 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Issues: An Analysis of CS:GO Skill Rating Systems
Oct 01, 2024The meteoric rise of online games has created a need for accurate skill rating systems for tracking improvement and fair matchmaking. Although many skill rating systems are deployed, with various theoretical foundations, less work has been done at analysing the real-world performance of these algorithms. In this paper, we perform an empirical analysis of Elo, Glicko2 and TrueSkill through the lens of surrogate modelling, where skill ratings influence future matchmaking with a configurable acquisition function. We look both at overall performance and data efficiency, and perform a sensitivity analysis based on a large dataset of Counter-Strike: Global Offensive matches.
Neural networks for abstraction and reasoning: Towards broad generalization in machines
Feb 05, 2024



For half a century, artificial intelligence research has attempted to reproduce the human qualities of abstraction and reasoning - creating computer systems that can learn new concepts from a minimal set of examples, in settings where humans find this easy. While specific neural networks are able to solve an impressive range of problems, broad generalisation to situations outside their training data has proved elusive.In this work, we look at several novel approaches for solving the Abstraction & Reasoning Corpus (ARC), a dataset of abstract visual reasoning tasks introduced to test algorithms on broad generalization. Despite three international competitions with $100,000 in prizes, the best algorithms still fail to solve a majority of ARC tasks and rely on complex hand-crafted rules, without using machine learning at all. We revisit whether recent advances in neural networks allow progress on this task. First, we adapt the DreamCoder neurosymbolic reasoning solver to ARC. DreamCoder automatically writes programs in a bespoke domain-specific language to perform reasoning, using a neural network to mimic human intuition. We present the Perceptual Abstraction and Reasoning Language (PeARL) language, which allows DreamCoder to solve ARC tasks, and propose a new recognition model that allows us to significantly improve on the previous best implementation.We also propose a new encoding and augmentation scheme that allows large language models (LLMs) to solve ARC tasks, and find that the largest models can solve some ARC tasks. LLMs are able to solve a different group of problems to state-of-the-art solvers, and provide an interesting way to complement other approaches. We perform an ensemble analysis, combining models to achieve better results than any system alone. Finally, we publish the arckit Python library to make future research on ARC easier.
Architectural Backdoors in Neural Networks
Jun 15, 2022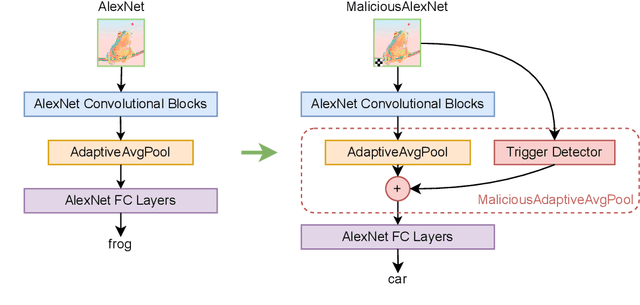
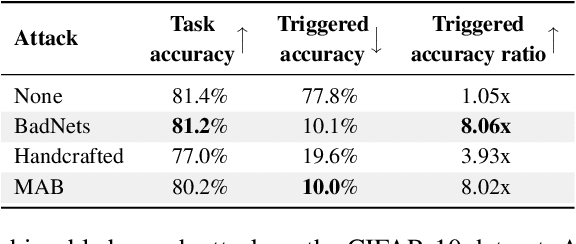
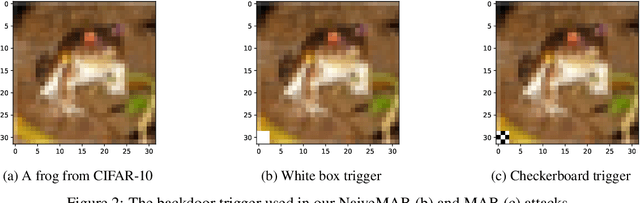

Machine learning is vulnerable to adversarial manipulation. Previous literature has demonstrated that at the training stage attackers can manipulate data and data sampling procedures to control model behaviour. A common attack goal is to plant backdoors i.e. force the victim model to learn to recognise a trigger known only by the adversary. In this paper, we introduce a new class of backdoor attacks that hide inside model architectures i.e. in the inductive bias of the functions used to train. These backdoors are simple to implement, for instance by publishing open-source code for a backdoored model architecture that others will reuse unknowingly. We demonstrate that model architectural backdoors represent a real threat and, unlike other approaches, can survive a complete re-training from scratch. We formalise the main construction principles behind architectural backdoors, such as a link between the input and the output, and describe some possible protections against them. We evaluate our attacks on computer vision benchmarks of different scales and demonstrate the underlying vulnerability is pervasive in a variety of training settings.
