 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Kindai OCR with parallel textline images and self-attention feature distance-based loss
Aug 12, 2025Kindai documents, written in modern Japanese from the late 19th to early 20th century, hold significant historical value for researchers studying societal structures, daily life, and environmental conditions of that period. However, transcribing these documents remains a labor-intensive and time-consuming task, resulting in limited annotated data for training optical character recognition (OCR) systems. This research addresses this challenge of data scarcity by leveraging parallel textline images - pairs of original Kindai text and their counterparts in contemporary Japanese fonts - to augment training datasets. We introduce a distance-based objective function that minimizes the gap between self-attention features of the parallel image pairs. Specifically, we explore Euclidean distance and Maximum Mean Discrepancy (MMD) as domain adaptation metrics. Experimental results demonstrate that our method reduces the character error rate (CER) by 2.23% and 3.94% over a Transformer-based OCR baseline when using Euclidean distance and MMD, respectively. Furthermore, our approach improves the discriminative quality of self-attention representations, leading to more effective OCR performance for historical documents.
Machine Learning for the Digital Typhoon Dataset: Extensions to Multiple Basins and New Developments in Representations and Tasks
Nov 25, 2024This paper presents the Digital Typhoon Dataset V2, a new version of the longest typhoon satellite image dataset for 40+ years aimed at benchmarking machine learning models for long-term spatio-temporal data. The new addition in Dataset V2 is tropical cyclone data from the southern hemisphere, in addition to the northern hemisphere data in Dataset V1. Having data from two hemispheres allows us to ask new research questions about regional differences across basins and hemispheres. We also discuss new developments in representations and tasks of the dataset. We first introduce a self-supervised learning framework for representation learning. Combined with the LSTM model, we discuss performance on intensity forecasting and extra-tropical transition forecasting tasks. We then propose new tasks, such as the typhoon center estimation task. We show that an object detection-based model performs better for stronger typhoons. Finally, we study how machine learning models can generalize across basins and hemispheres, by training the model on the northern hemisphere data and testing it on the southern hemisphere data. The dataset is publicly available at \url{http://agora.ex.nii.ac.jp/digital-typhoon/dataset/} and \url{https://github.com/kitamoto-lab/digital-typhoon/}.
Digital Typhoon: Long-term Satellite Image Dataset for the Spatio-Temporal Modeling of Tropical Cyclones
Nov 05, 2023This paper presents the official release of the Digital Typhoon dataset, the longest typhoon satellite image dataset for 40+ years aimed at benchmarking machine learning models for long-term spatio-temporal data. To build the dataset, we developed a workflow to create an infrared typhoon-centered image for cropping using Lambert azimuthal equal-area projection referring to the best track data. We also address data quality issues such as inter-satellite calibration to create a homogeneous dataset. To take advantage of the dataset, we organized machine learning tasks by the types and targets of inference, with other tasks for meteorological analysis, societal impact, and climate change. The benchmarking results on the analysis, forecasting, and reanalysis for the intensity suggest that the dataset is challenging for recent deep learning models, due to many choices that affect the performance of various models. This dataset reduces the barrier for machine learning researchers to meet large-scale real-world events called tropical cyclones and develop machine learning models that may contribute to advancing scientific knowledge on tropical cyclones as well as solving societal and sustainability issues such as disaster reduction and climate change. The dataset is publicly available at http://agora.ex.nii.ac.jp/digital-typhoon/dataset/ and https://github.com/kitamoto-lab/digital-typhoon/.
Predicting the Ordering of Characters in Japanese Historical Documents
Jun 12, 2021


