 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Aggregation then Local Distribution in Fully Convolutional Networks
Paper and Code

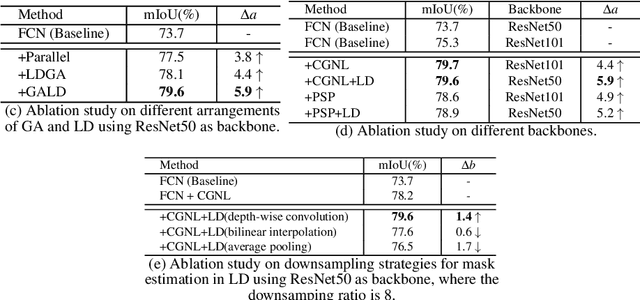
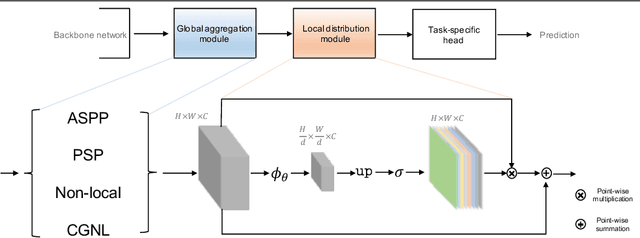

It has been widely proven that modelling long-range dependencies in fully convolutional networks (FCNs) via global aggregation modules is critical for complex scene understanding tasks such as semantic segmentation and object detection. However, global aggregation is often dominated by features of large patterns and tends to oversmooth regions that contain small patterns (e.g., boundaries and small objects). To resolve this problem, we propose to first use \emph{Global Aggregation} and then \emph{Local Distribution}, which is called GALD, where long-range dependencies are more confidently used inside large pattern regions and vice versa. The size of each pattern at each position is estimated in the network as a per-channel mask map. GALD is end-to-end trainable and can be easily plugged into existing FCNs with various global aggregation modules for a wide range of vision tasks, and consistently improves the performance of state-of-the-art object detection and instance segmentation approaches. In particular, GALD used in semantic segmentation achieves new state-of-the-art performance on Cityscapes test set with mIoU 83.3\%. Code is available at: \url{https://github.com/lxtGH/GALD-Net}