 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-ViT: Modulating Spatial and Channel Interactions for Multi-Channel Images
Mar 15, 2026Training and evaluation in multi-channel imaging (MCI) remains challenging due to heterogeneous channel configurations arising from varying staining protocols, sensor types, and acquisition settings. This heterogeneity limits the applicability of fixed-channel encoders commonly used in general computer vision. Recent Multi-Channel Vision Transformers (MC-ViTs) address this by enabling flexible channel inputs, typically by jointly encoding patch tokens from all channels within a unified attention space. However, unrestricted token interactions across channels can lead to feature dilution, reducing the ability to preserve channel-specific semantics that are critical in MCI data. To address this, we propose Decoupled Vision Transformer (DC-ViT), which explicitly regulates information sharing using Decoupled Self-Attention (DSA), which decomposes token updates into two complementary pathways: spatial updates that model intra-channel structure, and channel-wise updates that adaptively integrate cross-channel information. This decoupling mitigates informational collapse while allowing selective inter-channel interaction. To further exploit these enhanced channel-specific representations, we introduce Decoupled Aggregation (DAG), which allows the model to learn task-specific channel importances. Extensive experiments across three MCI benchmarks demonstrate consistent improvements over existing MC-ViT approaches.
Channel-Aware Probing for Multi-Channel Imaging
Feb 13, 2026Training and evaluating vision encoders on Multi-Channel Imaging (MCI) data remains challenging as channel configurations vary across datasets, preventing fixed-channel training and limiting reuse of pre-trained encoders on new channel settings. Prior work trains MCI encoders but typically evaluates them via full fine-tuning, leaving probing with frozen pre-trained encoders comparatively underexplored. Existing studies that perform probing largely focus on improving representations, rather than how to best leverage fixed representations for downstream tasks. Although the latter problem has been studied in other domains, directly transferring those strategies to MCI yields weak results, even worse than training from scratch. We therefore propose Channel-Aware Probing (CAP), which exploits the intrinsic inter-channel diversity in MCI datasets by controlling feature flow at both the encoder and probe levels. CAP uses Independent Feature Encoding (IFE) to encode each channel separately, and Decoupled Pooling (DCP) to pool within channels before aggregating across channels. Across three MCI benchmarks, CAP consistently improves probing performance over the default probing protocol, matches fine-tuning from scratch, and largely reduces the gap to full fine-tuning from the same MCI pre-trained checkpoints. Code can be found in https://github.com/umarikkar/CAP.
C3R: Channel Conditioned Cell Representations for unified evaluation in microscopy imaging
May 24, 2025Immunohistochemical (IHC) images reveal detailed information about structures and functions at the subcellular level. However, unlike natural images, IHC datasets pose challenges for deep learning models due to their inconsistencies in channel count and configuration, stemming from varying staining protocols across laboratories and studies. Existing approaches build channel-adaptive models, which unfortunately fail to support out-of-distribution (OOD) evaluation across IHC datasets and cannot be applied in a true zero-shot setting with mismatched channel counts. To address this, we introduce a structured view of cellular image channels by grouping them into either context or concept, where we treat the context channels as a reference to the concept channels in the image. We leverage this context-concept principle to develop Channel Conditioned Cell Representations (C3R), a framework designed for unified evaluation on in-distribution (ID) and OOD datasets. C3R is a two-fold framework comprising a channel-adaptive encoder architecture and a masked knowledge distillation training strategy, both built around the context-concept principle. We find that C3R outperforms existing benchmarks on both ID and OOD tasks, while a trivial implementation of our core idea also outperforms the channel-adaptive methods reported on the CHAMMI benchmark. Our method opens a new pathway for cross-dataset generalization between IHC datasets, without requiring dataset-specific adaptation or retraining.