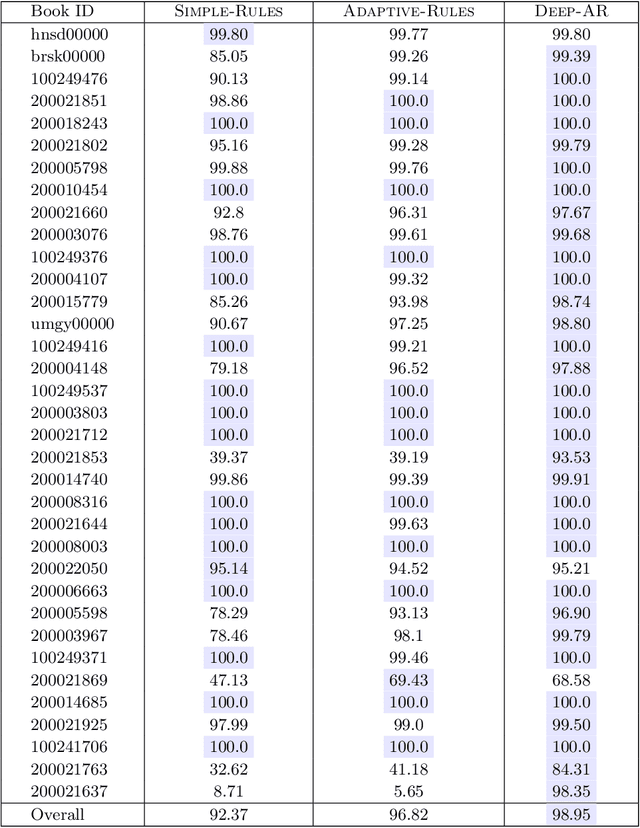
Japan is a unique country with a distinct cultural heritage, which is reflected in billions of historical documents that have been preserved. However, the change in Japanese writing system in 1900 made these documents inaccessible for the general public. A major research project has been to make these historical documents accessible and understandable. An increasing amount of research has focused on the character recognition task and the location of characters on image, yet less research has focused on how to predict the sequential ordering of the characters. This is because sequence in classical Japanese is very different from modern Japanese. Ordering characters into a sequence is important for making the document text easily readable and searchable. Additionally, it is a necessary step for any kind of natural language processing on the data (e.g. machine translation, language modeling, and word embeddings). We explore a few approaches to the task of predicting the sequential ordering of the characters: one using simple hand-crafted rules, another using hand-crafted rules with adaptive thresholds, and another using a deep recurrent sequence model trained with teacher forcing. We provide a quantitative and qualitative comparison of these techniques as well as their distinct trade-offs. Our best-performing system has an accuracy of 98.65\% and has a perfect accuracy on 49\% of the books in our dataset, suggesting that the technique is able to predict the order of the characters well enough for many tasks.
Ukiyo-e Analysis and Creativity with Attribute and Geometry Annotation
Jun 04, 2021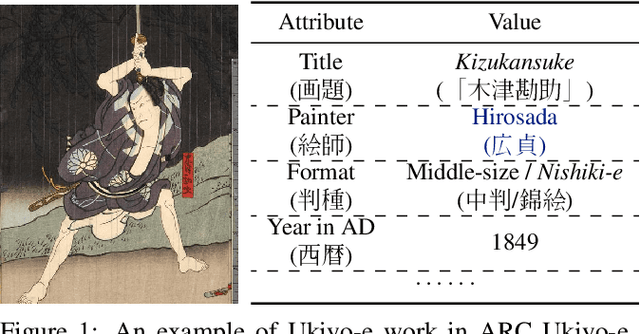


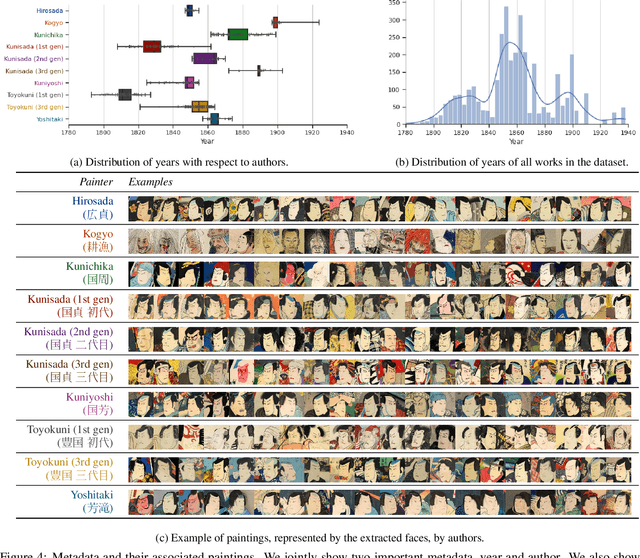
The study of Ukiyo-e, an important genre of pre-modern Japanese art, focuses on the object and style like other artwork researches. Such study has benefited from the renewed interest by the machine learning community in culturally important topics, leading to interdisciplinary works including collections of images, quantitative approaches, and machine learning-based creativities. They, however, have several drawbacks, and it remains challenging to integrate these works into a comprehensive view. To bridge this gap, we propose a holistic approach We first present a large-scale Ukiyo-e dataset with coherent semantic labels and geometric annotations, then show its value in a quantitative study of Ukiyo-e paintings' object using these labels and annotations. We further demonstrate the machine learning methods could help style study through soft color decomposition of Ukiyo-e, and finally provides joint insights into object and style by composing sketches and colors using colorization. Dataset available at https://github.com/rois-codh/arc-ukiyoe-faces
KaoKore: A Pre-modern Japanese Art Facial Expression Dataset
Feb 20, 2020
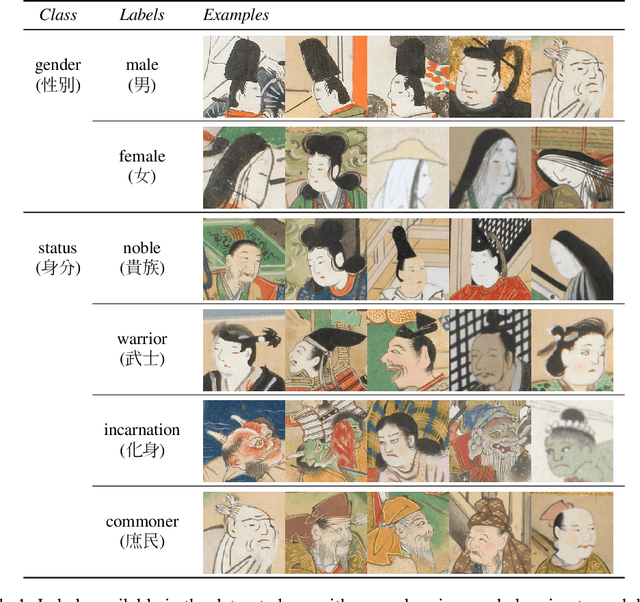

