 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Reparameterized Importance Weighted Structure Learning for Scene Graph Generation
Jun 22, 2022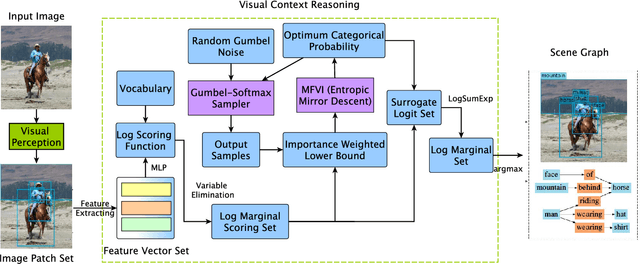
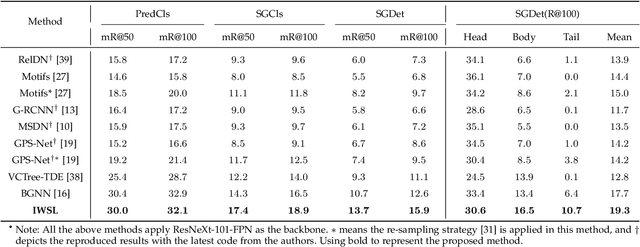
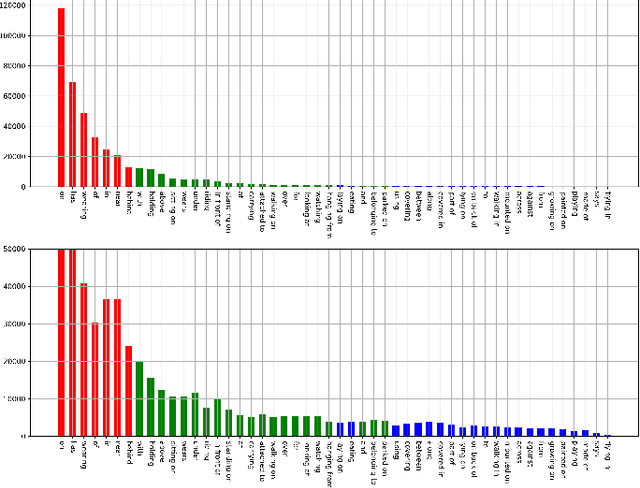
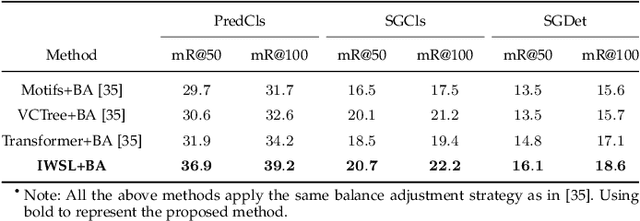
As a structured prediction task, scene graph generation, given an input image, aims to explicitly model objects and their relationships by constructing a visually-grounded scene graph. In the current literature, such task is universally solved via a message passing neural network based mean field variational Bayesian methodology. The classical loose evidence lower bound is generally chosen as the variational inference objective, which could induce oversimplified variational approximation and thus underestimate the underlying complex posterior. In this paper, we propose a novel doubly reparameterized importance weighted structure learning method, which employs a tighter importance weighted lower bound as the variational inference objective. It is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler and the resulting constrained variational inference task is solved by a generic entropic mirror descent algorithm. The resulting doubly reparameterized gradient estimator reduces the variance of the corresponding derivatives with a beneficial impact on learning. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
