 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training
Jul 02, 2025Reinforcement learning (RL) has become a pivotal technology in the post-training phase of large language models (LLMs). Traditional task-colocated RL frameworks suffer from significant scalability bottlenecks, while task-separated RL frameworks face challenges in complex dataflows and the corresponding resource idling and workload imbalance. Moreover, most existing frameworks are tightly coupled with LLM training or inference engines, making it difficult to support custom-designed engines. To address these challenges, we propose AsyncFlow, an asynchronous streaming RL framework for efficient post-training. Specifically, we introduce a distributed data storage and transfer module that provides a unified data management and fine-grained scheduling capability in a fully streamed manner. This architecture inherently facilitates automated pipeline overlapping among RL tasks and dynamic load balancing. Moreover, we propose a producer-consumer-based asynchronous workflow engineered to minimize computational idleness by strategically deferring parameter update process within staleness thresholds. Finally, the core capability of AsynFlow is architecturally decoupled from underlying training and inference engines and encapsulated by service-oriented user interfaces, offering a modular and customizable user experience. Extensive experiments demonstrate an average of 1.59 throughput improvement compared with state-of-the-art baseline. The presented architecture in this work provides actionable insights for next-generation RL training system designs.
Towards Controllable and Photorealistic Region-wise Image Manipulation
Aug 19, 2021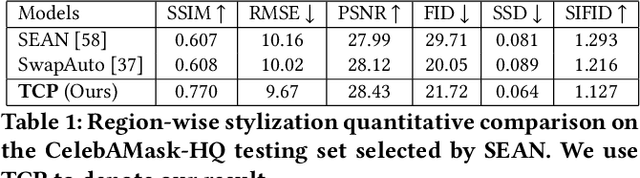
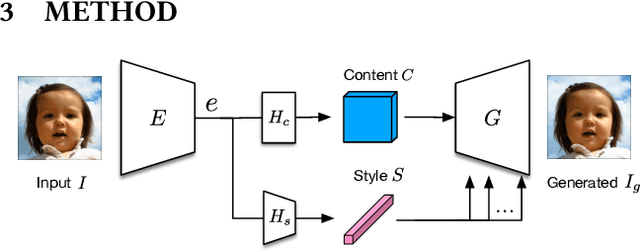


Adaptive and flexible image editing is a desirable function of modern generative models. In this work, we present a generative model with auto-encoder architecture for per-region style manipulation. We apply a code consistency loss to enforce an explicit disentanglement between content and style latent representations, making the content and style of generated samples consistent with their corresponding content and style references. The model is also constrained by a content alignment loss to ensure the foreground editing will not interfere background contents. As a result, given interested region masks provided by users, our model supports foreground region-wise style transfer. Specially, our model receives no extra annotations such as semantic labels except for self-supervision. Extensive experiments show the effectiveness of the proposed method and exhibit the flexibility of the proposed model for various applications, including region-wise style editing, latent space interpolation, cross-domain style transfer.
