 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSci-Fi: Symmetric Constraint for Frame Inbetweening
May 27, 2025



Frame inbetweening aims to synthesize intermediate video sequences conditioned on the given start and end frames. Current state-of-the-art methods mainly extend large-scale pre-trained Image-to-Video Diffusion models (I2V-DMs) by incorporating end-frame constraints via directly fine-tuning or omitting training. We identify a critical limitation in their design: Their injections of the end-frame constraint usually utilize the same mechanism that originally imposed the start-frame (single image) constraint. However, since the original I2V-DMs are adequately trained for the start-frame condition in advance, naively introducing the end-frame constraint by the same mechanism with much less (even zero) specialized training probably can't make the end frame have a strong enough impact on the intermediate content like the start frame. This asymmetric control strength of the two frames over the intermediate content likely leads to inconsistent motion or appearance collapse in generated frames. To efficiently achieve symmetric constraints of start and end frames, we propose a novel framework, termed Sci-Fi, which applies a stronger injection for the constraint of a smaller training scale. Specifically, it deals with the start-frame constraint as before, while introducing the end-frame constraint by an improved mechanism. The new mechanism is based on a well-designed lightweight module, named EF-Net, which encodes only the end frame and expands it into temporally adaptive frame-wise features injected into the I2V-DM. This makes the end-frame constraint as strong as the start-frame constraint, enabling our Sci-Fi to produce more harmonious transitions in various scenarios. Extensive experiments prove the superiority of our Sci-Fi compared with other baselines.
Next Patch Prediction for Autoregressive Visual Generation
Dec 19, 2024Autoregressive models, built based on the Next Token Prediction (NTP) paradigm, show great potential in developing a unified framework that integrates both language and vision tasks. In this work, we rethink the NTP for autoregressive image generation and propose a novel Next Patch Prediction (NPP) paradigm. Our key idea is to group and aggregate image tokens into patch tokens containing high information density. With patch tokens as a shorter input sequence, the autoregressive model is trained to predict the next patch, thereby significantly reducing the computational cost. We further propose a multi-scale coarse-to-fine patch grouping strategy that exploits the natural hierarchical property of image data. Experiments on a diverse range of models (100M-1.4B parameters) demonstrate that the next patch prediction paradigm could reduce the training cost to around 0.6 times while improving image generation quality by up to 1.0 FID score on the ImageNet benchmark. We highlight that our method retains the original autoregressive model architecture without introducing additional trainable parameters or specifically designing a custom image tokenizer, thus ensuring flexibility and seamless adaptation to various autoregressive models for visual generation.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
Identity-Preserving Text-to-Video Generation by Frequency Decomposition
Nov 26, 2024
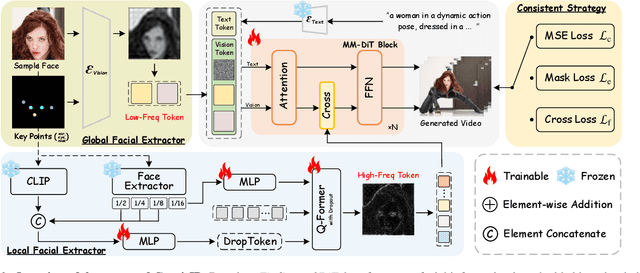
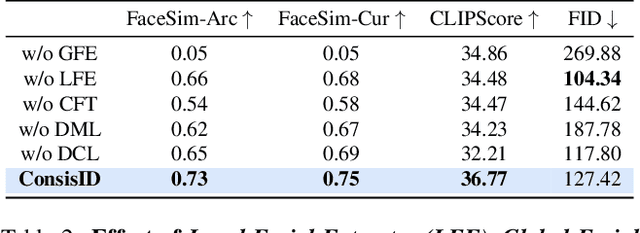
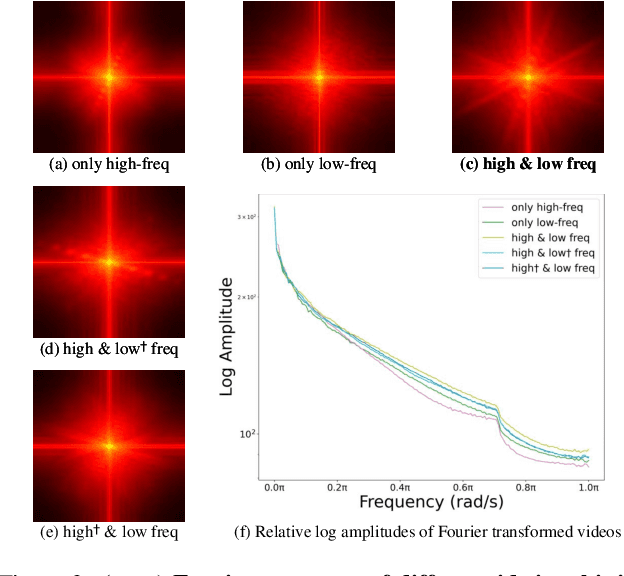
Identity-preserving text-to-video (IPT2V) generation aims to create high-fidelity videos with consistent human identity. It is an important task in video generation but remains an open problem for generative models. This paper pushes the technical frontier of IPT2V in two directions that have not been resolved in literature: (1) A tuning-free pipeline without tedious case-by-case finetuning, and (2) A frequency-aware heuristic identity-preserving DiT-based control scheme. We propose ConsisID, a tuning-free DiT-based controllable IPT2V model to keep human identity consistent in the generated video. Inspired by prior findings in frequency