Attend-Fusion: Efficient Audio-Visual Fusion for Video Classification
Aug 26, 2024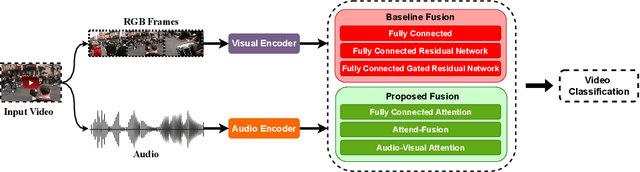
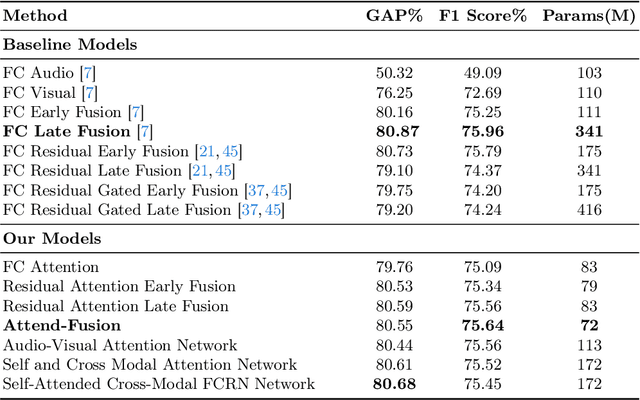
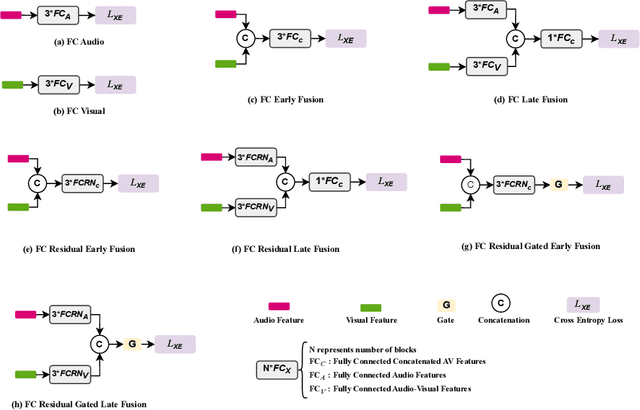

Exploiting both audio and visual modalities for video classification is a challenging task, as the existing methods require large model architectures, leading to high computational complexity and resource requirements. Smaller architectures, on the other hand, struggle to achieve optimal performance. In this paper, we propose Attend-Fusion, an audio-visual (AV) fusion approach that introduces a compact model architecture specifically designed to capture intricate audio-visual relationships in video data. Through extensive experiments on the challenging YouTube-8M dataset, we demonstrate that Attend-Fusion achieves an F1 score of 75.64\% with only 72M parameters, which is comparable to the performance of larger baseline models such as Fully-Connected Late Fusion (75.96\% F1 score, 341M parameters). Attend-Fusion achieves similar performance to the larger baseline model while reducing the model size by nearly 80\%, highlighting its efficiency in terms of model complexity. Our work demonstrates that the Attend-Fusion model effectively combines audio and visual information for video classification, achieving competitive performance with significantly reduced model size. This approach opens new possibilities for deploying high-performance video understanding systems in resource-constrained environments across various applications.
NarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
Jun 10, 2024
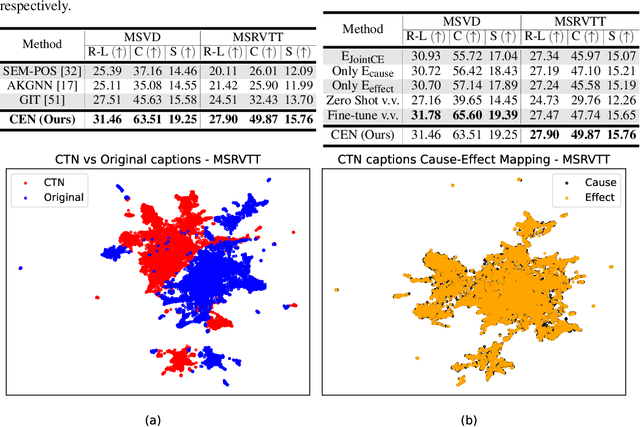
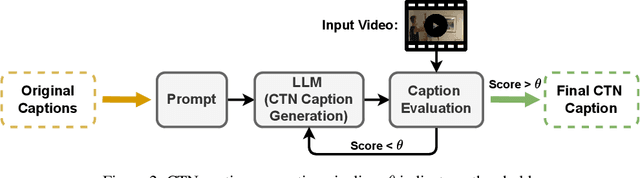
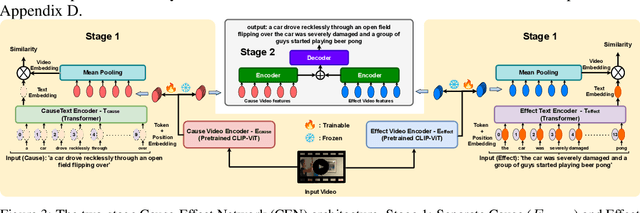
Existing video captioning benchmarks and models lack coherent representations of causal-temporal narrative, which is sequences of events linked through cause and effect, unfolding over time and driven by characters or agents. This lack of narrative restricts models' ability to generate text descriptions that capture the causal and temporal dynamics inherent in video content. To address this gap, we propose NarrativeBridge, an approach comprising of: (1) a novel Causal-Temporal Narrative (CTN) captions benchmark generated using a large language model and few-shot prompting, explicitly encoding cause-effect temporal relationships in video descriptions, evaluated automatically to ensure caption quality and relevance; and (2) a dedicated Cause-Effect Network (CEN) architecture with separate encoders for capturing cause and effect dynamics independently, enabling effective learning and generation of captions with causal-temporal narrative. Extensive experiments demonstrate that CEN is more accurate in articulating the causal and temporal aspects of video content than the second best model (GIT): 17.88 and 17.44 CIDEr on the MSVD and MSR-VTT datasets, respectively. The proposed framework understands and generates nuanced text descriptions with intricate causal-temporal narrative structures present in videos, addressing a critical limitation in video captioning. For project details, visit https://narrativebridge.github.io/.