Towards Efficient Scene Understanding via Squeeze Reasoning
Nov 06, 2020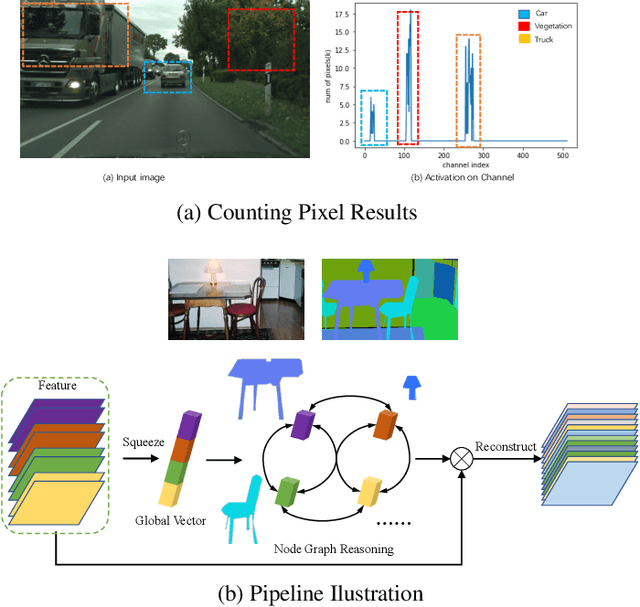

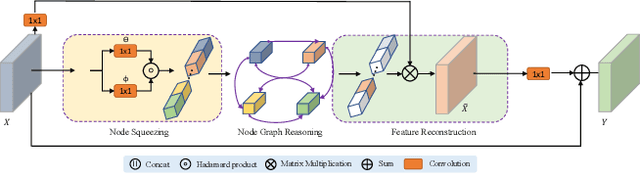
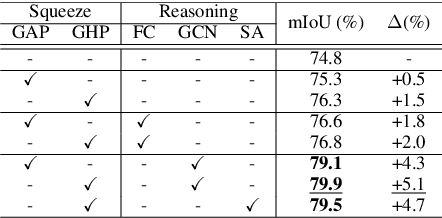
Graph-based convolutional model such as non-local block has shown to be effective for strengthening the context modeling ability in convolutional neural networks (CNNs). However, its pixel-wise computational overhead is prohibitive which renders it unsuitable for high resolution imagery. In this paper, we explore the efficiency of context graph reasoning and propose a novel framework called Squeeze Reasoning. Instead of propagating information on the spatial map, we first learn to squeeze the input feature into a channel-wise global vector and perform reasoning within the single vector where the computation cost can be significantly reduced. Specifically, we build the node graph in the vector where each node represents an abstract semantic concept. The refined feature within the same semantic category results to be consistent, which is thus beneficial for downstream tasks. We show that our approach can be modularized as an end-to-end trained block and can be easily plugged into existing networks. Despite its simplicity and being lightweight, our strategy allows us to establish a new state-of-the-art on semantic segmentation and show significant improvements with respect to strong, state-of-the-art baselines on various other scene understanding tasks including object detection, instance segmentation and panoptic segmentation. Code will be made available to foster any further research
Semantically Multi-modal Image Synthesis
Apr 02, 2020
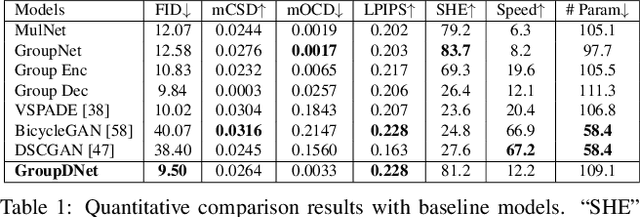
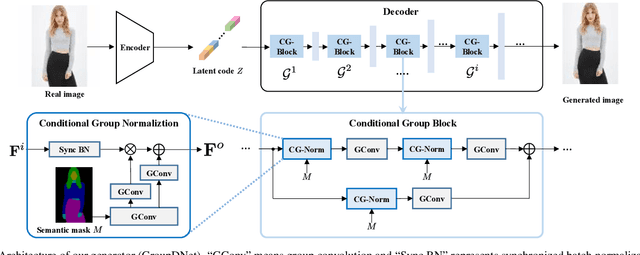

In this paper, we focus on semantically multi-modal image synthesis (SMIS) task, namely, generating multi-modal images at the semantic level. Previous work seeks to use multiple class-specific generators, constraining its usage in datasets with a small number of classes. We instead propose a novel Group Decreasing Network (GroupDNet) that leverages group convolutions in the generator and progressively decreases the group numbers of the convolutions in the decoder. Consequently, GroupDNet is armed with much more controllability on translating semantic labels to natural images and has plausible high-quality yields for datasets with many classes. Experiments on several challenging datasets demonstrate the superiority of GroupDNet on performing the SMIS task. We also show that GroupDNet is capable of performing a wide range of interesting synthesis applications. Codes and models are available at: https://github.com/Seanseattle/SMIS.
