 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtemis: Articulated Neural Pets with Appearance and Motion synthesis
Feb 11, 2022
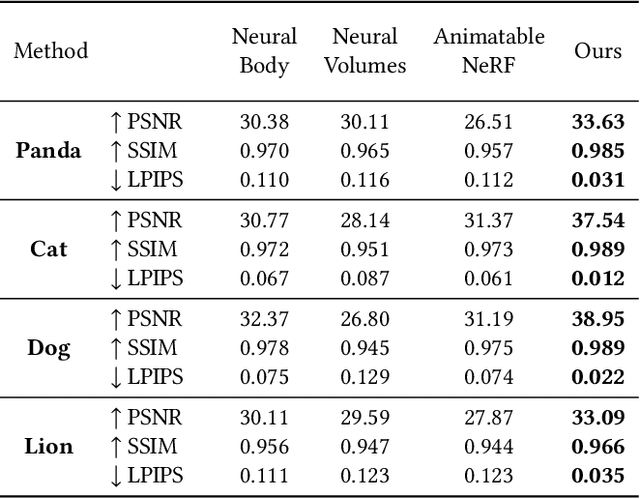
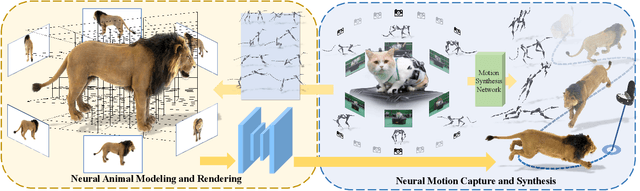
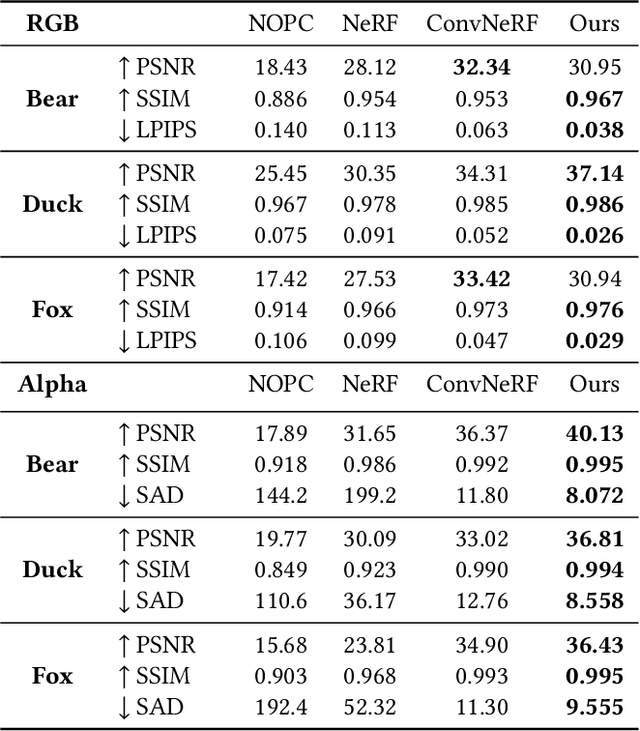
We human are entering into a virtual era, and surely want to bring animals to virtual world as well for companion. Yet, computer-generated (CGI) furry animals is limited by tedious off-line rendering, let alone interactive motion control. In this paper, we present ARTEMIS, a novel neural modeling and rendering pipeline for generating ARTiculated neural pets with appEarance and Motion synthesIS. Our ARTEMIS enables interactive motion control, real-time animation and photo-realistic rendering of furry animals. The core of ARTEMIS is a neural-generated (NGI) animal engine, which adopts an efficient octree based representation for animal animation and fur rendering. The animation then becomes equivalent to voxel level skeleton based deformation. We further use a fast octree indexing, an efficient volumetric rendering scheme to generate appearance and density features maps. Finally, we propose a novel shading network to generate high-fidelity details of appearance and opacity under novel poses. For the motion control module in ARTEMIS, we combine state-of-the-art animal motion capture approach with neural character control scheme. We introduce an effective optimization scheme to reconstruct skeletal motion of real animals captured by a multi-view RGB and Vicon camera array. We feed the captured motion into a neural character control scheme to generate abstract control signals with motion styles. We further integrate ARTEMIS into existing engines that support VR headsets, providing an unprecedented immersive experience where a user can intimately interact with a variety of virtual animals with vivid movements and photo-realistic appearance. Extensive experiments and showcases demonstrate the effectiveness of our ARTEMIS system to achieve highly realistic rendering of NGI animals in real-time, providing daily immersive and interactive experience with digital animals unseen before.
Towards Controllable and Photorealistic Region-wise Image Manipulation
Aug 19, 2021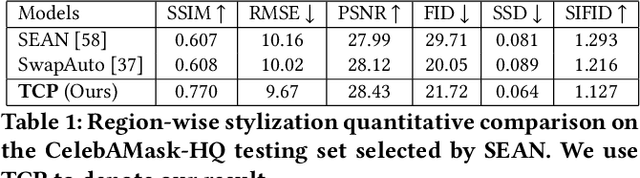
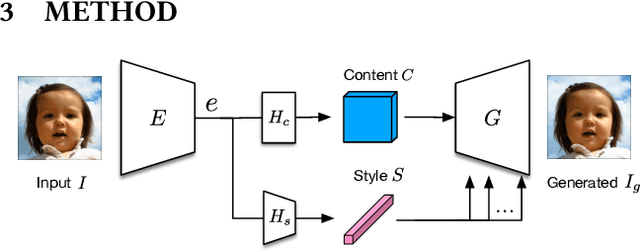


Adaptive and flexible image editing is a desirable function of modern generative models. In this work, we present a generative model with auto-encoder architecture for per-region style manipulation. We apply a code consistency loss to enforce an explicit disentanglement between content and style latent representations, making the content and style of generated samples consistent with their corresponding content and style references. The model is also constrained by a content alignment loss to ensure the foreground editing will not interfere background contents. As a result, given interested region masks provided by users, our model supports foreground region-wise style transfer. Specially, our model receives no extra annotations such as semantic labels except for self-supervision. Extensive experiments show the effectiveness of the proposed method and exhibit the flexibility of the proposed model for various applications, including region-wise style editing, latent space interpolation, cross-domain style transfer.