 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliCARE: Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records
Jul 30, 2025Large Language Models (LLMs) hold significant promise for improving clinical decision support and reducing physician burnout by synthesizing complex, longitudinal cancer Electronic Health Records (EHRs). However, their implementation in this critical field faces three primary challenges: the inability to effectively process the extensive length and multilingual nature of patient records for accurate temporal analysis; a heightened risk of clinical hallucination, as conventional grounding techniques such as Retrieval-Augmented Generation (RAG) do not adequately incorporate process-oriented clinical guidelines; and unreliable evaluation metrics that hinder the validation of AI systems in oncology. To address these issues, we propose CliCARE, a framework for Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records. The framework operates by transforming unstructured, longitudinal EHRs into patient-specific Temporal Knowledge Graphs (TKGs) to capture long-range dependencies, and then grounding the decision support process by aligning these real-world patient trajectories with a normative guideline knowledge graph. This approach provides oncologists with evidence-grounded decision support by generating a high-fidelity clinical summary and an actionable recommendation. We validated our framework using large-scale, longitudinal data from a private Chinese cancer dataset and the public English MIMIC-IV dataset. In these diverse settings, CliCARE significantly outperforms strong baselines, including leading long-context LLMs and Knowledge Graph-enhanced RAG methods. The clinical validity of our results is supported by a robust evaluation protocol, which demonstrates a high correlation with assessments made by expert oncologists.
A Survey on Enhancing Causal Reasoning Ability of Large Language Models
Mar 12, 2025Large language models (LLMs) have recently shown remarkable performance in language tasks and beyond. However, due to their limited inherent causal reasoning ability, LLMs still face challenges in handling tasks that require robust causal reasoning ability, such as health-care and economic analysis. As a result, a growing body of research has focused on enhancing the causal reasoning ability of LLMs. Despite the booming research, there lacks a survey to well review the challenges, progress and future directions in this area. To bridge this significant gap, we systematically review literature on how to strengthen LLMs' causal reasoning ability in this paper. We start from the introduction of background and motivations of this topic, followed by the summarisation of key challenges in this area. Thereafter, we propose a novel taxonomy to systematically categorise existing methods, together with detailed comparisons within and between classes of methods. Furthermore, we summarise existing benchmarks and evaluation metrics for assessing LLMs' causal reasoning ability. Finally, we outline future research directions for this emerging field, offering insights and inspiration to researchers and practitioners in the area.
Continuity Preserving Online CenterLine Graph Learning
Jul 16, 2024



