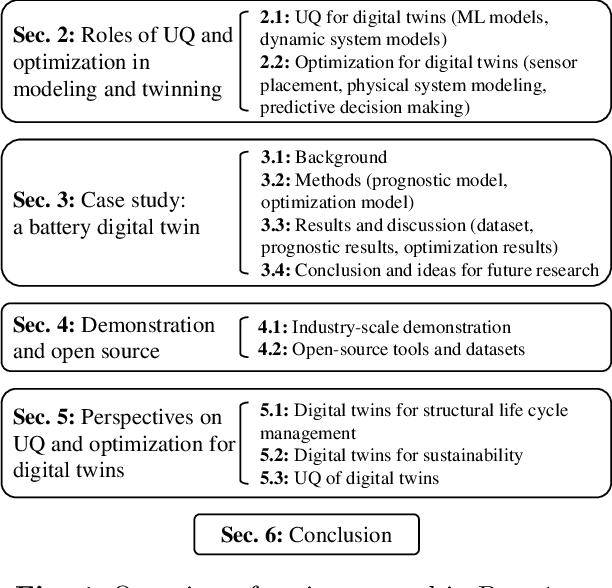
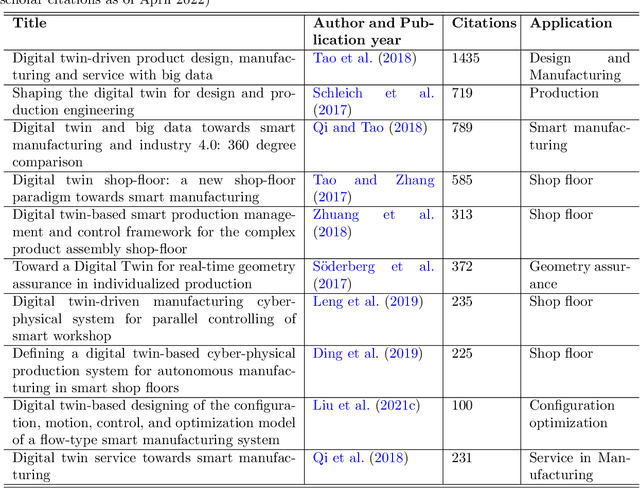
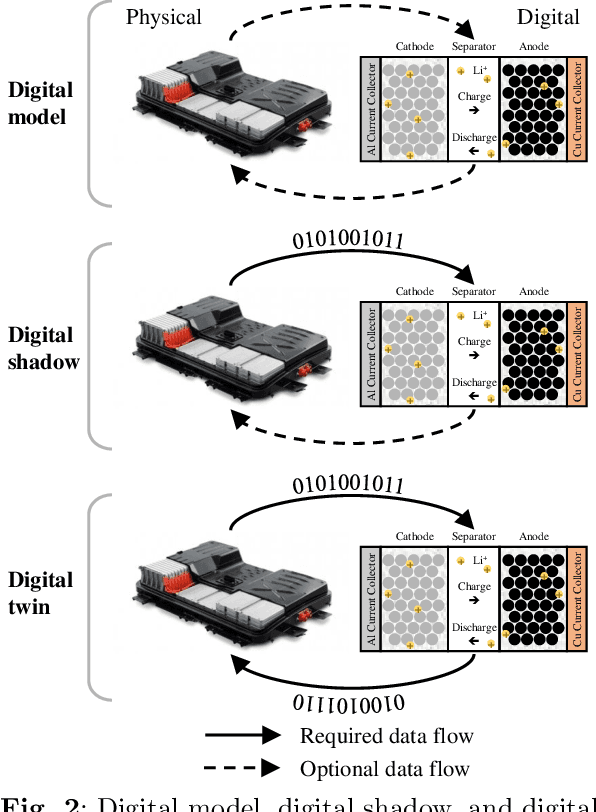
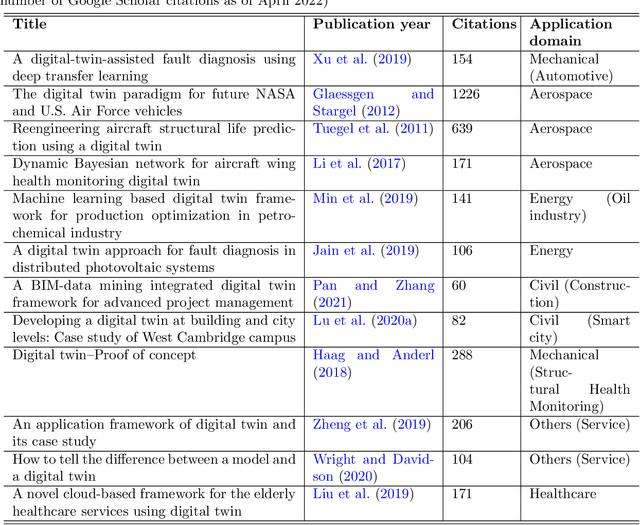
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This first paper presents a thorough literature review of digital twin trends across many disciplines currently pursuing this area of research. Then, digital twin modeling and twinning enabling technologies are further analyzed by classifying them into two main categories: physical-to-virtual, and virtual-to-physical, based on the direction in which data flows. Finally, this paper provides perspectives on the trajectory of digital twin technology over the next decade, and introduces a few emerging areas of research which will likely be of great use in future digital twin research. In part two of this review, the role of uncertainty quantification and optimization are discussed, a battery digital twin is demonstrated, and more perspectives on the future of digital twin are shared.