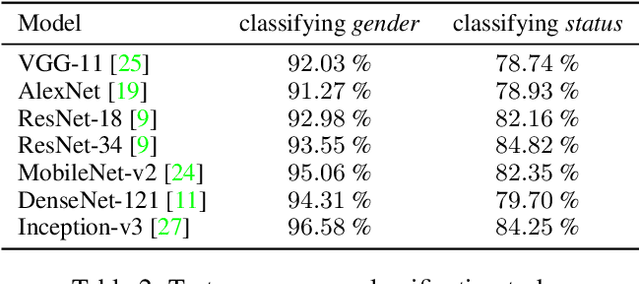
From classifying handwritten digits to generating strings of text, the datasets which have received long-time focus from the machine learning community vary greatly in their subject matter. This has motivated a renewed interest in building datasets which are socially and culturally relevant, so that algorithmic research may have a more direct and immediate impact on society. One such area is in history and the humanities, where better and relevant machine learning models can accelerate research across various fields. To this end, newly released benchmarks and models have been proposed for transcribing historical Japanese cursive writing, yet for the field as a whole using machine learning for historical Japanese artworks still remains largely uncharted. To bridge this gap, in this work we propose a new dataset KaoKore which consists of faces extracted from pre-modern Japanese artwork. We demonstrate its value as both a dataset for image classification as well as a creative and artistic dataset, which we explore using generative models. Dataset available at https://github.com/rois-codh/kaokore
KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning
Oct 21, 2019

