 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Flow for Fast and Accurate Scene Parsing
Paper and Code
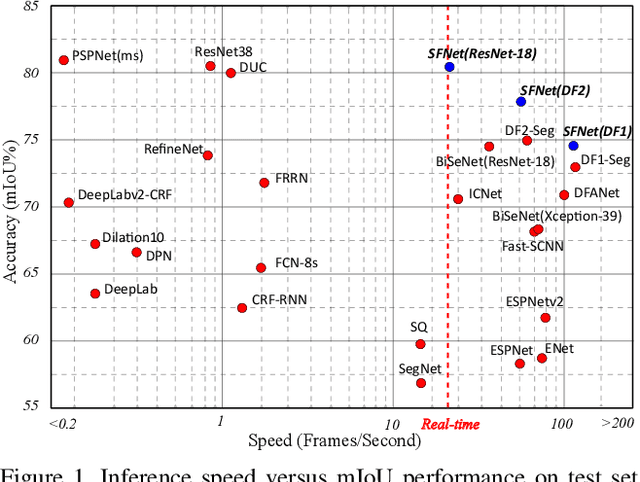
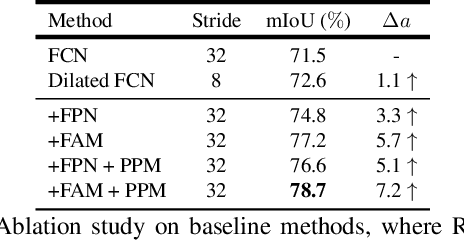
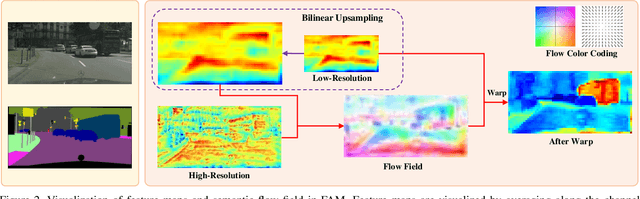
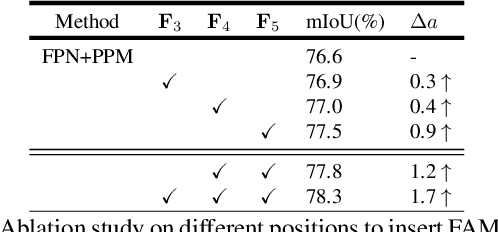
In this paper, we focus on effective methods for fast and accurate scene parsing. A common practice to improve the performance is to attain high resolution feature maps with strong semantic representation. Two strategies are widely used---astrous convolutions and feature pyramid fusion, are either computation intensive or ineffective. Inspired by Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn Semantic Flow between feature maps of adjacent levels and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our module to a common feature pyramid structure exhibits superior performance over other real-time methods even on very light-weight backbone networks, such as ResNet-18. Extensive experiments are conducted on several challenging datasets, including Cityscapes, PASCAL Context, ADE20K and CamVid. Particularly, our network is the first to achieve 80.4\% mIoU on Cityscapes with a frame rate of 26 FPS. The code will be available at \url{https://github.com/donnyyou/torchcv}.