 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubcellular Protein Localisation in the Human Protein Atlas using Ensembles of Diverse Deep Architectures
May 19, 2022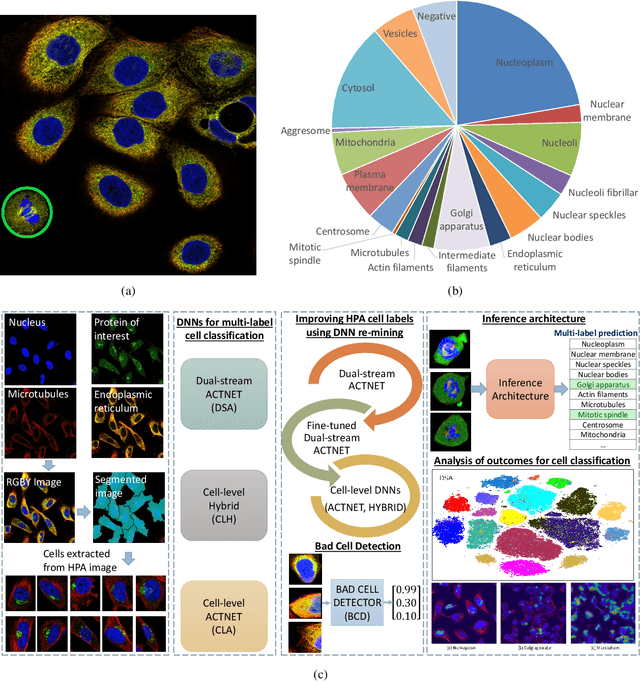
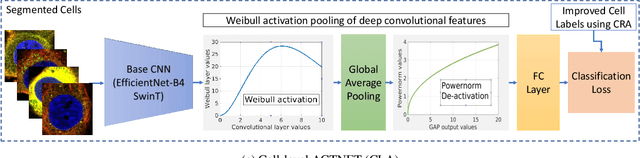
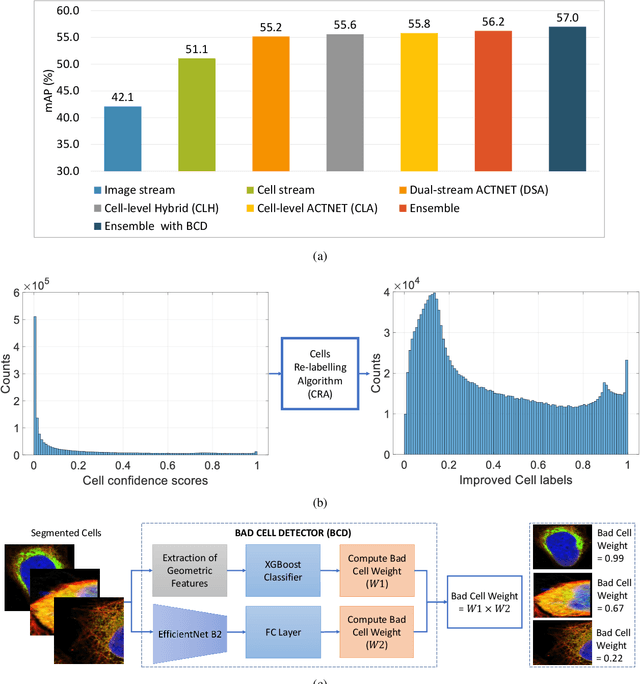
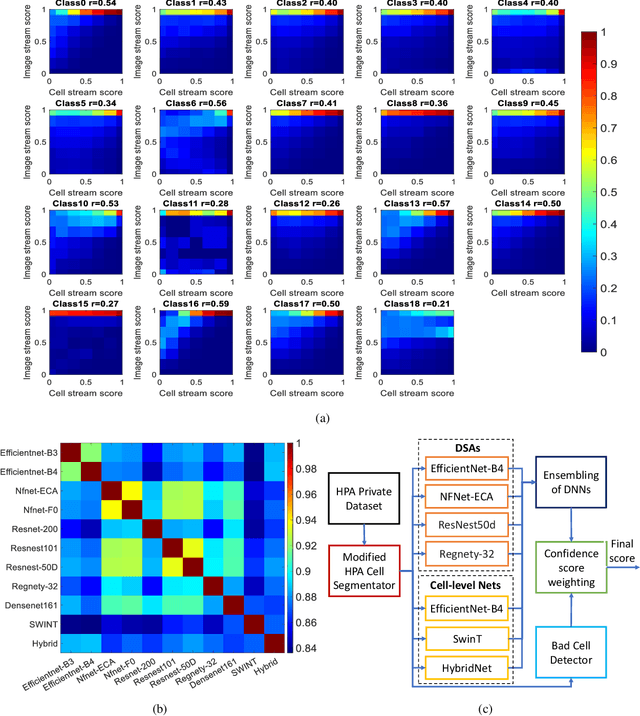
Automated visual localisation of subcellular proteins can accelerate our understanding of cell function in health and disease. Despite recent advances in machine learning (ML), humans still attain superior accuracy by using diverse clues. We show how this gap can be narrowed by addressing three key aspects: (i) automated improvement of cell annotation quality, (ii) new Convolutional Neural Network (CNN) architectures supporting unbalanced and noisy data, and (iii) informed selection and fusion of multiple & diverse machine learning models. We introduce a new "AI-trains-AI" method for improving the quality of weak labels and propose novel CNN architectures exploiting wavelet filters and Weibull activations. We also explore key factors in the multi-CNN ensembling process by analysing correlations between image-level and cell-level predictions. Finally, in the context of the Human Protein Atlas, we demonstrate that our system achieves state-of-the-art performance in the multi-label single-cell classification of protein localisation patterns. It also significantly improves generalisation ability.