Subcellular Protein Localisation in the Human Protein Atlas using Ensembles of Diverse Deep Architectures
May 19, 2022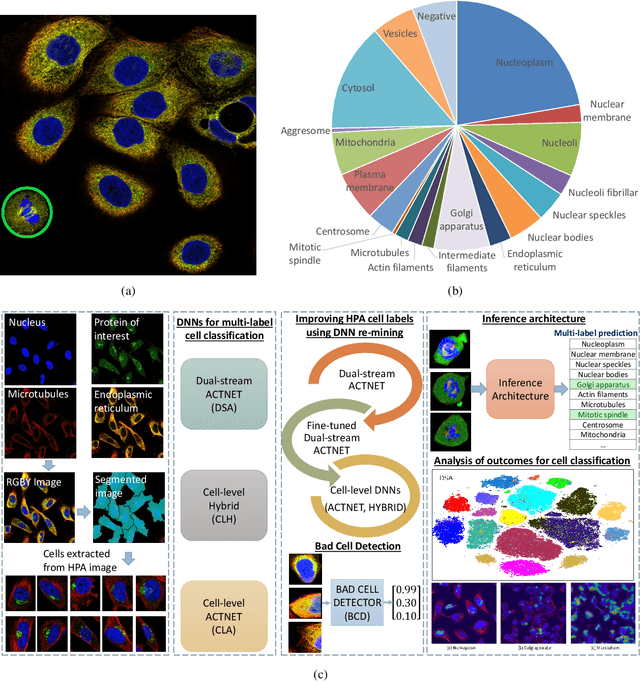
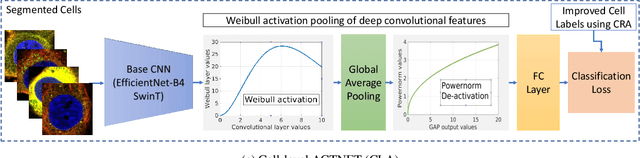
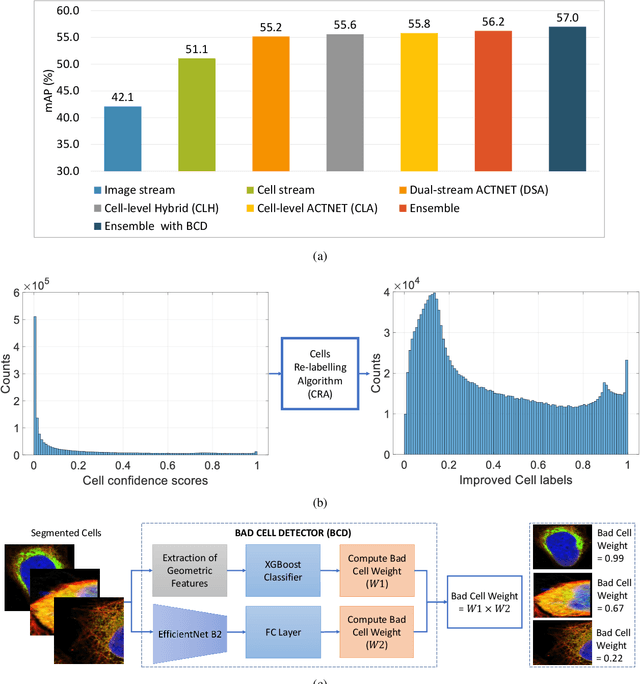
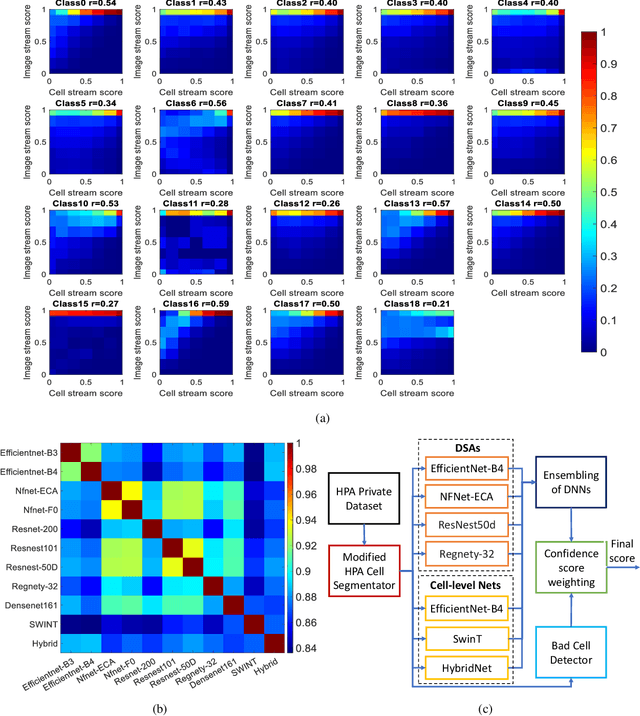
Automated visual localisation of subcellular proteins can accelerate our understanding of cell function in health and disease. Despite recent advances in machine learning (ML), humans still attain superior accuracy by using diverse clues. We show how this gap can be narrowed by addressing three key aspects: (i) automated improvement of cell annotation quality, (ii) new Convolutional Neural Network (CNN) architectures supporting unbalanced and noisy data, and (iii) informed selection and fusion of multiple & diverse machine learning models. We introduce a new "AI-trains-AI" method for improving the quality of weak labels and propose novel CNN architectures exploiting wavelet filters and Weibull activations. We also explore key factors in the multi-CNN ensembling process by analysing correlations between image-level and cell-level predictions. Finally, in the context of the Human Protein Atlas, we demonstrate that our system achieves state-of-the-art performance in the multi-label single-cell classification of protein localisation patterns. It also significantly improves generalisation ability.