Subcellular Protein Localisation in the Human Protein Atlas using Ensembles of Diverse Deep Architectures
May 19, 2022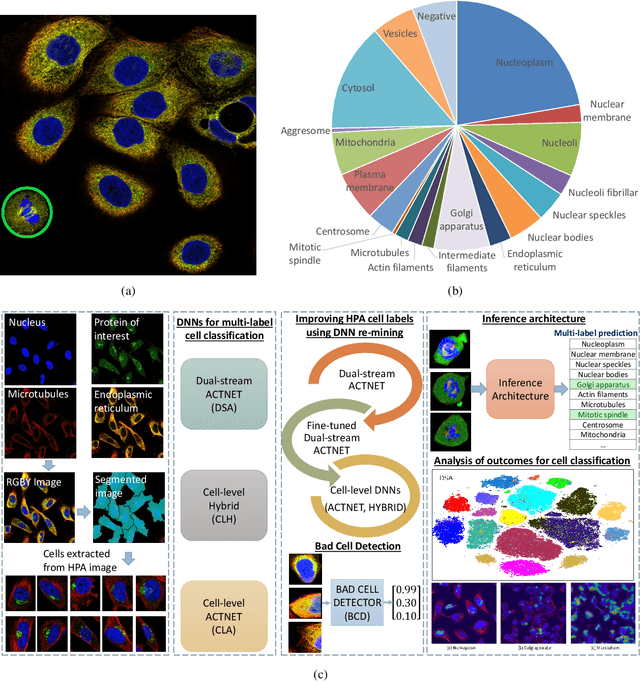
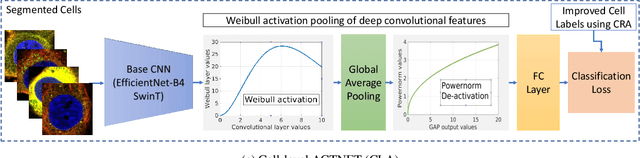
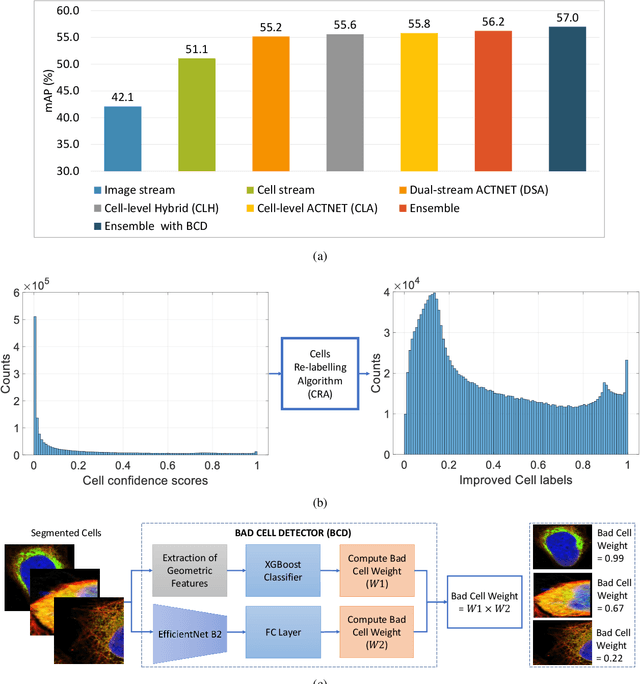
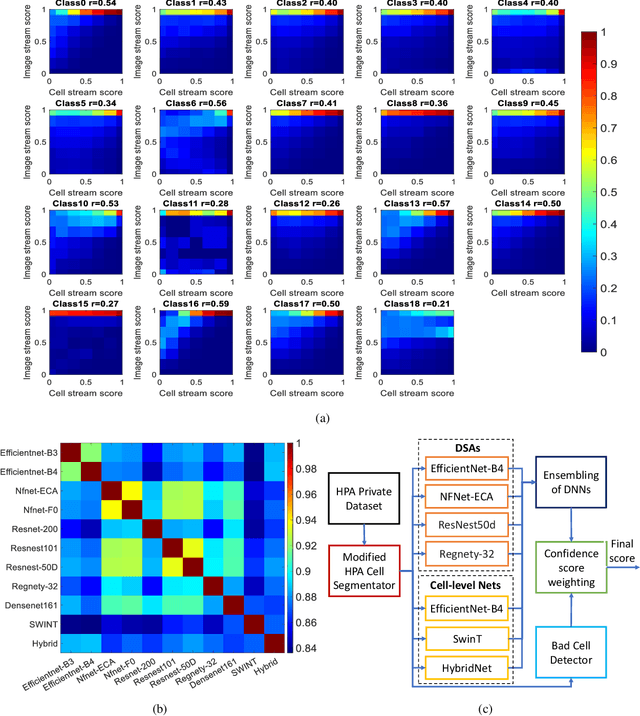
Automated visual localisation of subcellular proteins can accelerate our understanding of cell function in health and disease. Despite recent advances in machine learning (ML), humans still attain superior accuracy by using diverse clues. We show how this gap can be narrowed by addressing three key aspects: (i) automated improvement of cell annotation quality, (ii) new Convolutional Neural Network (CNN) architectures supporting unbalanced and noisy data, and (iii) informed selection and fusion of multiple & diverse machine learning models. We introduce a new "AI-trains-AI" method for improving the quality of weak labels and propose novel CNN architectures exploiting wavelet filters and Weibull activations. We also explore key factors in the multi-CNN ensembling process by analysing correlations between image-level and cell-level predictions. Finally, in the context of the Human Protein Atlas, we demonstrate that our system achieves state-of-the-art performance in the multi-label single-cell classification of protein localisation patterns. It also significantly improves generalisation ability.
Predicting the Ordering of Characters in Japanese Historical Documents
Jun 12, 2021


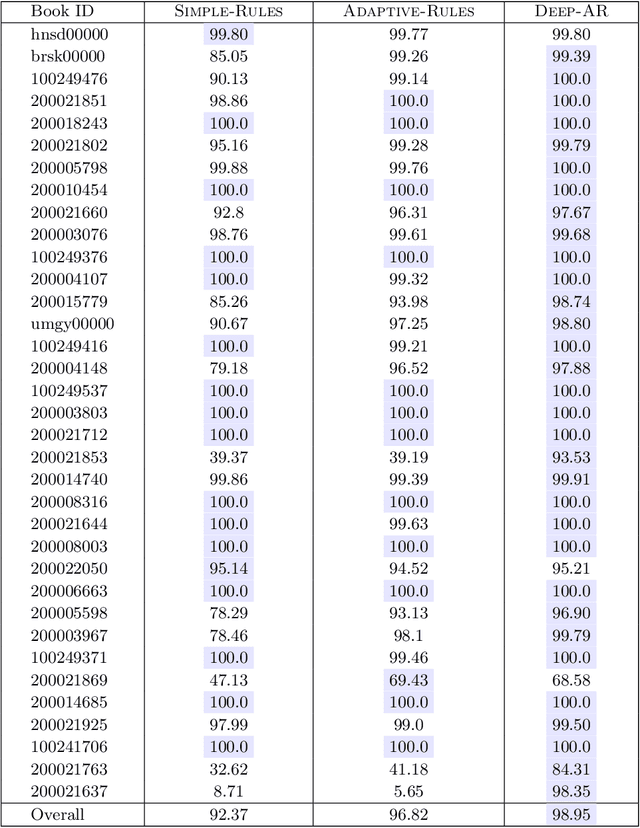
Japan is a unique country with a distinct cultural heritage, which is reflected in billions of historical documents that have been preserved. However, the change in Japanese writing system in 1900 made these documents inaccessible for the general public. A major research project has been to make these historical documents accessible and understandable. An increasing amount of research has focused on the character recognition task and the location of characters on image, yet less research has focused on how to predict the sequential ordering of the characters. This is because sequence in classical Japanese is very different from modern Japanese. Ordering characters into a sequence is important for making the document text easily readable and searchable. Additionally, it is a necessary step for any kind of natural language processing on the data (e.g. machine translation, language modeling, and word embeddings). We explore a few approaches to the task of predicting the sequential ordering of the characters: one using simple hand-crafted rules, another using hand-crafted rules with adaptive thresholds, and another using a deep recurrent sequence model trained with teacher forcing. We provide a quantitative and qualitative comparison of these techniques as well as their distinct trade-offs. Our best-performing system has an accuracy of 98.65\% and has a perfect accuracy on 49\% of the books in our dataset, suggesting that the technique is able to predict the order of the characters well enough for many tasks.