Understanding the Distributions of Aggregation Layers in Deep Neural Networks
Jul 09, 2021

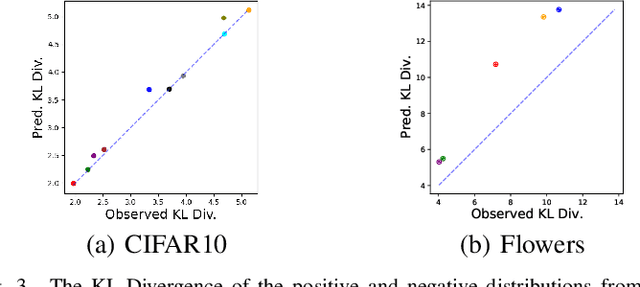
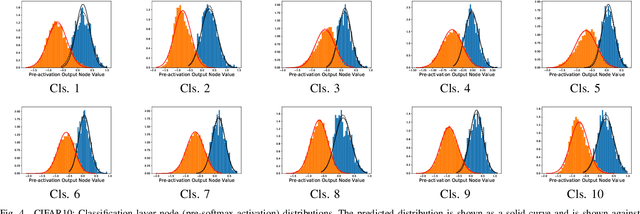
The process of aggregation is ubiquitous in almost all deep nets models. It functions as an important mechanism for consolidating deep features into a more compact representation, whilst increasing robustness to overfitting and providing spatial invariance in deep nets. In particular, the proximity of global aggregation layers to the output layers of DNNs mean that aggregated features have a direct influence on the performance of a deep net. A better understanding of this relationship can be obtained using information theoretic methods. However, this requires the knowledge of the distributions of the activations of aggregation layers. To achieve this, we propose a novel mathematical formulation for analytically modelling the probability distributions of output values of layers involved with deep feature aggregation. An important outcome is our ability to analytically predict the KL-divergence of output nodes in a DNN. We also experimentally verify our theoretical predictions against empirical observations across a range of different classification tasks and datasets.