Importance Weighted Structure Learning for Scene Graph Generation
May 14, 2022Scene graph generation is a structured prediction task aiming to explicitly model objects and their relationships via constructing a visually-grounded scene graph for an input image. Currently, the message passing neural network based mean field variational Bayesian methodology is the ubiquitous solution for such a task, in which the variational inference objective is often assumed to be the classical evidence lower bound. However, the variational approximation inferred from such loose objective generally underestimates the underlying posterior, which often leads to inferior generation performance. In this paper, we propose a novel importance weighted structure learning method aiming to approximate the underlying log-partition function with a tighter importance weighted lower bound, which is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler. A generic entropic mirror descent algorithm is applied to solve the resulting constrained variational inference task. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
Efficient Hybrid Network: Inducting Scattering Features
Mar 29, 2022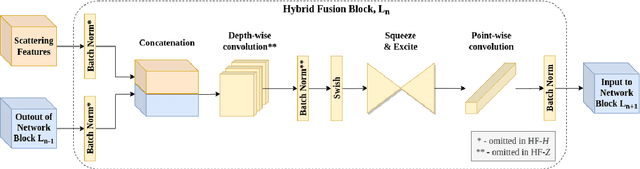
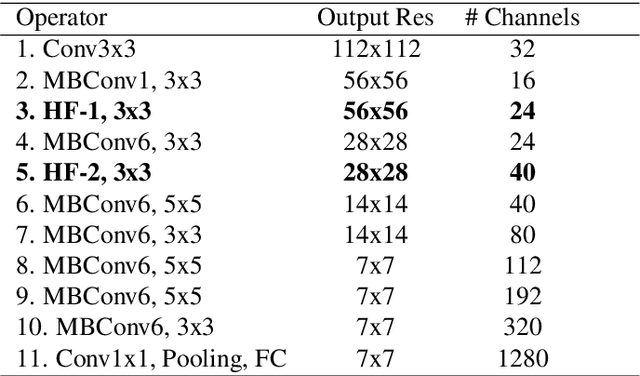
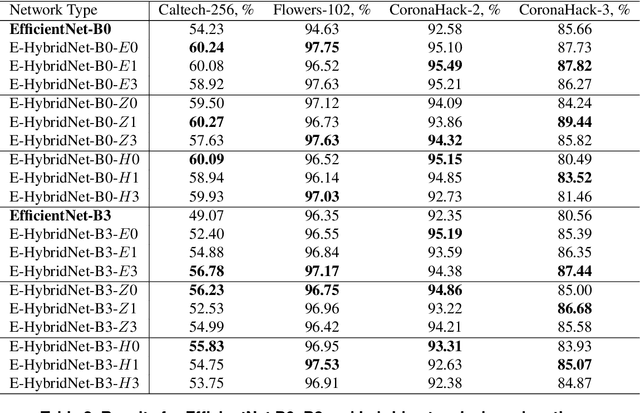
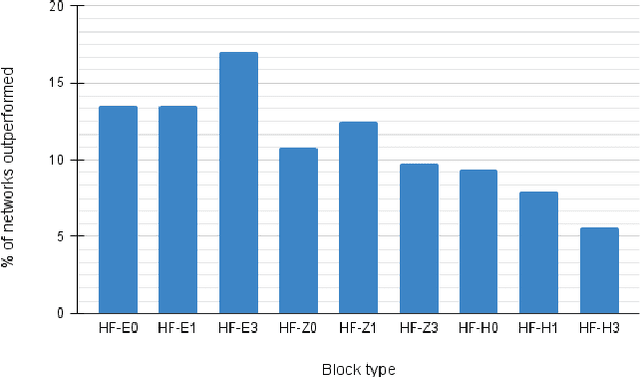
