 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass: General Filtered Search across Vector and Structured Data
Oct 31, 2025The increasing prevalence of hybrid vector and relational data necessitates efficient, general support for queries that combine high-dimensional vector search with complex relational filtering. However, existing filtered search solutions are fundamentally limited by specialized indices, which restrict arbitrary filtering and hinder integration with general-purpose DBMSs. This work introduces \textsc{Compass}, a unified framework that enables general filtered search across vector and structured data without relying on new index designs. Compass leverages established index structures -- such as HNSW and IVF for vector attributes, and B+-trees for relational attributes -- implementing a principled cooperative query execution strategy that coordinates candidate generation and predicate evaluation across modalities. Uniquely, Compass maintains generality by allowing arbitrary conjunctions, disjunctions, and range predicates, while ensuring robustness even with highly-selective or multi-attribute filters. Comprehensive empirical evaluations demonstrate that Compass consistently outperforms NaviX, the only existing performant general framework, across diverse hybrid query workloads. It also matches the query throughput of specialized single-attribute indices in their favorite settings with only a single attribute involved, all while maintaining full generality and DBMS compatibility. Overall, Compass offers a practical and robust solution for achieving truly general filtered search in vector database systems.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025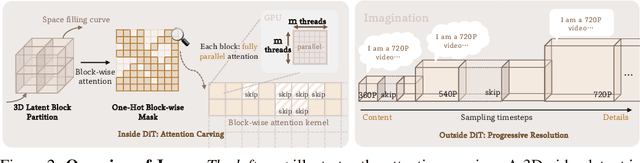
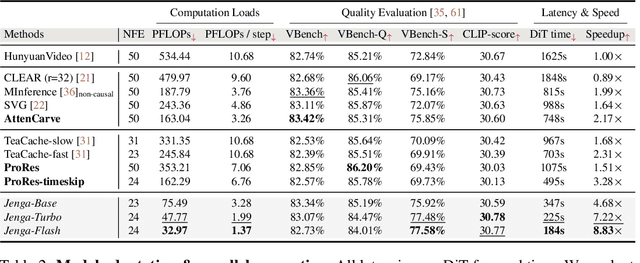
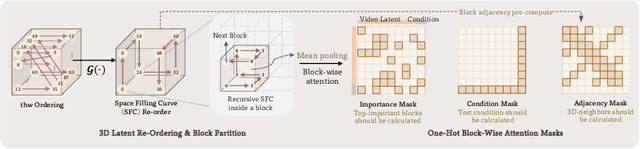
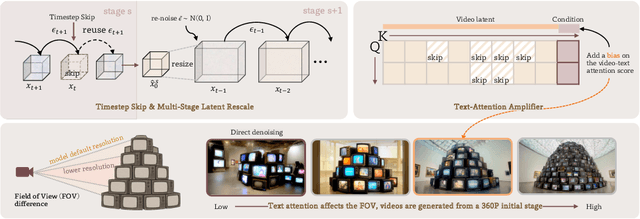
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
Jan 07, 2025

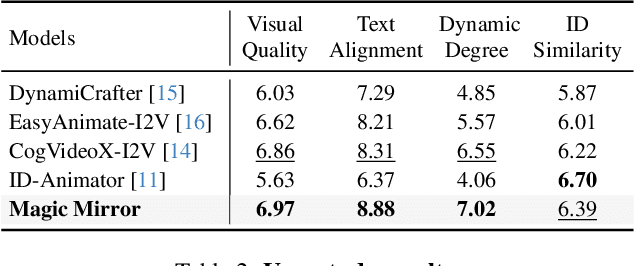
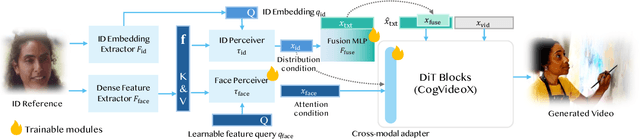
We present Magic Mirror, a framework for generating identity-preserved videos with cinematic-level quality and dynamic motion. While recent advances in video diffusion models have shown impressive capabilities in text-to-video generation, maintaining consistent identity while producing natural motion remains challenging. Previous methods either require person-specific fine-tuning or struggle to balance identity preservation with motion diversity. Built upon Video Diffusion Transformers, our method introduces three key components: (1) a dual-branch facial feature extractor that captures both identity and structural features, (2) a lightweight cross-modal adapter with Conditioned Adaptive Normalization for efficient identity integration, and (3) a two-stage training strategy combining synthetic identity pairs with video data. Extensive experiments demonstrate that Magic Mirror effectively balances identity consistency with natural motion, outperforming existing methods across multiple metrics while requiring minimal parameters added. The code and model will be made publicly available at: https://github.com/dvlab-research/MagicMirror/