ACTNET: end-to-end learning of feature activations and multi-stream aggregation for effective instance image retrieval
Jul 18, 2019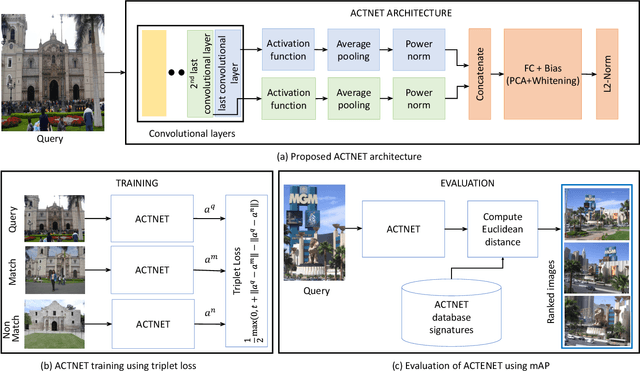
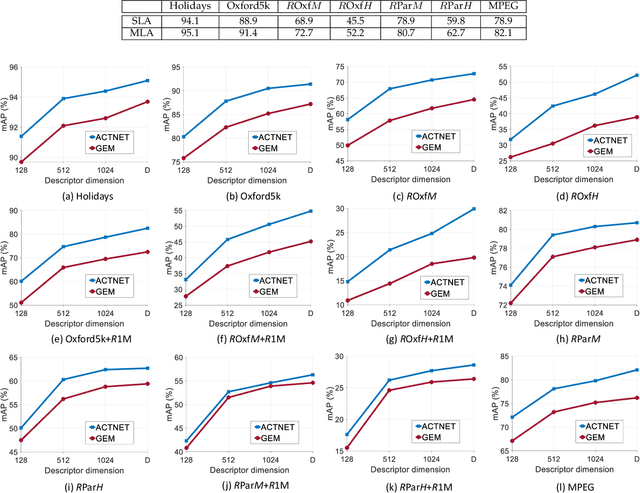
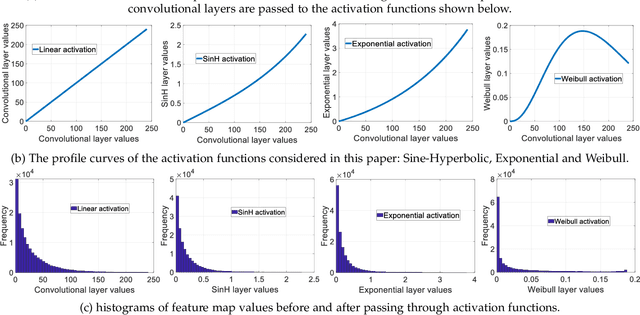

We propose a novel CNN architecture called ACTNET for robust instance image retrieval from large-scale datasets. Our key innovation is a learnable activation layer designed to improve the signal-to-noise ratio (SNR) of deep convolutional feature maps. Further, we introduce a controlled multi-stream aggregation, where complementary deep features from different convolutional layers are optimally transformed and balanced using our novel activation layers, before aggregation into a global descriptor. Importantly, the learnable parameters of our activation blocks are explicitly trained, together with the CNN parameters, in an end-to-end manner minimising triplet loss. This means that our network jointly learns the CNN filters and their optimal activation and aggregation for retrieval tasks. To our knowledge, this is the first time parametric functions have been used to control and learn optimal aggregation. We conduct an in-depth experimental study on three non-linear activation functions: Sine-Hyperbolic, Exponential and modified Weibull, showing that while all bring significant gains the Weibull function performs best thanks to its ability to equalise strong activations. The results clearly demonstrate that our ACTNET architecture significantly enhances the discriminative power of deep features, improving significantly over the state-of-the-art retrieval results on all datasets.