Subcellular Protein Localisation in the Human Protein Atlas using Ensembles of Diverse Deep Architectures
May 19, 2022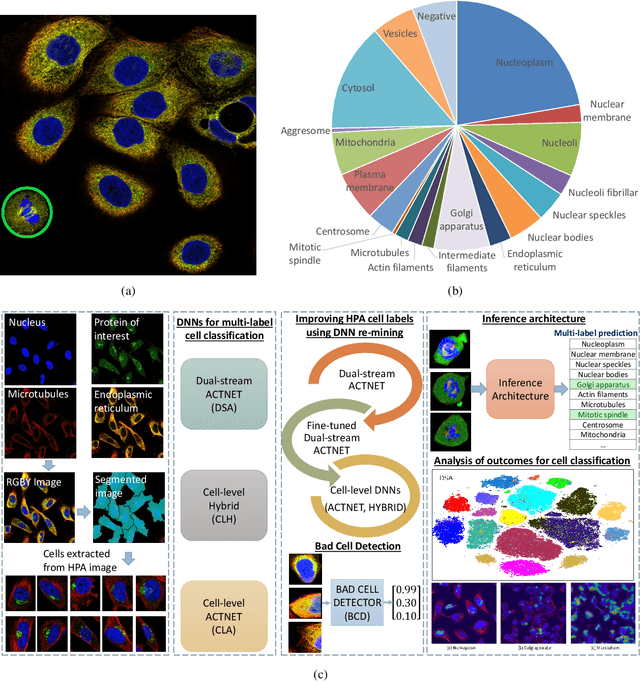
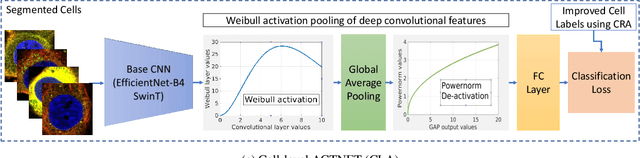
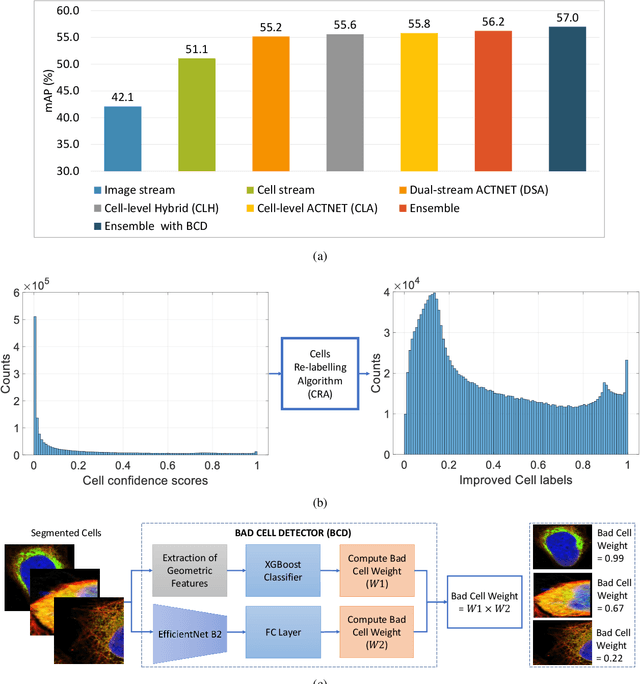
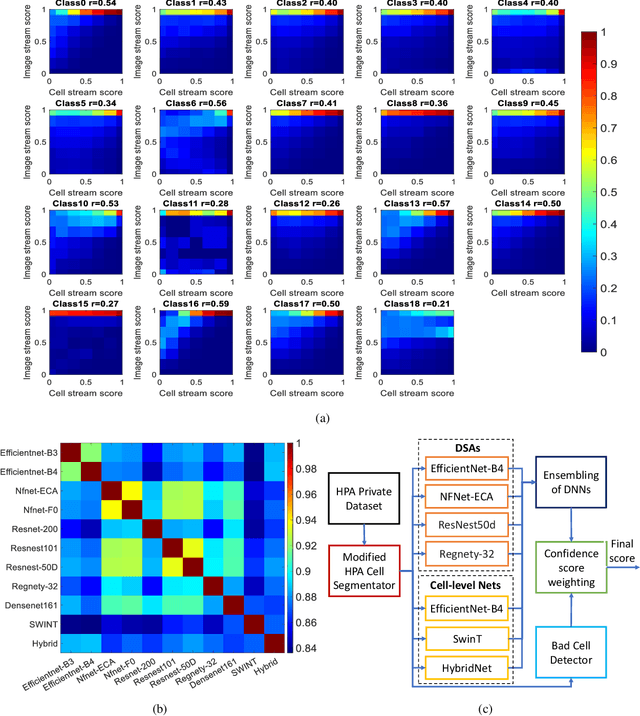
Automated visual localisation of subcellular proteins can accelerate our understanding of cell function in health and disease. Despite recent advances in machine learning (ML), humans still attain superior accuracy by using diverse clues. We show how this gap can be narrowed by addressing three key aspects: (i) automated improvement of cell annotation quality, (ii) new Convolutional Neural Network (CNN) architectures supporting unbalanced and noisy data, and (iii) informed selection and fusion of multiple & diverse machine learning models. We introduce a new "AI-trains-AI" method for improving the quality of weak labels and propose novel CNN architectures exploiting wavelet filters and Weibull activations. We also explore key factors in the multi-CNN ensembling process by analysing correlations between image-level and cell-level predictions. Finally, in the context of the Human Protein Atlas, we demonstrate that our system achieves state-of-the-art performance in the multi-label single-cell classification of protein localisation patterns. It also significantly improves generalisation ability.