Recent work showed that hybrid networks, which combine predefined and learnt filters within a single architecture, are more amenable to theoretical analysis and less prone to overfitting in data-limited scenarios. However, their performance has yet to prove competitive against the conventional counterparts when sufficient amounts of training data are available. In an attempt to address this core limitation of current hybrid networks, we introduce an Efficient Hybrid Network (E-HybridNet). We show that it is the first scattering based approach that consistently outperforms its conventional counterparts on a diverse range of datasets. It is achieved with a novel inductive architecture that embeds scattering features into the network flow using Hybrid Fusion Blocks. We also demonstrate that the proposed design inherits the key property of prior hybrid networks -- an effective generalisation in data-limited scenarios. Our approach successfully combines the best of the two worlds: flexibility and power of learnt features and stability and predictability of scattering representations.
Constrained Structure Learning for Scene Graph Generation
Jan 27, 2022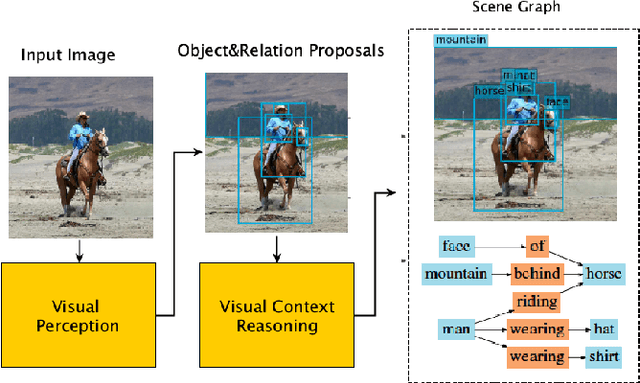
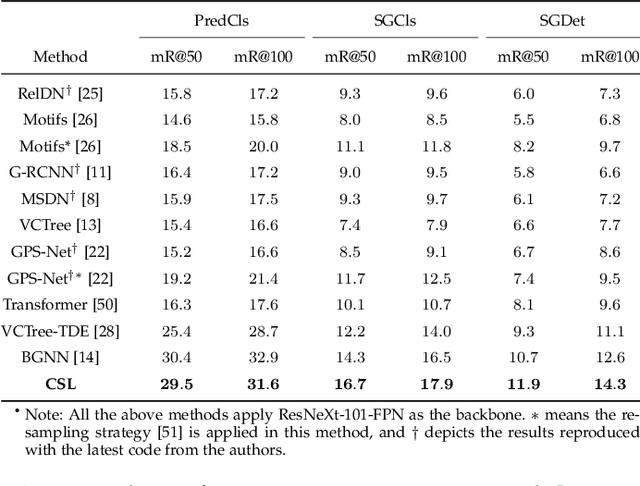
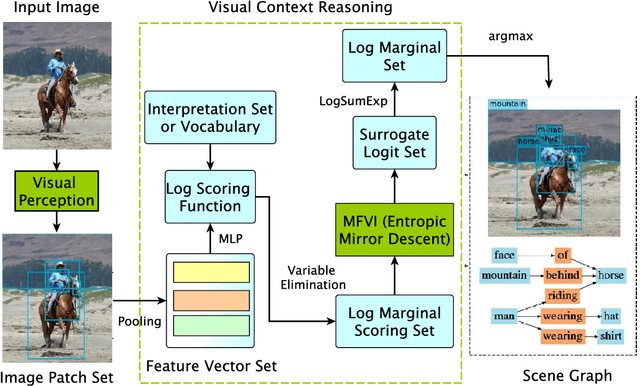
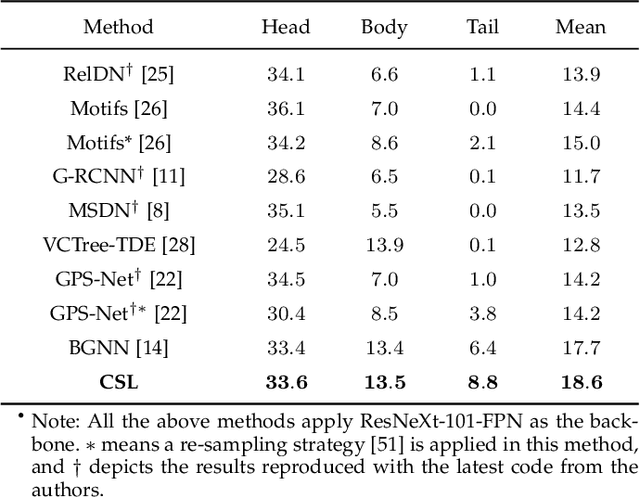
As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.