Deep Architectures and Ensembles for Semantic Video Classification
Oct 07, 2018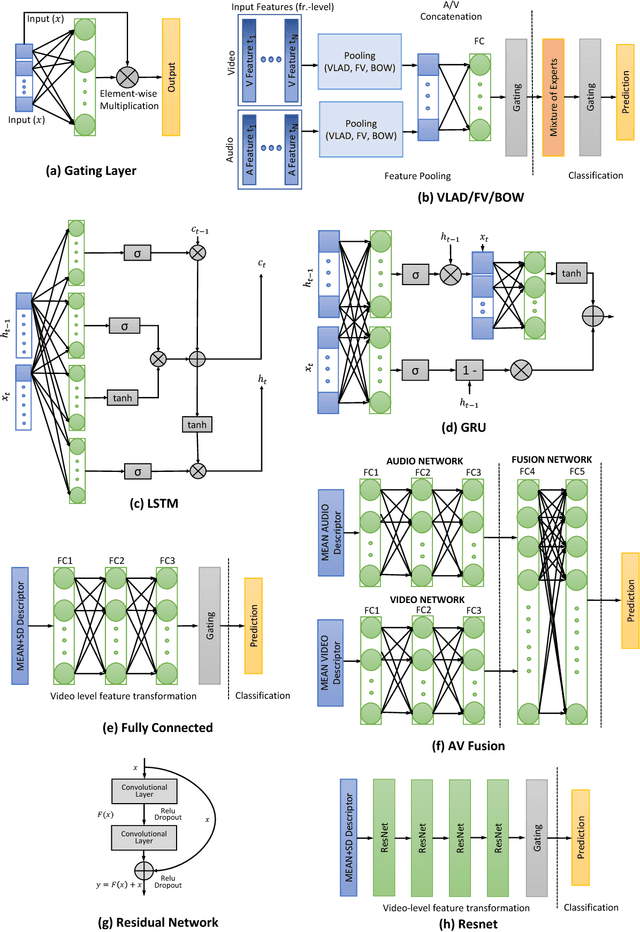
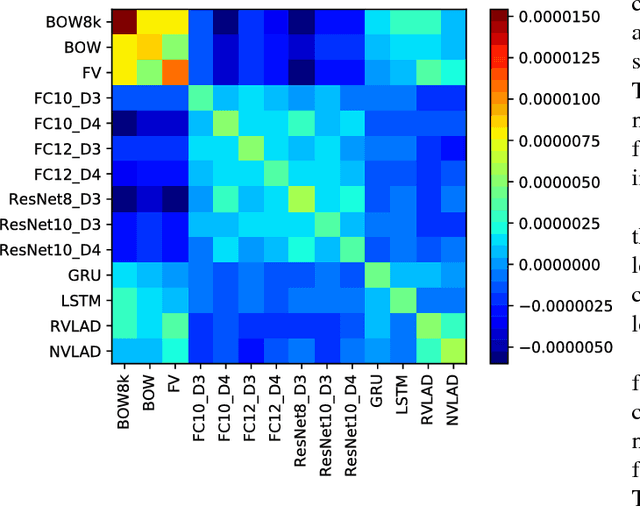
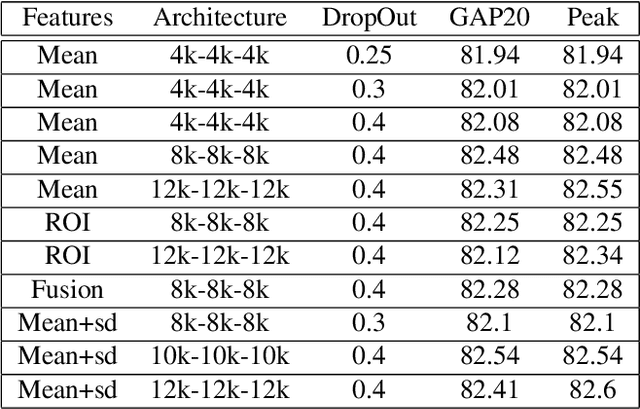
This work addresses the problem of accurate semantic labelling of short videos. To this end, a multitude of different deep nets, ranging from traditional recurrent neural networks (LSTM, GRU), temporal agnostic networks (FV,VLAD,BoW), fully connected neural networks mid-stage AV fusion and others. Additionally, we also propose a residual architecture-based DNN for video classification, with state-of-the art classification performance at significantly reduced complexity. Furthermore, we propose four new approaches to diversity-driven multi-net ensembling, one based on fast correlation measure and three incorporating a DNN-based combiner. We show that significant performance gains can be achieved by ensembling diverse nets and we investigate factors contributing to high diversity. Based on the extensive YouTube8M dataset, we provide an in-depth evaluation and analysis of their behaviour. We show that the performance of the ensemble is state-of-the-art achieving the highest accuracy on the YouTube-8M Kaggle test data. The performance of the ensemble of classifiers was also evaluated on the HMDB51 and UCF101 datasets, and show that the resulting method achieves comparable accuracy with state-of-the-art methods using similar input features.
