 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiathlon: Harnessing Model Resilience for Accelerating ML Inference Pipelines
May 18, 2024
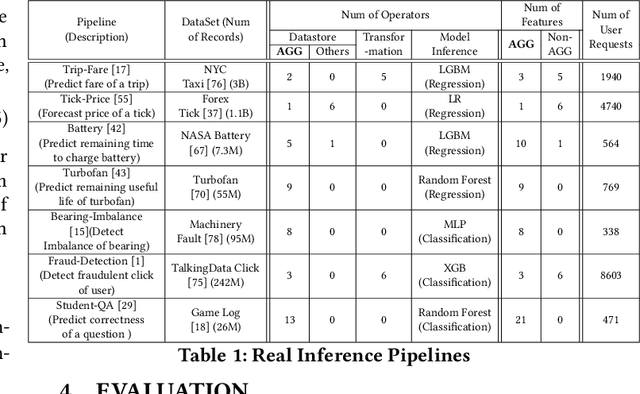
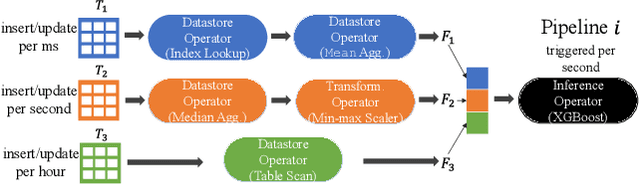
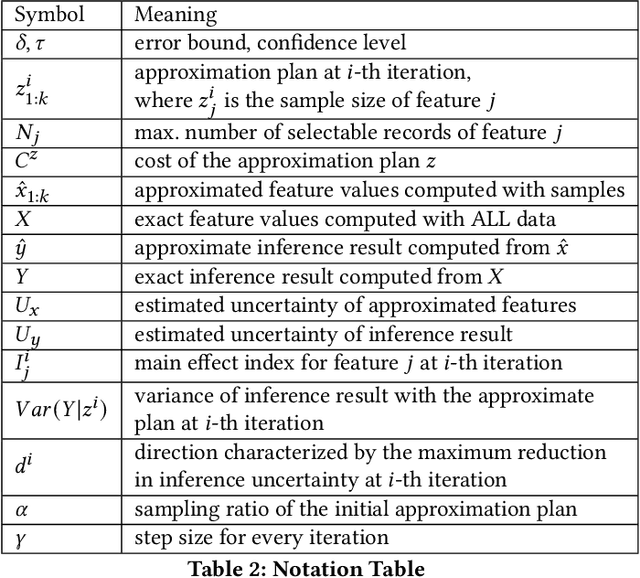
Machine learning inference pipelines commonly encountered in data science and industries often require real-time responsiveness due to their user-facing nature. However, meeting this requirement becomes particularly challenging when certain input features require aggregating a large volume of data online. Recent literature on interpretable machine learning reveals that most machine learning models exhibit a notable degree of resilience to variations in input. This suggests that machine learning models can effectively accommodate approximate input features with minimal discernible impact on accuracy. In this paper, we introduce Biathlon, a novel ML serving system that leverages the inherent resilience of models and determines the optimal degree of approximation for each aggregation feature. This approach enables maximum speedup while ensuring a guaranteed bound on accuracy loss. We evaluate Biathlon on real pipelines from both industry applications and data science competitions, demonstrating its ability to meet real-time latency requirements by achieving 5.3x to 16.6x speedup with almost no accuracy loss.
Is Network the Bottleneck of Distributed Training?
Jun 24, 2020



Recently there has been a surge of research on improving the communication efficiency of distributed training. However, little work has been done to systematically understand whether the network is the bottleneck and to what extent. In this paper, we take a first-principles approach to measure and analyze the network performance of distributed training. As expected, our measurement confirms that communication is the component that blocks distributed training from linear scale-out. However, contrary to the common belief, we find that the network is running at low utilization and that if the network can be fully utilized, distributed training can achieve a scaling factor of close to one. Moreover, while many recent proposals on gradient compression advocate over 100x compression ratio, we show that under full network utilization, there is no need for gradient compression in 100 Gbps network. On the other hand, a lower speed network like 10 Gbps requires only 2x--5x gradients compression ratio to achieve almost linear scale-out. Compared to application-level techniques like gradient compression, network-level optimizations do not require changes to applications and do not hurt the performance of trained models. As such, we advocate that the real challenge of distributed training is for the network community to develop high-performance network transport to fully utilize the network capacity and achieve linear scale-out.