 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
Feb 02, 2026The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap
AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation
Jun 11, 2025
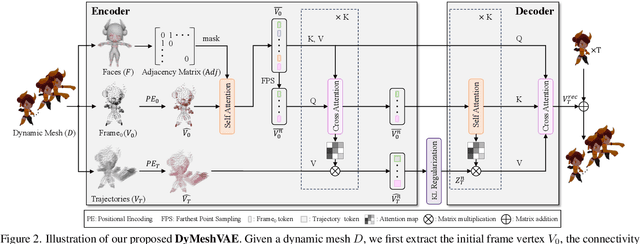
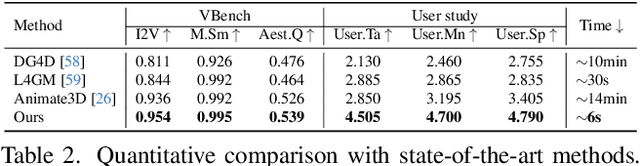
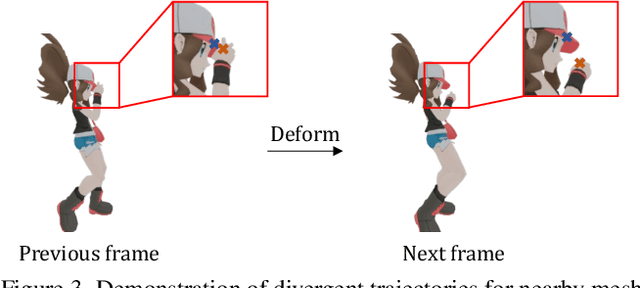
Recent advances in 4D content generation have attracted increasing attention, yet creating high-quality animated 3D models remains challenging due to the complexity of modeling spatio-temporal distributions and the scarcity of 4D training data. In this paper, we present AnimateAnyMesh, the first feed-forward framework that enables efficient text-driven animation of arbitrary 3D meshes. Our approach leverages a novel DyMeshVAE architecture that effectively compresses and reconstructs dynamic mesh sequences by disentangling spatial and temporal features while preserving local topological structures. To enable high-quality text-conditional generation, we employ a Rectified Flow-based training strategy in the compressed latent space. Additionally, we contribute the DyMesh Dataset, containing over 4M diverse dynamic mesh sequences with text annotations. Experimental results demonstrate that our method generates semantically accurate and temporally coherent mesh animations in a few seconds, significantly outperforming existing approaches in both quality and efficiency. Our work marks a substantial step forward in making 4D content creation more accessible and practical. All the data, code, and models will be open-released.
Mic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025

Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
Multiview Point Cloud Registration Based on Minimum Potential Energy for Free-Form Blade Measurement
Feb 11, 2025Point cloud registration is an essential step for free-form blade reconstruction in industrial measurement. Nonetheless, measuring defects of the 3D acquisition system unavoidably result in noisy and incomplete point cloud data, which renders efficient and accurate registration challenging. In this paper, we propose a novel global registration method that is based on the minimum potential energy (MPE) method to address these problems. The basic strategy is that the objective function is defined as the minimum potential energy optimization function of the physical registration system. The function distributes more weight to the majority of inlier points and less weight to the noise and outliers, which essentially reduces the influence of perturbations in the mathematical formulation. We decompose the solution into a globally optimal approximation procedure and a fine registration process with the trimmed iterative closest point algorithm to boost convergence. The approximation procedure consists of two main steps. First, according to the construction of the force traction operator, we can simply compute the position of the potential energy minimum. Second, to find the MPE point, we propose a new theory that employs two flags to observe the status of the registration procedure. We demonstrate the performance of the proposed algorithm on four types of blades. The proposed method outperforms the other global methods in terms of both accuracy and noise resistance.
Decoupled Sparse Priors Guided Diffusion Compression Model for Point Clouds
Nov 21, 2024