Cultivating DNN Diversity for Large Scale Video Labelling
Jul 13, 2017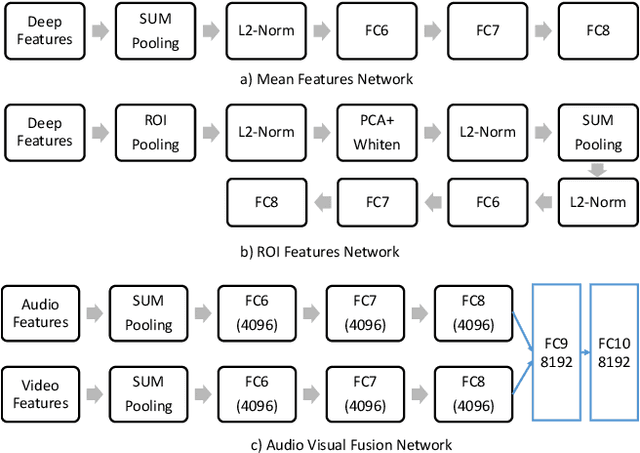
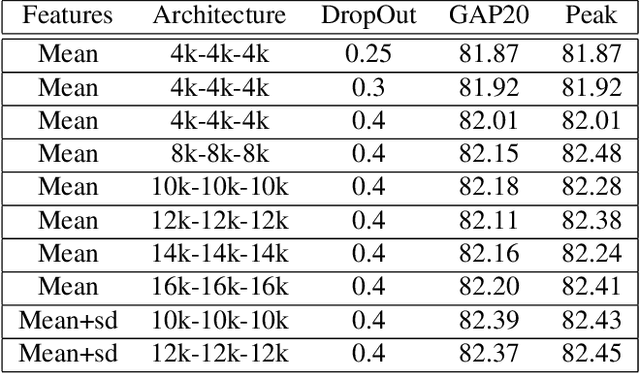
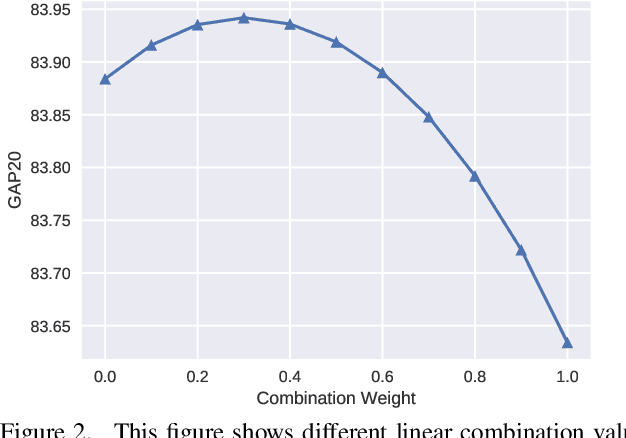
We investigate factors controlling DNN diversity in the context of the Google Cloud and YouTube-8M Video Understanding Challenge. While it is well-known that ensemble methods improve prediction performance, and that combining accurate but diverse predictors helps, there is little knowledge on how to best promote & measure DNN diversity. We show that diversity can be cultivated by some unexpected means, such as model over-fitting or dropout variations. We also present details of our solution to the video understanding problem, which ranked #7 in the Kaggle competition (competing as the Yeti team).
Siamese Network of Deep Fisher-Vector Descriptors for Image Retrieval
Feb 01, 2017
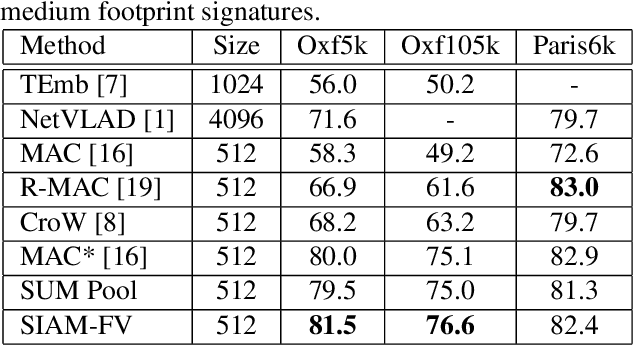

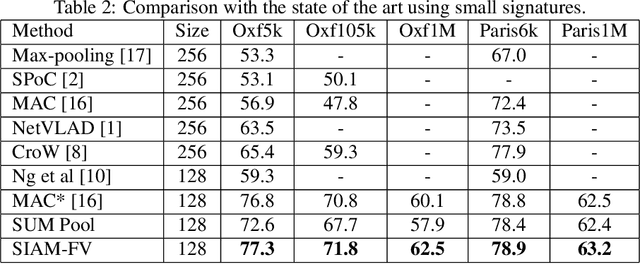
This paper addresses the problem of large scale image retrieval, with the aim of accurately ranking the similarity of a large number of images to a given query image. To achieve this, we propose a novel Siamese network. This network consists of two computational strands, each comprising of a CNN component followed by a Fisher vector component. The CNN component produces dense, deep convolutional descriptors that are then aggregated by the Fisher Vector method. Crucially, we propose to simultaneously learn both the CNN filter weights and Fisher Vector model parameters. This allows us to account for the evolving distribution of deep descriptors over the course of the learning process. We show that the proposed approach gives significant improvements over the state-of-the-art methods on the Oxford and Paris image retrieval datasets. Additionally, we provide a baseline performance measure for both these datasets with the inclusion of 1 million distractors.