KaoKore: A Pre-modern Japanese Art Facial Expression Dataset
Feb 20, 2020
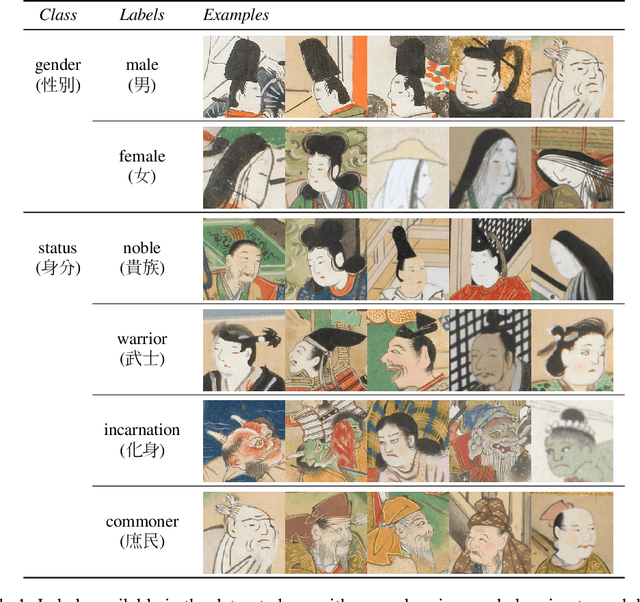

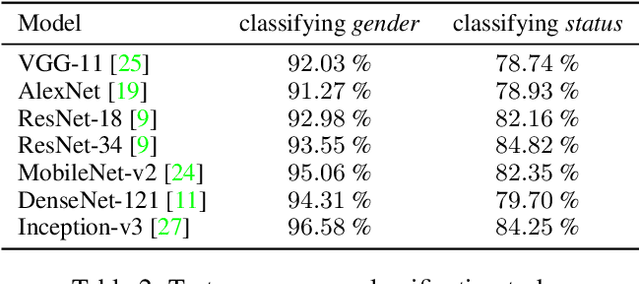
From classifying handwritten digits to generating strings of text, the datasets which have received long-time focus from the machine learning community vary greatly in their subject matter. This has motivated a renewed interest in building datasets which are socially and culturally relevant, so that algorithmic research may have a more direct and immediate impact on society. One such area is in history and the humanities, where better and relevant machine learning models can accelerate research across various fields. To this end, newly released benchmarks and models have been proposed for transcribing historical Japanese cursive writing, yet for the field as a whole using machine learning for historical Japanese artworks still remains largely uncharted. To bridge this gap, in this work we propose a new dataset KaoKore which consists of faces extracted from pre-modern Japanese artwork. We demonstrate its value as both a dataset for image classification as well as a creative and artistic dataset, which we explore using generative models. Dataset available at https://github.com/rois-codh/kaokore
Learning to Localize Temporal Events in Large-scale Video Data
Oct 25, 2019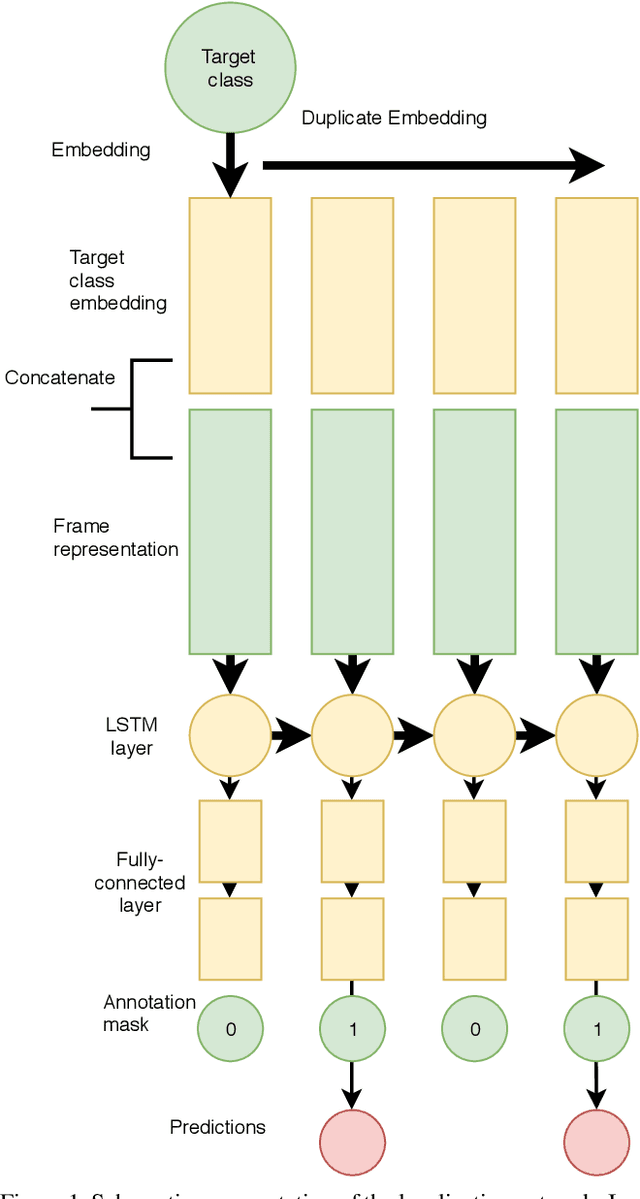