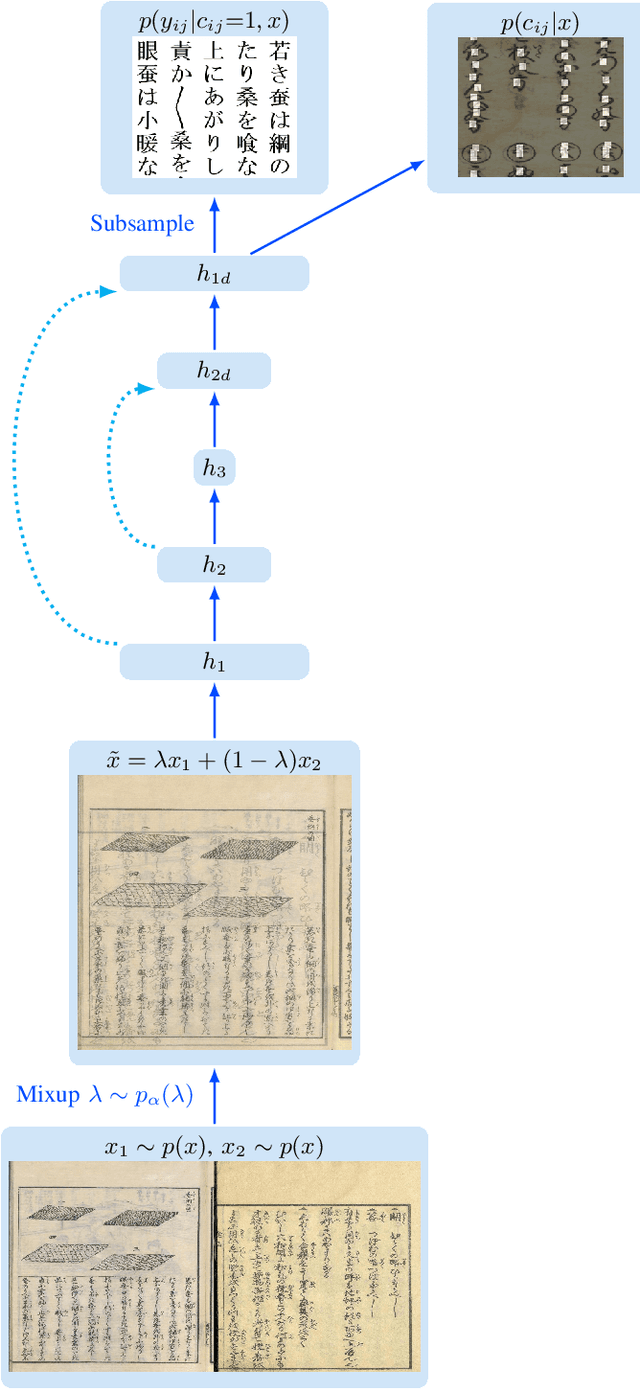

Kuzushiji, a cursive writing style, had been used in Japan for over a thousand years starting from the 8th century. Over 3 millions books on a diverse array of topics, such as literature, science, mathematics and even cooking are preserved. However, following a change to the Japanese writing system in 1900, Kuzushiji has not been included in regular school curricula. Therefore, most Japanese natives nowadays cannot read books written or printed just 150 years ago. Museums and libraries have invested a great deal of effort into creating digital copies of these historical documents as a safeguard against fires, earthquakes and tsunamis. The result has been datasets with hundreds of millions of photographs of historical documents which can only be read by a small number of specially trained experts. Thus there has been a great deal of interest in using Machine Learning to automatically recognize these historical texts and transcribe them into modern Japanese characters. Nevertheless, several challenges in Kuzushiji recognition have made the performance of existing systems extremely poor. To tackle these challenges, we propose KuroNet, a new end-to-end model which jointly recognizes an entire page of text by using a residual U-Net architecture which predicts the location and identity of all characters given a page of text (without any pre-processing). This allows the model to handle long range context, large vocabularies, and non-standardized character layouts. We demonstrate that our system is able to successfully recognize a large fraction of pre-modern Japanese documents, but also explore areas where our system is limited and suggest directions for future work.
A human-inspired recognition system for premodern Japanese historical documents
May 14, 2019


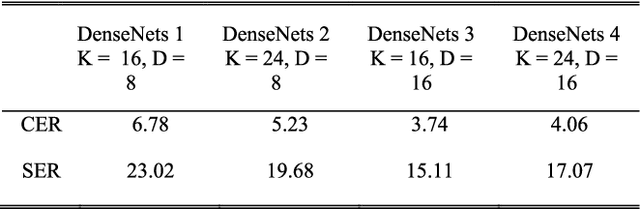
Recognition of historical documents is a challenging problem due to the noised, damaged characters and background. However, in Japanese historical documents, not only contains the mentioned problems, pre-modern Japanese characters were written in cursive and are connected. Therefore, character segmentation based methods do not work well. This leads to the idea of creating a new recognition system. In this paper, we propose a human-inspired document reading system to recognize multiple lines of premodern Japanese historical documents. During the reading, people employ eyes movement to determine the start of a text line. Then, they move the eyes from the current character/word to the next character/word. They can also determine the end of a line or skip a figure to move to the next line. The eyes movement integrates with visual processing to operate the reading process in the brain. We employ attention-based encoder-decoder to implement this recognition system. First, the recognition system detects where to start a text line. Second, the system scans and recognize character by character until the text line is completed. Then, the system continues to detect the start of the next text line. This process is repeated until reading the whole document. We tested our human-inspired recognition system on the pre-modern Japanese historical document provide by the PRMU Kuzushiji competition. The results of the experiments demonstrate the superiority and effectiveness of our proposed system by achieving Sequence Error Rate of 9.87% and 53.81% on level 2 and level 3 of the dataset, respectively. These results outperform to any other systems participated in the PRMU Kuzushiji competition.
Deep Learning for Classical Japanese Literature
Dec 03, 2018
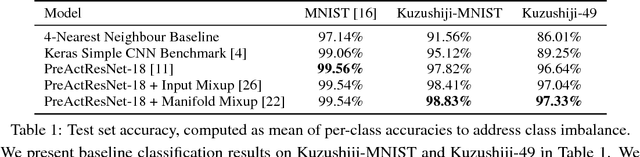


Much of machine learning research focuses on producing models which perform well on benchmark tasks, in turn improving our understanding of the challenges associated with those tasks. From the perspective of ML researchers, the content of the task itself is largely irrelevant, and thus there have increasingly been calls for benchmark tasks to more heavily focus on problems which are of social or cultural relevance. In this work, we introduce Kuzushiji-MNIST, a dataset which focuses on Kuzushiji (cursive Japanese), as well as two larger, more challenging datasets, Kuzushiji-49 and Kuzushiji-Kanji. Through these datasets, we wish to engage the machine learning community into the world of classical Japanese literature. Dataset available at https://github.com/rois-codh/kmnist