Neural Belief Propagation for Scene Graph Generation
Dec 10, 2021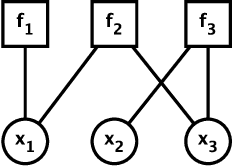
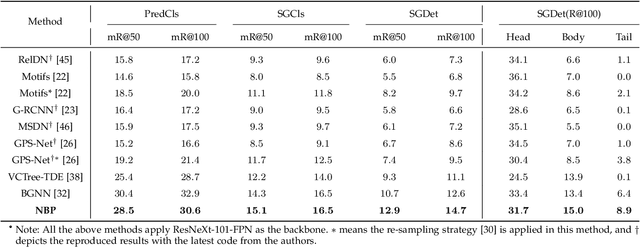
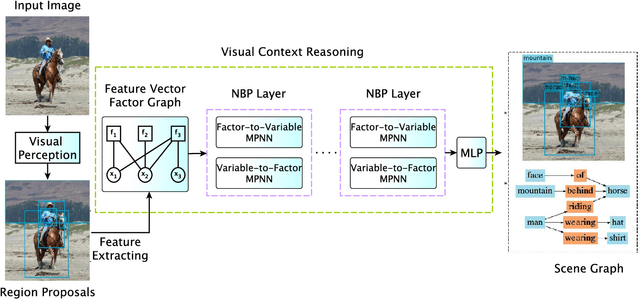
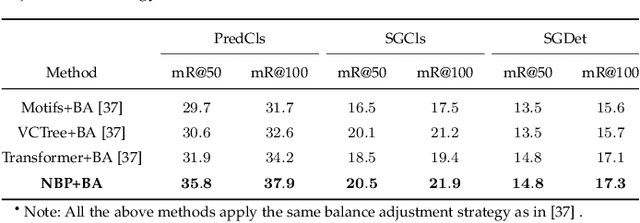
Scene graph generation aims to interpret an input image by explicitly modelling the potential objects and their relationships, which is predominantly solved by the message passing neural network models in previous methods. Currently, such approximation models generally assume the output variables are totally independent and thus ignore the informative structural higher-order interactions. This could lead to the inconsistent interpretations for an input image. In this paper, we propose a novel neural belief propagation method to generate the resulting scene graph. It employs a structural Bethe approximation rather than the mean field approximation to infer the associated marginals. To find a better bias-variance trade-off, the proposed model not only incorporates pairwise interactions but also higher order interactions into the associated scoring function. It achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
Learning PAC-Bayes Priors for Probabilistic Neural Networks
Sep 21, 2021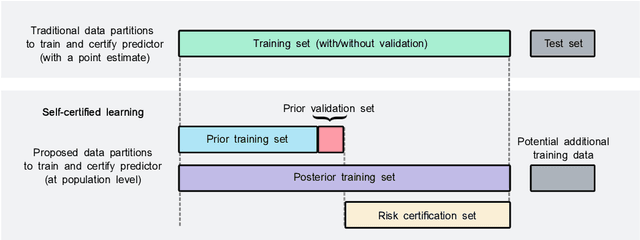
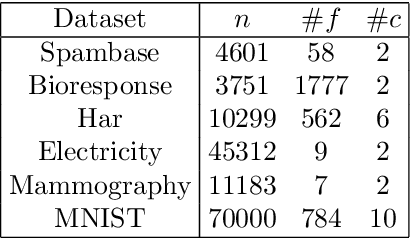
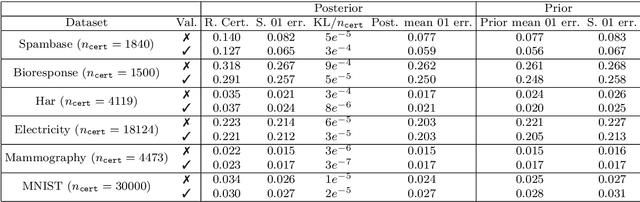
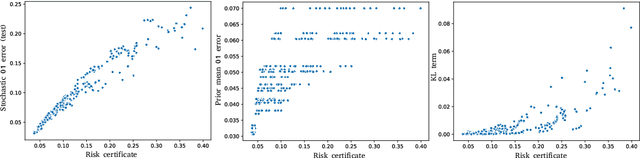
Recent works have investigated deep learning models trained by optimising PAC-Bayes bounds, with priors that are learnt on subsets of the data. This combination has been shown to lead not only to accurate classifiers, but also to remarkably tight risk certificates, bearing promise towards self-certified learning (i.e. use all the data to learn a predictor and certify its quality). In this work, we empirically investigate the role of the prior. We experiment on 6 datasets with different strategies and amounts of