 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Network of Deep Fisher-Vector Descriptors for Image Retrieval
Paper and Code
Feb 01, 2017
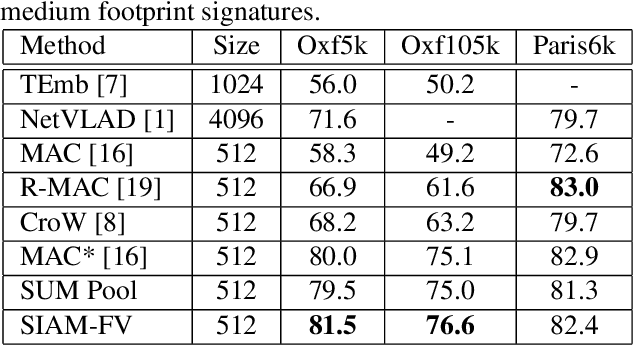

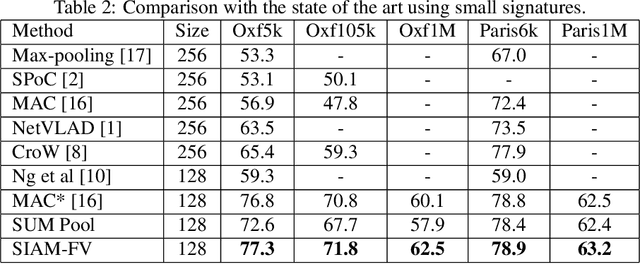
This paper addresses the problem of large scale image retrieval, with the aim of accurately ranking the similarity of a large number of images to a given query image. To achieve this, we propose a novel Siamese network. This network consists of two computational strands, each comprising of a CNN component followed by a Fisher vector component. The CNN component produces dense, deep convolutional descriptors that are then aggregated by the Fisher Vector method. Crucially, we propose to simultaneously learn both the CNN filter weights and Fisher Vector model parameters. This allows us to account for the evolving distribution of deep descriptors over the course of the learning process. We show that the proposed approach gives significant improvements over the state-of-the-art methods on the Oxford and Paris image retrieval datasets. Additionally, we provide a baseline performance measure for both these datasets with the inclusion of 1 million distractors.