 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
May 19, 2026Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
POQD: Performance-Oriented Query Decomposer for Multi-vector retrieval
May 25, 2025Although Multi-Vector Retrieval (MVR) has achieved the state of the art on many information retrieval (IR) tasks, its performance highly depends on how to decompose queries into smaller pieces, say phrases or tokens. However, optimizing query decomposition for MVR performance is not end-to-end differentiable. Even worse, jointly solving this problem and training the downstream retrieval-based systems, say RAG systems could be highly inefficient. To overcome these challenges, we propose Performance-Oriented Query Decomposer (POQD), a novel query decomposition framework for MVR. POQD leverages one LLM for query decomposition and searches the optimal prompt with an LLM-based optimizer. We further propose an end-to-end training algorithm to alternatively optimize the prompt for query decomposition and the downstream models. This algorithm can achieve superior MVR performance at a reasonable training cost as our theoretical analysis suggests. POQD can be integrated seamlessly into arbitrary retrieval-based systems such as Retrieval-Augmented Generation (RAG) systems. Extensive empirical studies on representative RAG-based QA tasks show that POQD outperforms existing query decomposition strategies in both retrieval performance and end-to-end QA accuracy. POQD is available at https://github.com/PKU-SDS-lab/POQD-ICML25.
Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
Jan 07, 2025

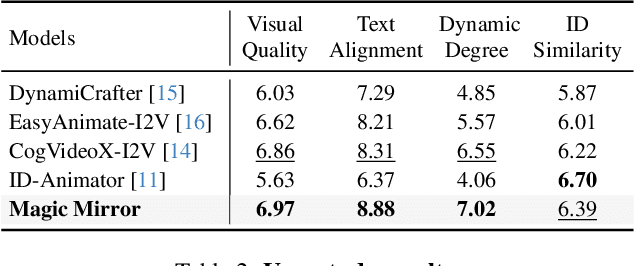
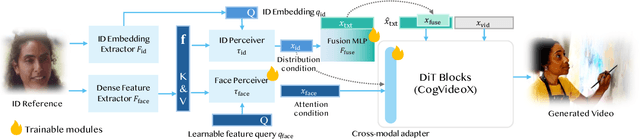
We present Magic Mirror, a framework for generating identity-preserved videos with cinematic-level quality and dynamic motion. While recent advances in video diffusion models have shown impressive capabilities in text-to-video generation, maintaining consistent identity while producing natural motion remains challenging. Previous methods either require person-specific fine-tuning or struggle to balance identity preservation with motion diversity. Built upon Video Diffusion Transformers, our method introduces three key components: (1) a dual-branch facial feature extractor that captures both identity and structural features, (2) a lightweight cross-modal adapter with Conditioned Adaptive Normalization for efficient identity integration, and (3) a two-stage training strategy combining synthetic identity pairs with video data. Extensive experiments demonstrate that Magic Mirror effectively balances identity consistency with natural motion, outperforming existing methods across multiple metrics while requiring minimal parameters added. The code and model will be made publicly available at: https://github.com/dvlab-research/MagicMirror/
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation
Jun 26, 2024



We propose a novel text-to-video (T2V) generation benchmark, ChronoMagic-Bench, to evaluate the temporal and metamorphic capabilities of the T2V models (e.g. Sora and Lumiere) in time-lapse video generation. In contrast to existing benchmarks that focus on the visual quality and textual relevance of generated videos, ChronoMagic-Bench focuses on the model's ability to generate time-lapse videos with significant metamorphic amplitude and temporal coherence. The benchmark probes T2V models for their physics, biology, and chemistry capabilities, in a free-form text query. For these purposes, ChronoMagic-Bench introduces 1,649 prompts and real-world videos as references, categorized into four major types of time-lapse videos: biological, human-created, meteorological, and physical phenomena, which are further divided into 75 subcategories. This categorization comprehensively evaluates the model's capacity to handle diverse and complex transformations. To accurately align human preference with the benchmark, we introduce two new automatic metrics, MTScore and CHScore, to evaluate the videos' metamorphic attributes and temporal coherence. MTScore measures the metamorphic amplitude, reflecting the degree of change over time, while CHScore assesses the temporal coherence, ensuring the generated videos maintain logical progression and continuity. Based on the ChronoMagic-Bench, we conduct comprehensive manual evaluations of ten representative T2V models, revealing their strengths and weaknesses across different categories of prompts, and providing a thorough evaluation framework that addresses current gaps in video generation research. Moreover, we create a large-scale ChronoMagic-Pro dataset, containing 460k high-quality pairs of 720p time-lapse videos and detailed captions ensuring high physical pertinence and large metamorphic amplitude.