 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Fusion Transformer for Sensor-Based Human Activity Recognition
Paper and Code
Feb 16, 2022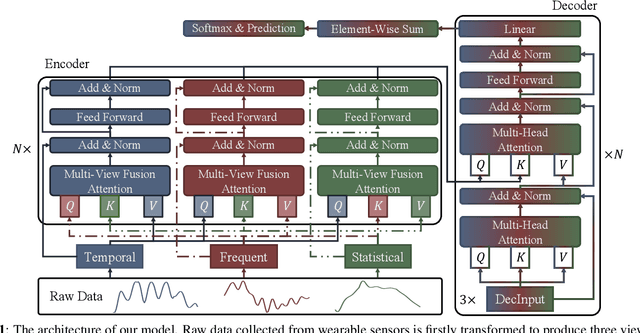


As a fundamental problem in ubiquitous computing and machine learning, sensor-based human activity recognition (HAR) has drawn extensive attention and made great progress in recent years. HAR aims to recognize human activities based on the availability of rich time-series data collected from multi-modal sensors such as accelerometers and gyroscopes. However, recent deep learning methods are focusing on one view of the data, i.e., the temporal view, while shallow methods tend to utilize the hand-craft features for recognition, e.g., the statistics view. In this paper, to extract a better feature for advancing the performance, we propose a novel method, namely multi-view fusion transformer (MVFT) along with a novel attention mechanism. First, MVFT encodes three views of information, i.e., the temporal, frequent, and statistical views to generate multi-view features. Second, the novel attention mechanism uncovers inner- and cross-view clues to catalyze mutual interactions between three views for detailed relation modeling. Moreover, extensive experiments on two datasets illustrate the superiority of our methods over several state-of-the-art methods.