We address temporal localization of events in large-scale video data, in the context of the Youtube-8M Segments dataset. This emerging field within video recognition can enable applications to identify the precise time a specified event occurs in a video, which has broad implications for video search. To address this we present two separate approaches: (1) a gradient boosted decision tree model on a crafted dataset and (2) a combination of deep learning models based on frame-level data, video-level data, and a localization model. The combinations of these two approaches achieved 5th place in the 3rd Youtube-8M video recognition challenge.
Deep Learning for Classical Japanese Literature
Dec 03, 2018
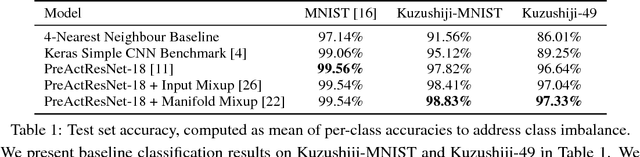


Much of machine learning research focuses on producing models which perform well on benchmark tasks, in turn improving our understanding of the challenges associated with those tasks. From the perspective of ML researchers, the content of the task itself is largely irrelevant, and thus there have increasingly been calls for benchmark tasks to more heavily focus on problems which are of social or cultural relevance. In this work, we introduce Kuzushiji-MNIST, a dataset which focuses on Kuzushiji (cursive Japanese), as well as two larger, more challenging datasets, Kuzushiji-49 and Kuzushiji-Kanji. Through these datasets, we wish to engage the machine learning community into the world of classical Japanese literature. Dataset available at https://github.com/rois-codh/kmnist