Lossy compression methods rely on an autoencoder to transform a point cloud into latent points for storage, leaving the inherent redundancy of latent representations unexplored. To reduce redundancy in latent points, we propose a sparse priors guided method that achieves high reconstruction quality, especially at high compression ratios. This is accomplished by a dual-density scheme separately processing the latent points (intended for reconstruction) and the decoupled sparse priors (intended for storage). Our approach features an efficient dual-density data flow that relaxes size constraints on latent points, and hybridizes a progressive conditional diffusion model to encapsulate essential details for reconstruction within the conditions, which are decoupled hierarchically to intra-point and inter-point priors. Specifically, our method encodes the original point cloud into latent points and decoupled sparse priors through separate encoders. Latent points serve as intermediates, while sparse priors act as adaptive conditions. We then employ a progressive attention-based conditional denoiser to generate latent points conditioned on the decoupled priors, allowing the denoiser to dynamically attend to geometric and semantic cues from the priors at each encoding and decoding layer. Additionally, we integrate the local distribution into the arithmetic encoder and decoder to enhance local context modeling of the sparse points. The original point cloud is reconstructed through a point decoder. Compared to state-of-the-art, our method obtains superior rate-distortion trade-off, evidenced by extensive evaluations on the ShapeNet dataset and standard test datasets from MPEG group including 8iVFB, and Owlii.
Referring Human Pose and Mask Estimation in the Wild
Oct 27, 2024We introduce Referring Human Pose and Mask Estimation (R-HPM) in the wild, where either a text or positional prompt specifies the person of interest in an image. This new task holds significant potential for human-centric applications such as assistive robotics and sports analysis. In contrast to previous works, R-HPM (i) ensures high-quality, identity-aware results corresponding to the referred person, and (ii) simultaneously predicts human pose and mask for a comprehensive representation. To achieve this, we introduce a large-scale dataset named RefHuman, which substantially extends the MS COCO dataset with additional text and positional prompt annotations. RefHuman includes over 50,000 annotated instances in the wild, each equipped with keypoint, mask, and prompt annotations. To enable prompt-conditioned estimation, we propose the first end-to-end promptable approach named UniPHD for R-HPM. UniPHD extracts multimodal representations and employs a proposed pose-centric hierarchical decoder to process (text or positional) instance queries and keypoint queries, producing results specific to the referred person. Extensive experiments demonstrate that UniPHD produces quality results based on user-friendly prompts and achieves top-tier performance on RefHuman val and MS COCO val2017. Data and Code: https://github.com/bo-miao/RefHuman
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Apr 04, 2024Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
3D Object Detection from Point Cloud via Voting Step Diffusion
Mar 21, 2024



3D object detection is a fundamental task in scene understanding. Numerous research efforts have been dedicated to better incorporate Hough voting into the 3D object detection pipeline. However, due to the noisy, cluttered, and partial nature of real 3D scans, existing voting-based methods often receive votes from the partial surfaces of individual objects together with severe noises, leading to sub-optimal detection performance. In this work, we focus on the distributional properties of point clouds and formulate the voting process as generating new points in the high-density region of the distribution of object centers. To achieve this, we propose a new method to move random 3D points toward the high-density region of the distribution by estimating the score function of the distribution with a noise conditioned score network. Specifically, we first generate a set of object center proposals to coarsely identify the high-density region of the object center distribution. To estimate the score function, we perturb the generated object center proposals by adding normalized Gaussian noise, and then jointly estimate the score function of all perturbed distributions. Finally, we generate new votes by moving random 3D points to the high-density region of the object center distribution according to the estimated score function. Extensive experiments on two large scale indoor 3D scene datasets, SUN RGB-D and ScanNet V2, demonstrate the superiority of our proposed method. The code will be released at https://github.com/HHrEtvP/DiffVote.
External Knowledge Enhanced 3D Scene Generation from Sketch
Mar 21, 2024



Generating realistic 3D scenes is challenging due to the complexity of room layouts and object geometries.We propose a sketch based knowledge enhanced diffusion architecture (SEK) for generating customized, diverse, and plausible 3D scenes. SEK conditions the denoising process with a hand-drawn sketch of the target scene and cues from an object relationship knowledge base. We first construct an external knowledge base containing object relationships and then leverage knowledge enhanced graph reasoning to assist our model in understanding hand-drawn sketches. A scene is represented as a combination of 3D objects and their relationships, and then incrementally diffused to reach a Gaussian distribution.We propose a 3D denoising scene transformer that learns to reverse the diffusion process, conditioned by a hand-drawn sketch along with knowledge cues, to regressively generate the scene including the 3D object instances as well as their layout. Experiments on the 3D-FRONT dataset show that our model improves FID, CKL by 17.41%, 37.18% in 3D scene generation and FID, KID by 19.12%, 20.06% in 3D scene completion compared to the nearest competitor DiffuScene.
Beyond Skeletons: Integrative Latent Mapping for Coherent 4D Sequence Generation
Mar 20, 2024



Directly learning to model 4D content, including shape, color and motion, is challenging. Existing methods depend on skeleton-based motion control and offer limited continuity in detail. To address this, we propose a novel framework that generates coherent 4D sequences with animation of 3D shapes under given conditions with dynamic evolution of shape and color over time through integrative latent mapping. We first employ an integrative latent unified representation to encode shape and color information of each detailed 3D geometry frame. The proposed skeleton-free latent 4D sequence joint representation allows us to leverage diffusion models in a low-dimensional space to control the generation of 4D sequences. Finally, temporally coherent 4D sequences are generated conforming well to the input images and text prompts. Extensive experiments on the ShapeNet, 3DBiCar and DeformingThings4D datasets for several tasks demonstrate that our method effectively learns to generate quality 3D shapes with color and 4D mesh animations, improving over the current state-of-the-art. Source code will be released.