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
Biathlon: Harnessing Model Resilience for Accelerating ML Inference Pipelines
May 18, 2024
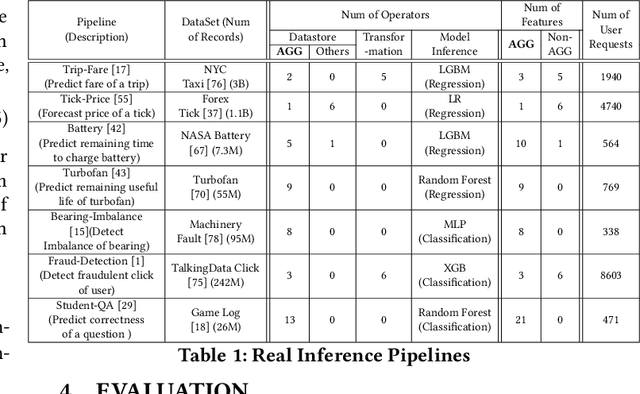
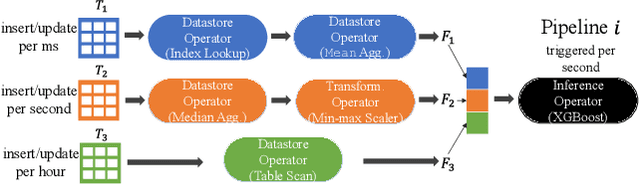
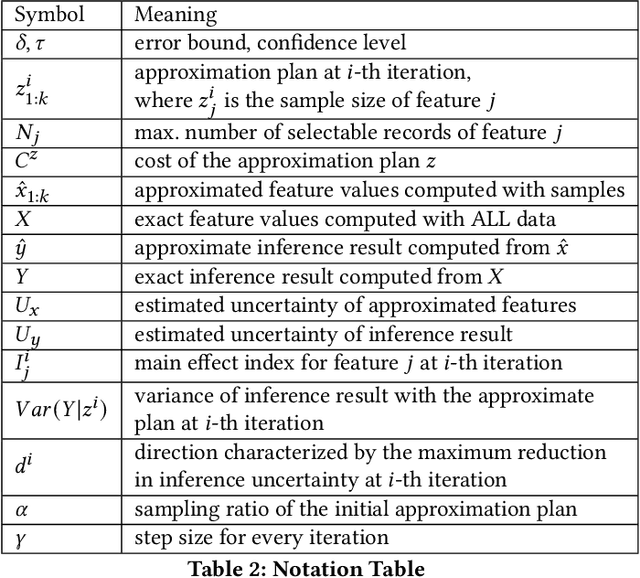
Machine learning inference pipelines commonly encountered in data science and industries often require real-time responsiveness due to their user-facing nature. However, meeting this requirement becomes particularly challenging when certain input features require aggregating a large volume of data online. Recent literature on interpretable machine learning reveals that most machine learning models exhibit a notable degree of resilience to variations in input. This suggests that machine learning models can effectively accommodate approximate input features with minimal discernible impact on accuracy. In this paper, we introduce Biathlon, a novel ML serving system that leverages the inherent resilience of models and determines the optimal degree of approximation for each aggregation feature. This approach enables maximum speedup while ensuring a guaranteed bound on accuracy loss. We evaluate Biathlon on real pipelines from both industry applications and data science competitions, demonstrating its ability to meet real-time latency requirements by achieving 5.3x to 16.6x speedup with almost no accuracy loss.
Real-World Image Variation by Aligning Diffusion Inversion Chain
May 30, 2023



Recent diffusion model advancements have enabled high-fidelity images to be generated using text prompts. However, a domain gap exists between generated images and real-world images, which poses a challenge in generating high-quality variations of real-world images. Our investigation uncovers that this domain gap originates from a latents' distribution gap in different diffusion processes. To address this issue, we propose a novel inference pipeline called Real-world Image Variation by ALignment (RIVAL) that utilizes diffusion models to generate image variations from a single image exemplar. Our pipeline enhances the generation quality of image variations by aligning the image generation process to the source image's inversion chain. Specifically, we demonstrate that step-wise latent distribution alignment is essential for generating high-quality variations. To attain this, we design a cross-image self-attention injection for feature interaction and a step-wise distribution normalization to align the latent features. Incorporating these alignment processes into a diffusion model allows RIVAL to generate high-quality image variations without further parameter optimization. Our experimental results demonstrate that our proposed approach outperforms existing methods with respect to semantic-condition similarity and perceptual quality. Furthermore, this generalized inference pipeline can be easily applied to other diffusion-based generation tasks, such as image-conditioned text-to-image generation and example-based image inpainting.
Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition
Mar 22, 2022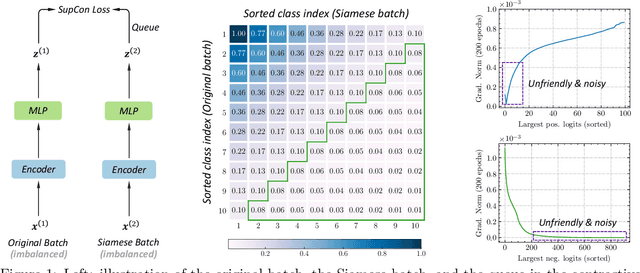
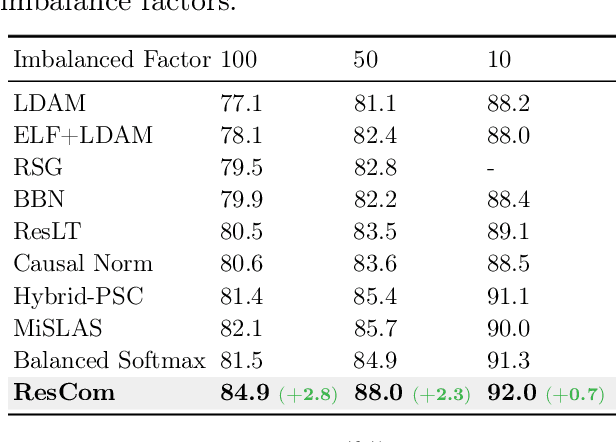
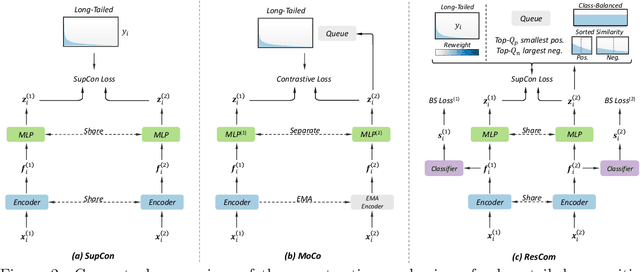
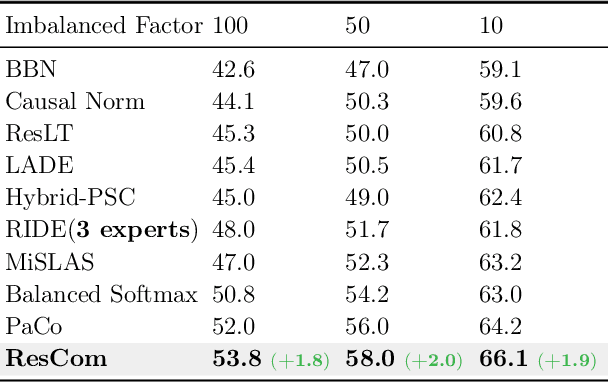
Deep neural networks perform poorly on heavily class-imbalanced datasets. Given the promising performance of contrastive learning, we propose $\mathbf{Re}$balanced $\mathbf{S}$iamese $\mathbf{Co}$ntrastive $\mathbf{m}$ining ( $\mathbf{ResCom}$) to tackle imbalanced recognition. Based on the mathematical analysis and simulation results, we claim that supervised contrastive learning suffers a dual class-imbalance problem at both the original batch and Siamese batch levels, which is more serious than long-tailed classification learning. In this paper, at the original batch level, we introduce a class-balanced supervised contrastive loss to assign adaptive weights for different classes. At the Siamese batch level, we present a class-balanced queue, which maintains the same number of keys for all classes. Furthermore, we note that the contrastive loss gradient with respect to the contrastive logits can be decoupled into the positives and negatives, and easy positives and easy negatives will make the contrastive gradient vanish. We propose supervised hard positive and negative pairs mining to pick up informative pairs for contrastive computation and improve representation learning. Finally, to approximately maximize the mutual information between the two views, we propose Siamese Balanced Softmax and joint it with the contrastive loss for one-stage training. ResCom outperforms the previous methods by large margins on multiple long-tailed recognition benchmarks. Our code will be made publicly available at: https://github.com/dvlab-research/ResCom.