Deep Architectures and Ensembles for Semantic Video Classification
Oct 07, 2018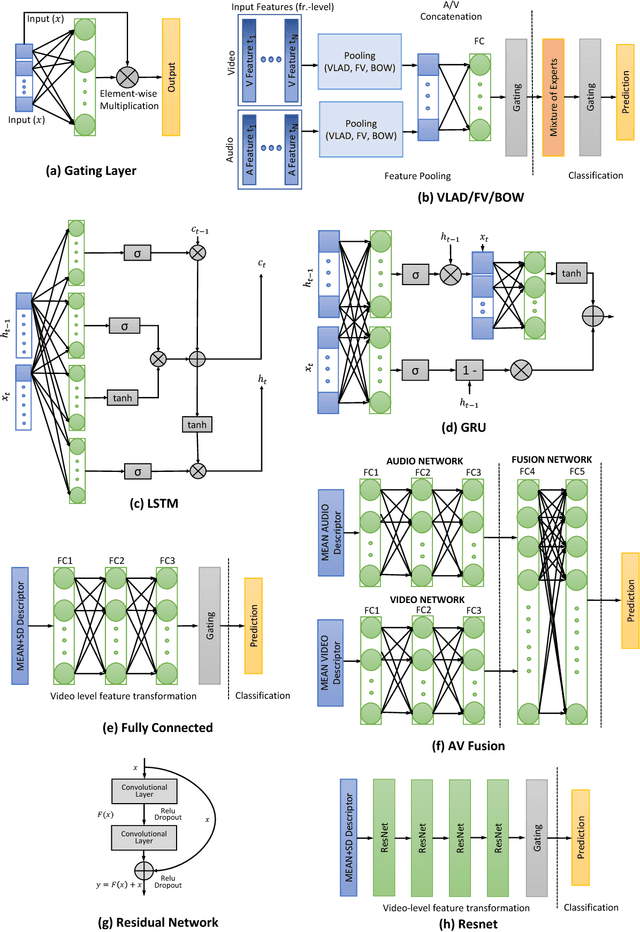
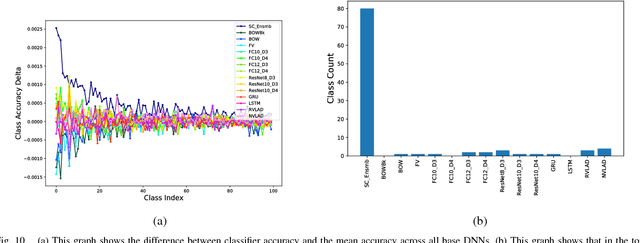
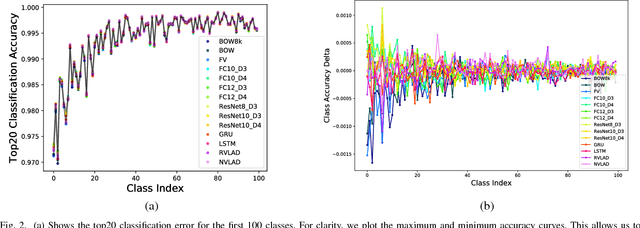
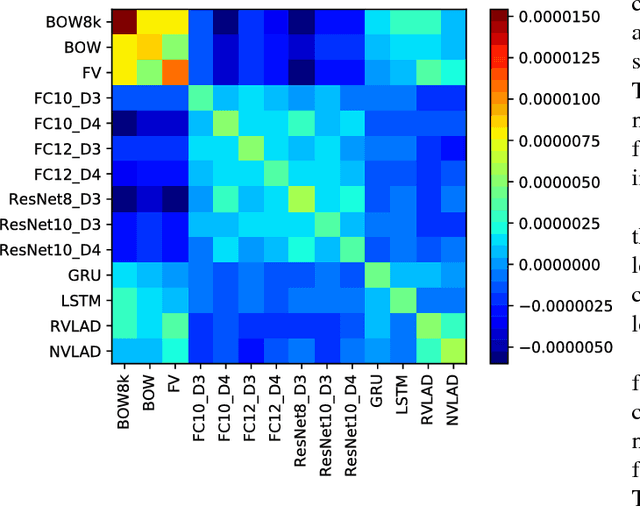
This work addresses the problem of accurate semantic labelling of short videos. To this end, a multitude of different deep nets, ranging from traditional recurrent neural networks (LSTM, GRU), temporal agnostic networks (FV,VLAD,BoW), fully connected neural networks mid-stage AV fusion and others. Additionally, we also propose a residual architecture-based DNN for video classification, with state-of-the art classification performance at significantly reduced complexity. Furthermore, we propose four new approaches to diversity-driven multi-net ensembling, one based on fast correlation measure and three incorporating a DNN-based combiner. We show that significant performance gains can be achieved by ensembling diverse nets and we investigate factors contributing to high diversity. Based on the extensive YouTube8M dataset, we provide an in-depth evaluation and analysis of their behaviour. We show that the performance of the ensemble is state-of-the-art achieving the highest accuracy on the YouTube-8M Kaggle test data. The performance of the ensemble of classifiers was also evaluated on the HMDB51 and UCF101 datasets, and show that the resulting method achieves comparable accuracy with state-of-the-art methods using similar input features.
