 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Object Detection from Point Cloud via Voting Step Diffusion
Mar 21, 2024



3D object detection is a fundamental task in scene understanding. Numerous research efforts have been dedicated to better incorporate Hough voting into the 3D object detection pipeline. However, due to the noisy, cluttered, and partial nature of real 3D scans, existing voting-based methods often receive votes from the partial surfaces of individual objects together with severe noises, leading to sub-optimal detection performance. In this work, we focus on the distributional properties of point clouds and formulate the voting process as generating new points in the high-density region of the distribution of object centers. To achieve this, we propose a new method to move random 3D points toward the high-density region of the distribution by estimating the score function of the distribution with a noise conditioned score network. Specifically, we first generate a set of object center proposals to coarsely identify the high-density region of the object center distribution. To estimate the score function, we perturb the generated object center proposals by adding normalized Gaussian noise, and then jointly estimate the score function of all perturbed distributions. Finally, we generate new votes by moving random 3D points to the high-density region of the object center distribution according to the estimated score function. Extensive experiments on two large scale indoor 3D scene datasets, SUN RGB-D and ScanNet V2, demonstrate the superiority of our proposed method. The code will be released at https://github.com/HHrEtvP/DiffVote.
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022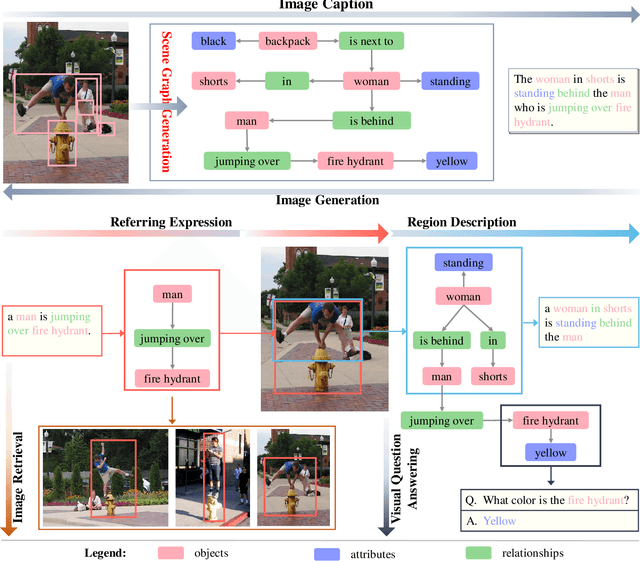
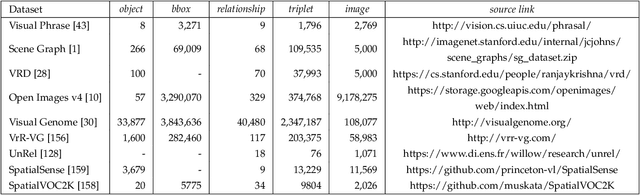
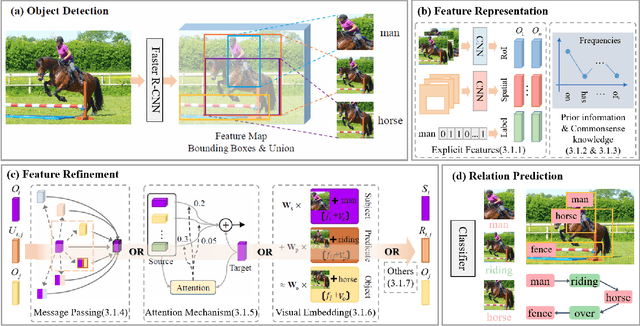
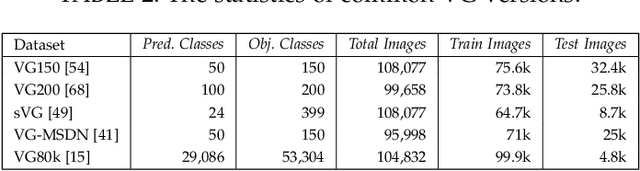
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.