data to learn data-dependent PAC-Bayes priors, and we compare them in terms of their effect on test performance of the learnt predictors and tightness of their risk certificate. We ask what is the optimal amount of data which should be allocated for building the prior and show that the optimum may be dataset dependent. We demonstrate that using a small percentage of the prior-building data for validation of the prior leads to promising results. We include a comparison of underparameterised and overparameterised models, along with an empirical study of different training objectives and regularisation strategies to learn the prior distribution.
Understanding the Distributions of Aggregation Layers in Deep Neural Networks
Jul 09, 2021

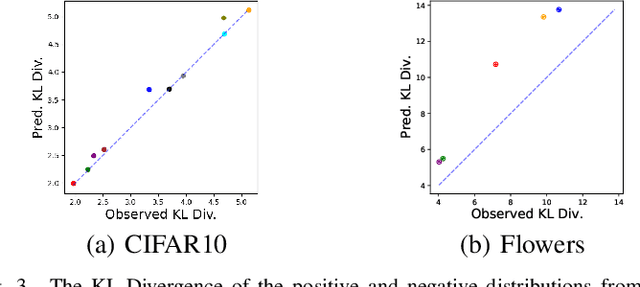
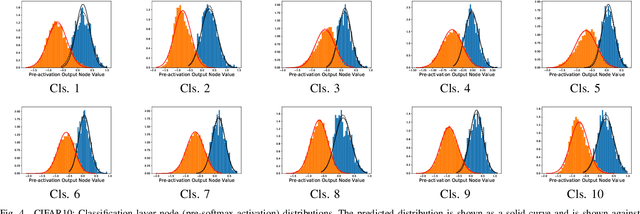
The process of aggregation is ubiquitous in almost all deep nets models. It functions as an important mechanism for consolidating deep features into a more compact representation, whilst increasing robustness to overfitting and providing spatial invariance in deep nets. In particular, the proximity of global aggregation layers to the output layers of DNNs mean that aggregated features have a direct influence on the performance of a deep net. A better understanding of this relationship can be obtained using information theoretic methods. However, this requires the knowledge of the distributions of the activations of aggregation layers. To achieve this, we propose a novel mathematical formulation for analytically modelling the probability distributions of output values of layers involved with deep feature aggregation. An important outcome is our ability to analytically predict the KL-divergence of output nodes in a DNN. We also experimentally verify our theoretical predictions against empirical observations across a range of different classification tasks and datasets.