Lane topology, which is usually modeled by a centerline graph, is essential for high-level autonomous driving. For a high-quality graph, both topology connectivity and spatial continuity of centerline segments are critical. However, most of existing approaches pay more attention to connectivity while neglect the continuity. Such kind of centerline graph usually cause problem to planning of autonomous driving. To overcome this problem, we present an end-to-end network, CGNet, with three key modules: 1)Junction Aware Query Enhancement module, which provides positional prior to accurately predict junction points; 2)B\'ezier Space Connection module, which enforces continuity constraints on any two topologically connected segments in a B\'ezier space; 3) Iterative Topology Refinement module, which is a graph-based network with memory to iteratively refine the predicted topological connectivity. CGNet achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets.
Adaptive Frequency Learning in Two-branch Face Forgery Detection
Mar 27, 2022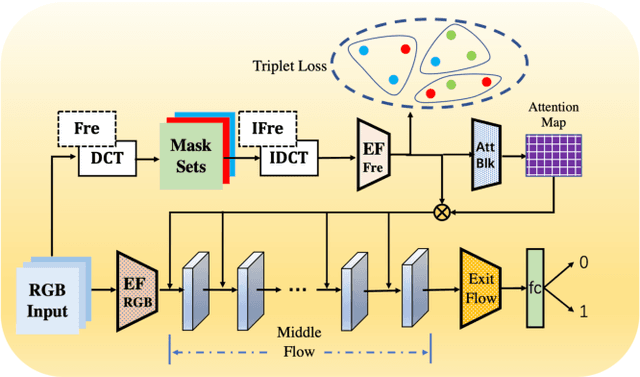
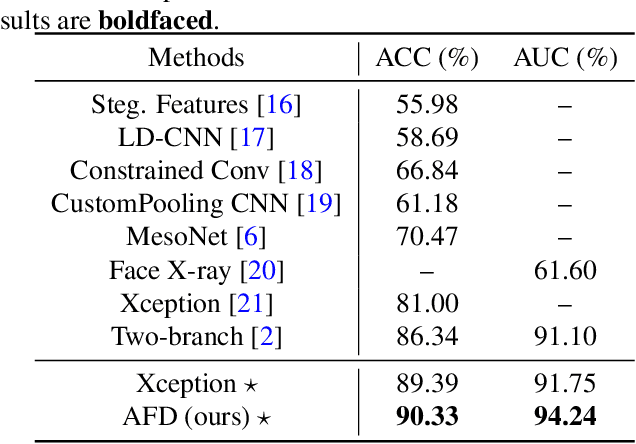
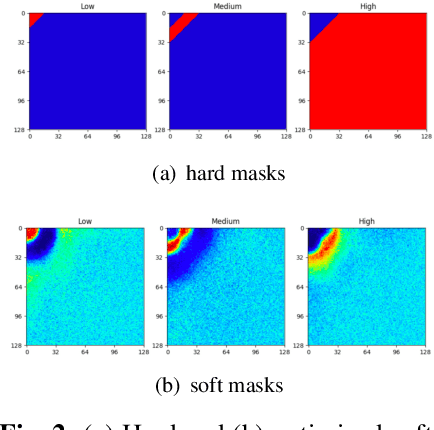
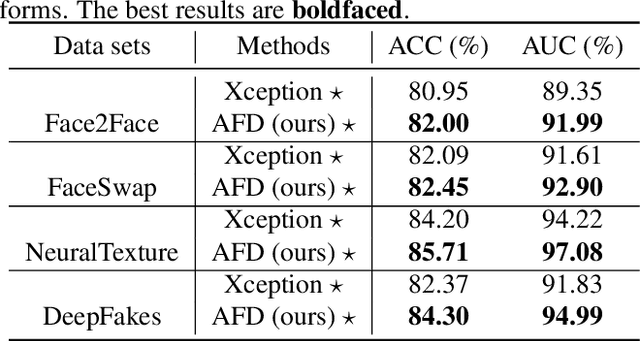
Face forgery has attracted increasing attention in recent applications of computer vision. Existing detection techniques using the two-branch framework benefit a lot from a frequency perspective, yet are restricted by their fixed frequency decomposition and transform. In this paper, we propose to Adaptively learn Frequency information in the two-branch Detection framework, dubbed AFD. To be specific, we automatically learn decomposition in the frequency domain by introducing heterogeneity constraints, and propose an attention-based module to adaptively incorporate frequency features into spatial clues. Then we liberate our network from the fixed frequency transforms, and achieve better performance with our data- and task-dependent transform layers. Extensive experiments show that AFD generally outperforms.
Multi-View Fusion Transformer for Sensor-Based Human Activity Recognition
Feb 16, 2022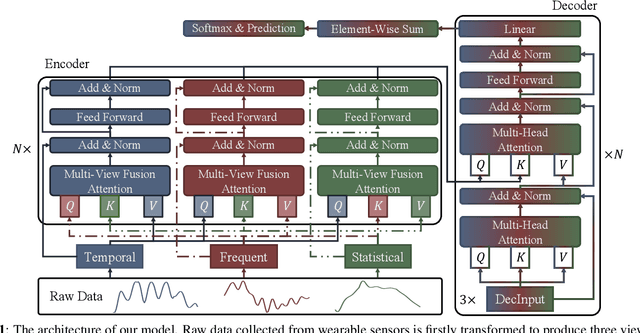


As a fundamental problem in ubiquitous computing and machine learning, sensor-based human activity recognition (HAR) has drawn extensive attention and made great progress in recent years. HAR aims to recognize human activities based on the availability of rich time-series data collected from multi-modal sensors such as accelerometers and gyroscopes. However, recent deep learning methods are focusing on one view of the data, i.e., the temporal view, while shallow methods tend to utilize the hand-craft features for recognition, e.g., the statistics view. In this paper, to extract a better feature for advancing the performance, we propose a novel method, namely multi-view fusion transformer (MVFT) along with a novel attention mechanism. First, MVFT encodes three views of information, i.e., the temporal, frequent, and statistical views to generate multi-view features. Second, the novel attention mechanism uncovers inner- and cross-view clues to catalyze mutual interactions between three views for detailed relation modeling. Moreover, extensive experiments on two datasets illustrate the superiority of our methods over several state-of-the-art methods.