analysis of diffusion transformers, it employs identity-control signals in the frequency domain, where facial features can be decomposed into low-frequency global features and high-frequency intrinsic features. First, from a low-frequency perspective, we introduce a global facial extractor, which encodes reference images and facial key points into a latent space, generating features enriched with low-frequency information. These features are then integrated into shallow layers of the network to alleviate training challenges associated with DiT. Second, from a high-frequency perspective, we design a local facial extractor to capture high-frequency details and inject them into transformer blocks, enhancing the model's ability to preserve fine-grained features. We propose a hierarchical training strategy to leverage frequency information for identity preservation, transforming a vanilla pre-trained video generation model into an IPT2V model. Extensive experiments demonstrate that our frequency-aware heuristic scheme provides an optimal control solution for DiT-based models. Thanks to this scheme, our ConsisID generates high-quality, identity-preserving videos, making strides towards more effective IPT2V.
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
Nov 26, 2024Video Variational Autoencoder (VAE) encodes videos into a low-dimensional latent space, becoming a key component of most Latent Video Diffusion Models (LVDMs) to reduce model training costs. However, as the resolution and duration of generated videos increase, the encoding cost of Video VAEs becomes a limiting bottleneck in training LVDMs. Moreover, the block-wise inference method adopted by most LVDMs can lead to discontinuities of latent space when processing long-duration videos. The key to addressing the computational bottleneck lies in decomposing videos into distinct components and efficiently encoding the critical information. Wavelet transform can decompose videos into multiple frequency-domain components and improve the efficiency significantly, we thus propose Wavelet Flow VAE (WF-VAE), an autoencoder that leverages multi-level wavelet transform to facilitate low-frequency energy flow into latent representation. Furthermore, we introduce a method called Causal Cache, which maintains the integrity of latent space during block-wise inference. Compared to state-of-the-art video VAEs, WF-VAE demonstrates superior performance in both PSNR and LPIPS metrics, achieving 2x higher throughput and 4x lower memory consumption while maintaining competitive reconstruction quality. Our code and models are available at https://github.com/PKU-YuanGroup/WF-VAE.
OD-VAE: An Omni-dimensional Video Compressor for Improving Latent Video Diffusion Model
Sep 02, 2024Variational Autoencoder (VAE), compressing videos into latent representations, is a crucial preceding component of Latent Video Diffusion Models (LVDMs). With the same reconstruction quality, the more sufficient the VAE's compression for videos is, the more efficient the LVDMs are. However, most LVDMs utilize 2D image VAE, whose compression for videos is only in the spatial dimension and often ignored in the temporal dimension. How to conduct temporal compression for videos in a VAE to obtain more concise latent representations while promising accurate reconstruction is seldom explored. To fill this gap, we propose an omni-dimension compression VAE, named OD-VAE, which can temporally and spatially compress videos. Although OD-VAE's more sufficient compression brings a great challenge to video reconstruction, it can still achieve high reconstructed accuracy by our fine design. To obtain a better trade-off between video reconstruction quality and compression speed, four variants of OD-VAE are introduced and analyzed. In addition, a novel tail initialization is designed to train OD-VAE more efficiently, and a novel inference strategy is proposed to enable OD-VAE to handle videos of arbitrary length with limited GPU memory. Comprehensive experiments on video reconstruction and LVDM-based video generation demonstrate the effectiveness and efficiency of our proposed methods.