ACTNET: end-to-end learning of feature activations and multi-stream aggregation for effective instance image retrieval
Jul 18, 2019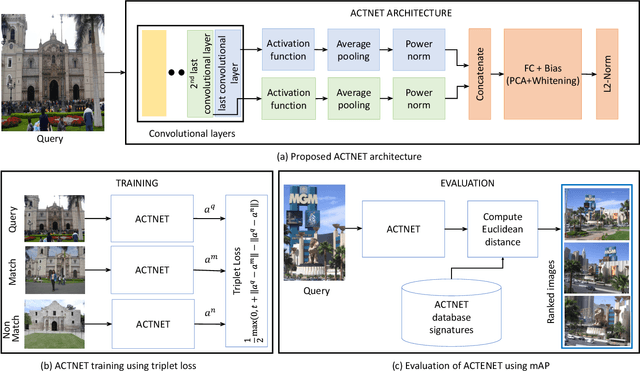
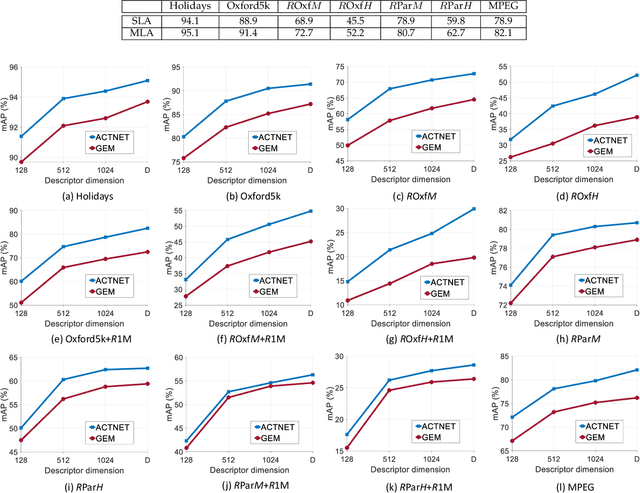
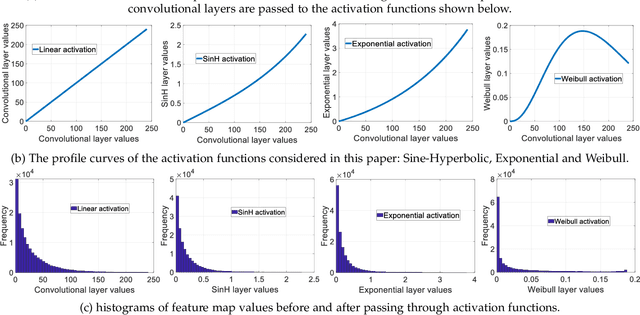

We propose a novel CNN architecture called ACTNET for robust instance image retrieval from large-scale datasets. Our key innovation is a learnable activation layer designed to improve the signal-to-noise ratio (SNR) of deep convolutional feature maps. Further, we introduce a controlled multi-stream aggregation, where complementary deep features from different convolutional layers are optimally transformed and balanced using our novel activation layers, before aggregation into a global descriptor. Importantly, the learnable parameters of our activation blocks are explicitly trained, together with the CNN parameters, in an end-to-end manner minimising triplet loss. This means that our network jointly learns the CNN filters and their optimal activation and aggregation for retrieval tasks. To our knowledge, this is the first time parametric functions have been used to control and learn optimal aggregation. We conduct an in-depth experimental study on three non-linear activation functions: Sine-Hyperbolic, Exponential and modified Weibull, showing that while all bring significant gains the Weibull function performs best thanks to its ability to equalise strong activations. The results clearly demonstrate that our ACTNET architecture significantly enhances the discriminative power of deep features, improving significantly over the state-of-the-art retrieval results on all datasets.
REMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval
Jun 15, 2019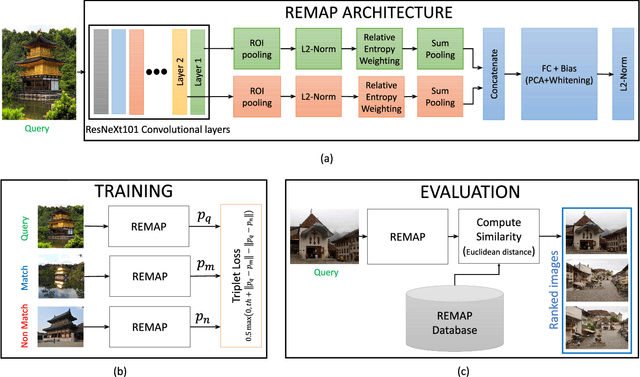
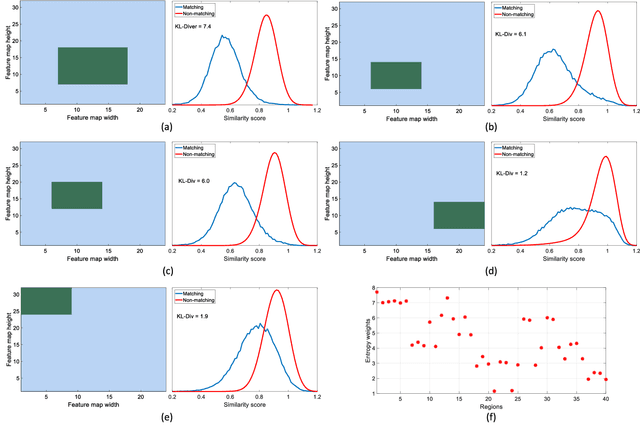

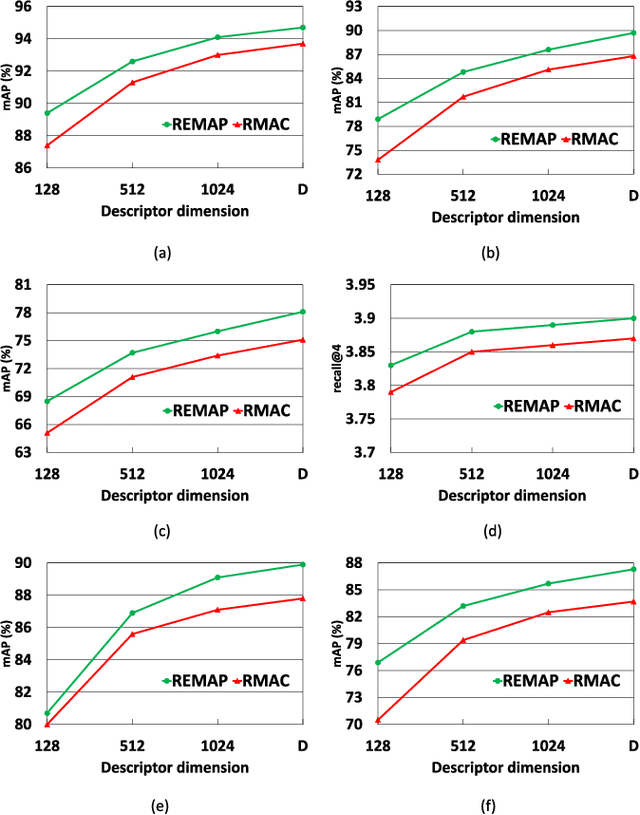
This paper addresses the problem of very large-scale image retrieval, focusing on improving its accuracy and robustness. We target enhanced robustness of search to factors such as variations in illumination, object appearance and scale, partial occlusions, and cluttered backgrounds - particularly important when search is performed across very large datasets with significant variability. We propose a novel CNN-based global descriptor, called REMAP, which learns and aggregates a hierarchy of deep features from multiple CNN layers, and is trained end-to-end with a triplet loss. REMAP explicitly learns discriminative features which are mutually-supportive and complementary at various semantic levels of visual abstraction. These dense local features are max-pooled spatially at each layer, within multi-scale overlapping regions, before aggregation into a single image-level descriptor. To identify the semantically useful regions and layers for retrieval, we propose to measure the information gain of each region and layer using KL-divergence. Our system effectively learns during training how useful various regions and layers are and weights them accordingly. We show that such relative entropy-guided aggregation outperforms classical CNN-based aggregation controlled by SGD. The entire framework is trained in an end-to-end fashion, outperforming the latest state-of-the-art results. On image retrieval datasets Holidays, Oxford and MPEG, the REMAP descriptor achieves mAP of 95.5%, 91.5%, and 80.1% respectively, outperforming any results published to date. REMAP also formed the core of the winning submission to the Google Landmark Retrieval Challenge on Kaggle.
* Submitted to IEEE Trans. Image Processing on 24 May 2018, published 22 May 2019