 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass: General Filtered Search across Vector and Structured Data
Oct 31, 2025The increasing prevalence of hybrid vector and relational data necessitates efficient, general support for queries that combine high-dimensional vector search with complex relational filtering. However, existing filtered search solutions are fundamentally limited by specialized indices, which restrict arbitrary filtering and hinder integration with general-purpose DBMSs. This work introduces \textsc{Compass}, a unified framework that enables general filtered search across vector and structured data without relying on new index designs. Compass leverages established index structures -- such as HNSW and IVF for vector attributes, and B+-trees for relational attributes -- implementing a principled cooperative query execution strategy that coordinates candidate generation and predicate evaluation across modalities. Uniquely, Compass maintains generality by allowing arbitrary conjunctions, disjunctions, and range predicates, while ensuring robustness even with highly-selective or multi-attribute filters. Comprehensive empirical evaluations demonstrate that Compass consistently outperforms NaviX, the only existing performant general framework, across diverse hybrid query workloads. It also matches the query throughput of specialized single-attribute indices in their favorite settings with only a single attribute involved, all while maintaining full generality and DBMS compatibility. Overall, Compass offers a practical and robust solution for achieving truly general filtered search in vector database systems.
Biathlon: Harnessing Model Resilience for Accelerating ML Inference Pipelines
May 18, 2024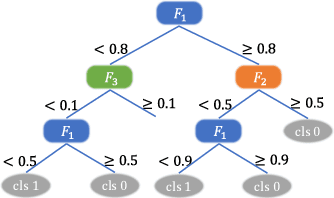
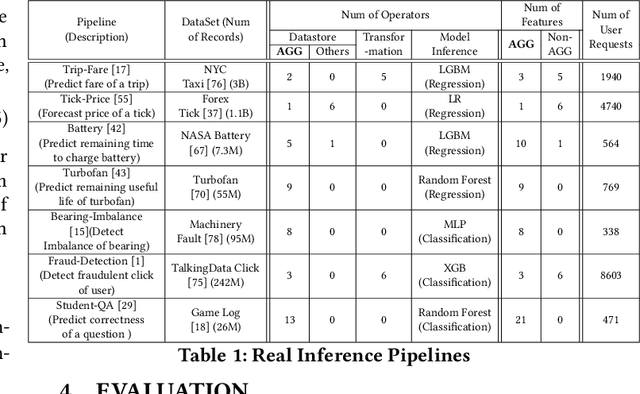
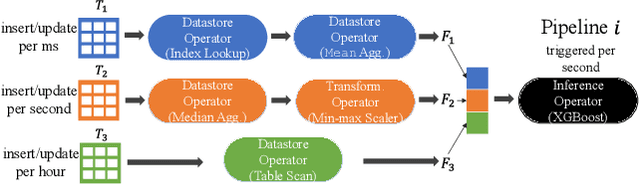
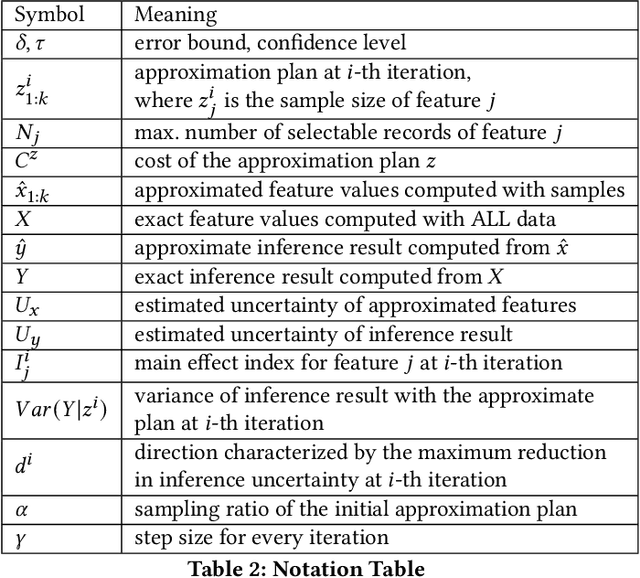
Machine learning inference pipelines commonly encountered in data science and industries often require real-time responsiveness due to their user-facing nature. However, meeting this requirement becomes particularly challenging when certain input features require aggregating a large volume of data online. Recent literature on interpretable machine learning reveals that most machine learning models exhibit a notable degree of resilience to variations in input. This suggests that machine learning models can effectively accommodate approximate input features with minimal discernible impact on accuracy. In this paper, we introduce Biathlon, a novel ML serving system that leverages the inherent resilience of models and determines the optimal degree of approximation for each aggregation feature. This approach enables maximum speedup while ensuring a guaranteed bound on accuracy loss. We evaluate Biathlon on real pipelines from both industry applications and data science competitions, demonstrating its ability to meet real-time latency requirements by achieving 5.3x to 16.6x speedup with almost no accuracy loss.