Variational Co-embedding Learning for Attributed Network Clustering
Apr 15, 2021
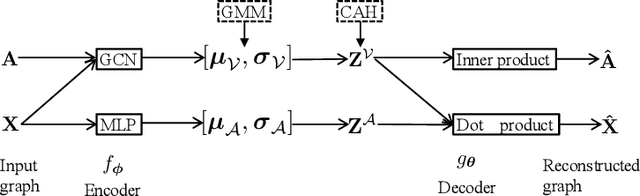
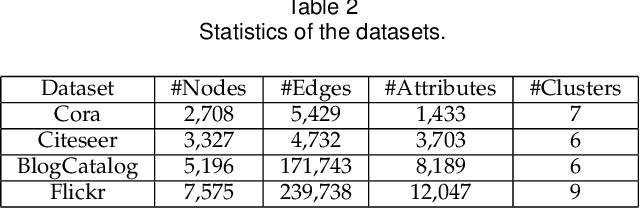
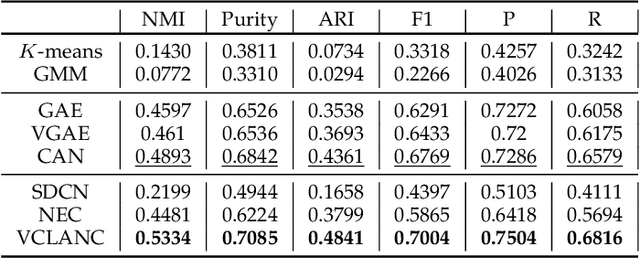
Recent works for attributed network clustering utilize graph convolution to obtain node embeddings and simultaneously perform clustering assignments on the embedding space. It is effective since graph convolution combines the structural and attributive information for node embedding learning. However, a major limitation of such works is that the graph convolution only incorporates the attribute information from the local neighborhood of nodes but fails to exploit the mutual affinities between nodes and attributes. In this regard, we propose a variational co-embedding learning model for attributed network clustering (VCLANC). VCLANC is composed of dual variational auto-encoders to simultaneously embed nodes and attributes. Relying on this, the mutual affinity information between nodes and attributes could be reconstructed from the embedding space and served as extra self-supervised knowledge for representation learning. At the same time, trainable Gaussian mixture model is used as priors to infer the node clustering assignments. To strengthen the performance of the inferred clusters, we use a mutual distance loss on the centers of the Gaussian priors and a clustering assignment hardening loss on the node embeddings. Experimental results on four real-world attributed network datasets demonstrate the effectiveness of the proposed VCLANC for attributed network clustering.
Feature-metric Loss for Self-supervised Learning of Depth and Egomotion
Jul 21, 2020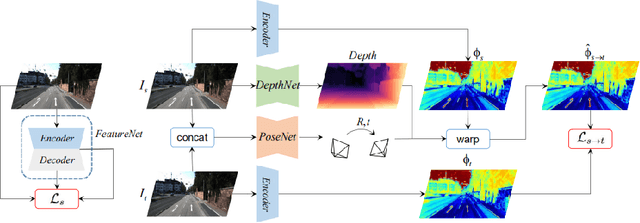



Photometric loss is widely used for self-supervised depth and egomotion estimation. However, the loss landscapes induced by photometric differences are often problematic for optimization, caused by plateau landscapes for pixels in textureless regions or multiple local minima for less discriminative pixels. In this work, feature-metric loss is proposed and defined on feature representation, where the feature representation is also learned in a self-supervised manner and regularized by both first-order and second-order derivatives to constrain the loss landscapes to form proper convergence basins. Comprehensive experiments and detailed analysis via visualization demonstrate the effectiveness of the proposed feature-metric loss. In particular, our method improves state-of-the-art methods on KITTI from 0.885 to 0.925 measured by $\delta_1$ for depth estimation, and significantly outperforms previous method for visual odometry.
Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching
Sep 09, 2019

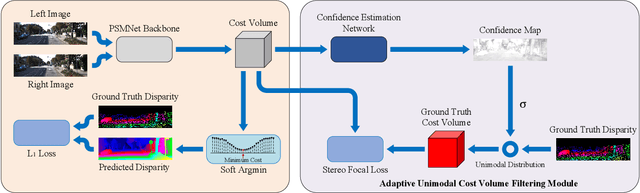
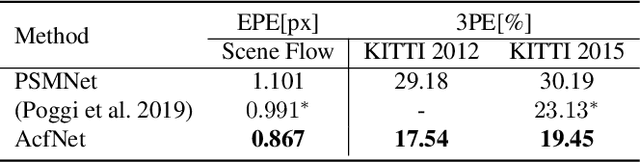
State-of-the-art deep learning based stereo matching approaches treat disparity estimation as a regression problem, where loss function is directly defined on true disparities and their estimated ones. However, disparity is just a byproduct of a matching process modeled by cost volume, while indirectly learning cost volume driven by disparity regression is prone to overfitting since cost volume is under constrained. In this paper, we propose to directly add constraints to the cost volume by filtering cost volume with unimodal distribution peaked at true disparities. In addition, variances of the unimodal distributions for each pixel are estimated to explicitly model matching uncertainty under different contexts. The proposed architecture achieves state-of-the-art performance on Scene Flow and two KITTI stereo benchmarks. In particular, our method ranked the $1^{st}$ place of KITTI 2012 evaluation and the $4^{th}$ place of KITTI 2015 evaluation (recorded on 2019.8.20).