Semantic Flow for Fast and Accurate Scene Parsing
Feb 24, 2020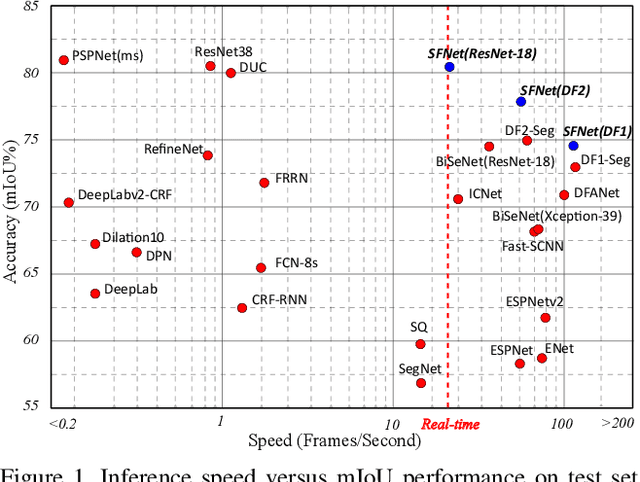
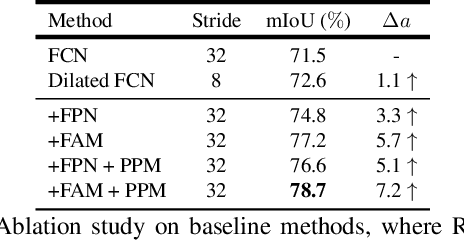
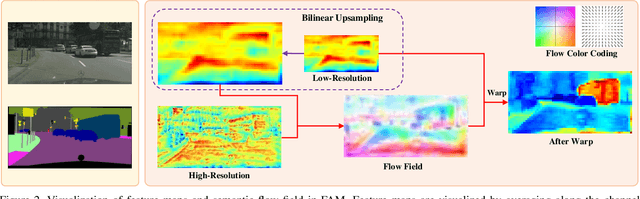
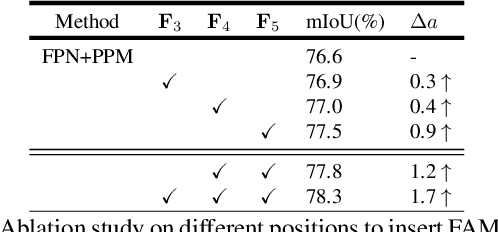
In this paper, we focus on effective methods for fast and accurate scene parsing. A common practice to improve the performance is to attain high resolution feature maps with strong semantic representation. Two strategies are widely used---astrous convolutions and feature pyramid fusion, are either computation intensive or ineffective. Inspired by Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn Semantic Flow between feature maps of adjacent levels and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our module to a common feature pyramid structure exhibits superior performance over other real-time methods even on very light-weight backbone networks, such as ResNet-18. Extensive experiments are conducted on several challenging datasets, including Cityscapes, PASCAL Context, ADE20K and CamVid. Particularly, our network is the first to achieve 80.4\% mIoU on Cityscapes with a frame rate of 26 FPS. The code will be available at \url{https://github.com/donnyyou/torchcv}.