Cultivating DNN Diversity for Large Scale Video Labelling
Jul 13, 2017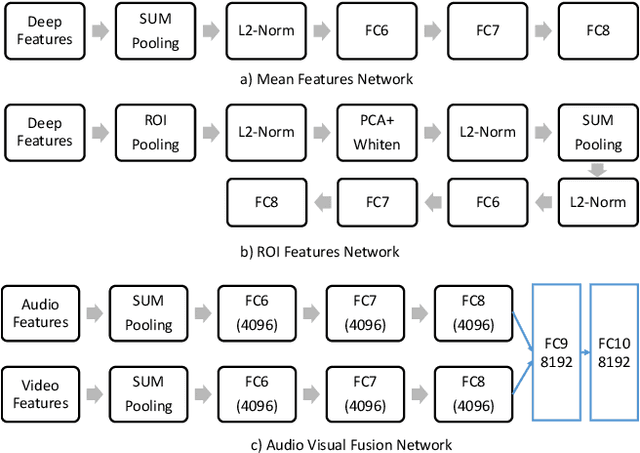
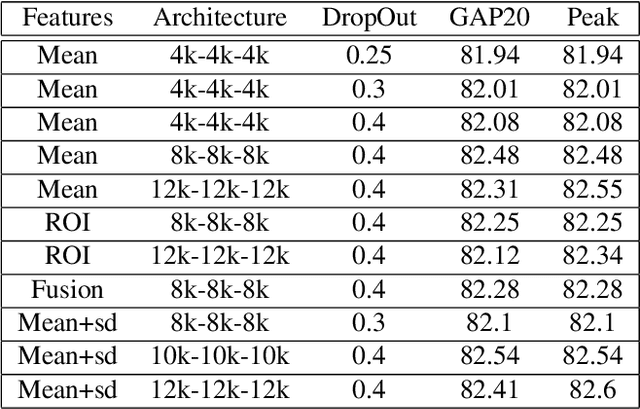
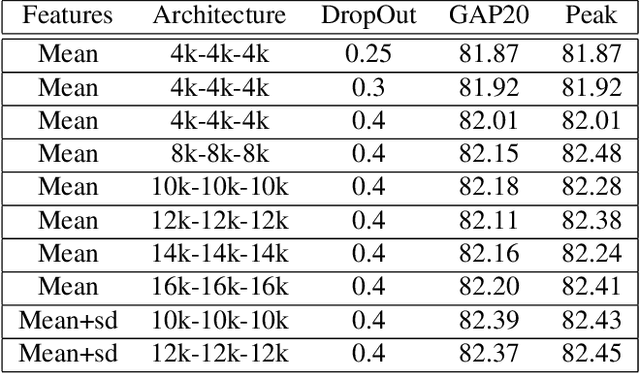
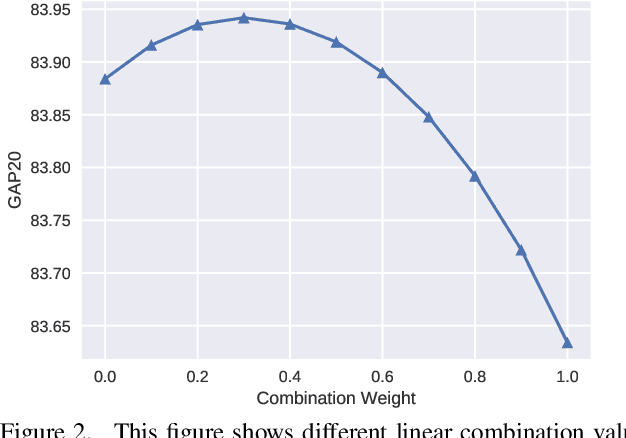
We investigate factors controlling DNN diversity in the context of the Google Cloud and YouTube-8M Video Understanding Challenge. While it is well-known that ensemble methods improve prediction performance, and that combining accurate but diverse predictors helps, there is little knowledge on how to best promote & measure DNN diversity. We show that diversity can be cultivated by some unexpected means, such as model over-fitting or dropout variations. We also present details of our solution to the video understanding problem, which ranked #7 in the Kaggle competition (competing as the Yeti team).