Global Aggregation then Local Distribution in Fully Convolutional Networks
Sep 16, 2019
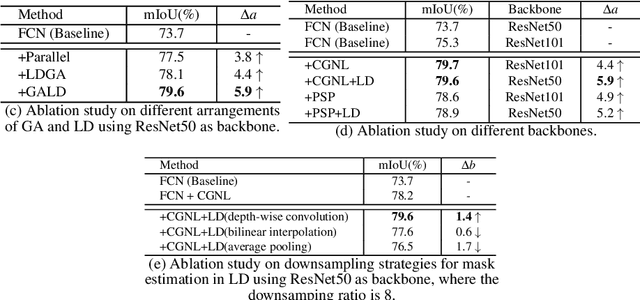
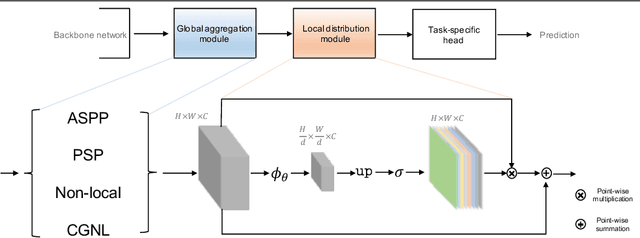

It has been widely proven that modelling long-range dependencies in fully convolutional networks (FCNs) via global aggregation modules is critical for complex scene understanding tasks such as semantic segmentation and object detection. However, global aggregation is often dominated by features of large patterns and tends to oversmooth regions that contain small patterns (e.g., boundaries and small objects). To resolve this problem, we propose to first use \emph{Global Aggregation} and then \emph{Local Distribution}, which is called GALD, where long-range dependencies are more confidently used inside large pattern regions and vice versa. The size of each pattern at each position is estimated in the network as a per-channel mask map. GALD is end-to-end trainable and can be easily plugged into existing FCNs with various global aggregation modules for a wide range of vision tasks, and consistently improves the performance of state-of-the-art object detection and instance segmentation approaches. In particular, GALD used in semantic segmentation achieves new state-of-the-art performance on Cityscapes test set with mIoU 83.3\%. Code is available at: \url{https://github.com/lxtGH/GALD-Net}
Reprojection R-CNN: A Fast and Accurate Object Detector for 360° Images
Jul 27, 2019
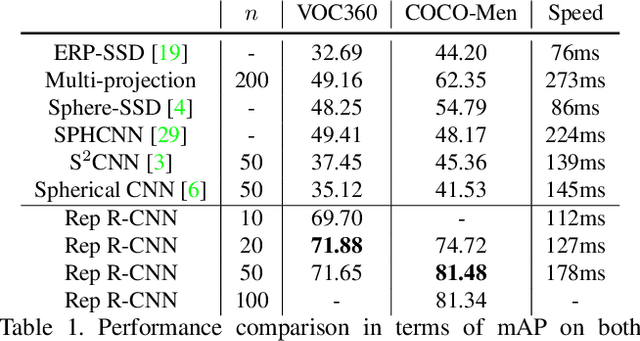
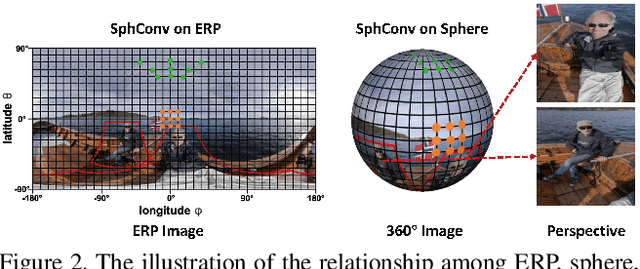
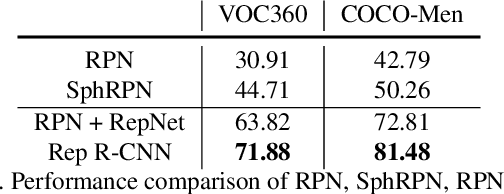
360{\deg} images are usually represented in either equirectangular projection (ERP) or multiple perspective projections. Different from the flat 2D images, the detection task is challenging for 360{\deg} images due to the distortion of ERP and the inefficiency of perspective projections. However, existing methods mostly focus on one of the above representations instead of both, leading to limited detection performance. Moreover, the lack of appropriate bounding-box annotations as well as the annotated datasets further increases the difficulties of the detection task. In this paper, we present a standard object detection framework for 360{\deg} images. Specifically, we adapt the terminologies of the traditional object detection task to the omnidirectional scenarios, and propose a novel two-stage object detector, i.e., Reprojection R-CNN by combining both ERP and perspective projection. Owing to the omnidirectional field-of-view of ERP, Reprojection R-CNN first generates coarse region proposals efficiently by a distortion-aware spherical region proposal network. Then, it leverages the distortion-free perspective projection and refines the proposed regions by a novel reprojection network. We construct two novel synthetic datasets for training and evaluation. Experiments reveal that Reprojection R-CNN outperforms the previous state-of-the-art methods on the mAP metric. In addition, the proposed detector could run at 178ms per image in the panoramic datasets, which implies its practicability in real-world applications.