ACTNET: end-to-end learning of feature activations and multi-stream aggregation for effective instance image retrieval
Jul 18, 2019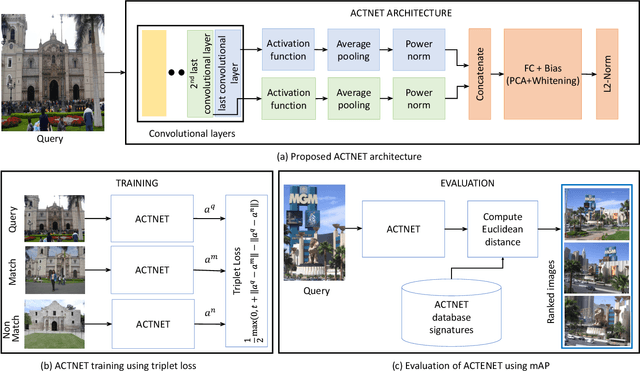
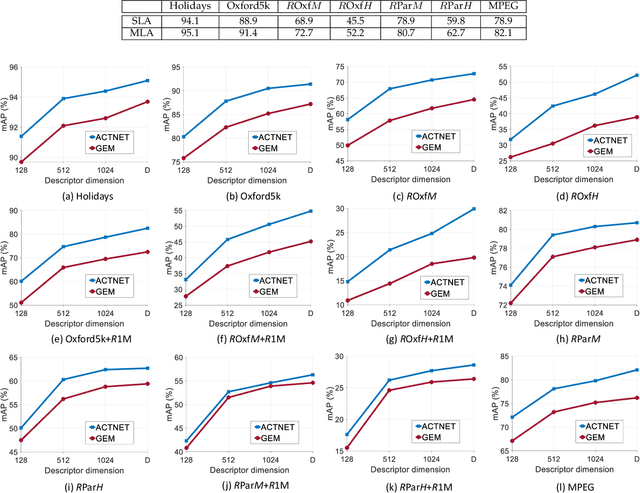
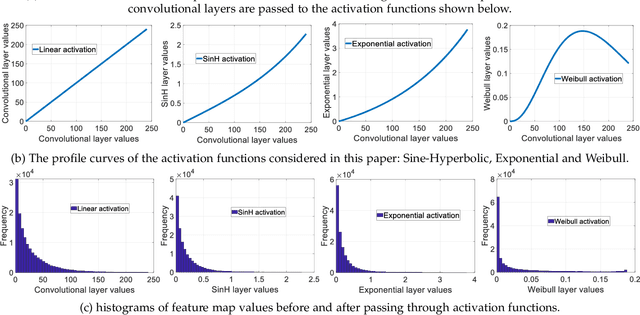

We propose a novel CNN architecture called ACTNET for robust instance image retrieval from large-scale datasets. Our key innovation is a learnable activation layer designed to improve the signal-to-noise ratio (SNR) of deep convolutional feature maps. Further, we introduce a controlled multi-stream aggregation, where complementary deep features from different convolutional layers are optimally transformed and balanced using our novel activation layers, before aggregation into a global descriptor. Importantly, the learnable parameters of our activation blocks are explicitly trained, together with the CNN parameters, in an end-to-end manner minimising triplet loss. This means that our network jointly learns the CNN filters and their optimal activation and aggregation for retrieval tasks. To our knowledge, this is the first time parametric functions have been used to control and learn optimal aggregation. We conduct an in-depth experimental study on three non-linear activation functions: Sine-Hyperbolic, Exponential and modified Weibull, showing that while all bring significant gains the Weibull function performs best thanks to its ability to equalise strong activations. The results clearly demonstrate that our ACTNET architecture significantly enhances the discriminative power of deep features, improving significantly over the state-of-the-art retrieval results on all datasets.
REMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval
Jun 15, 2019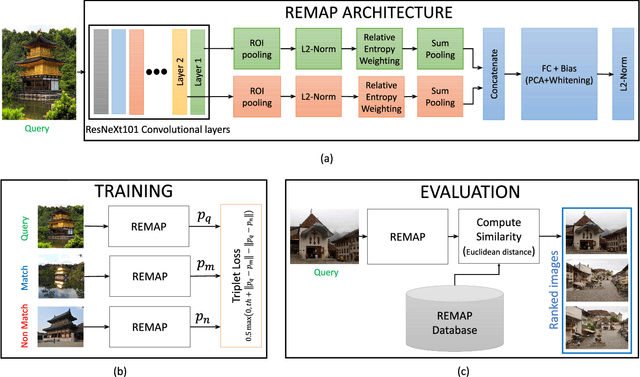
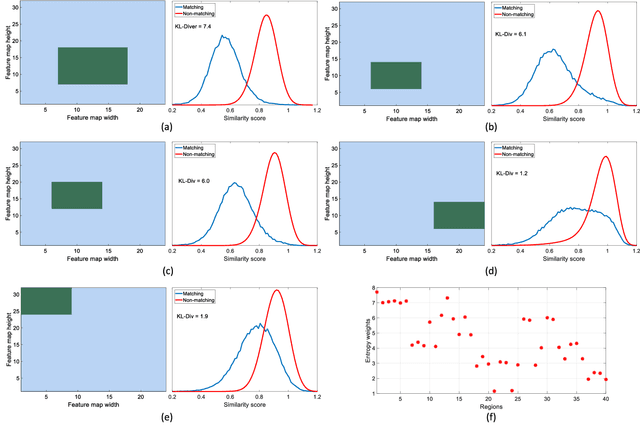

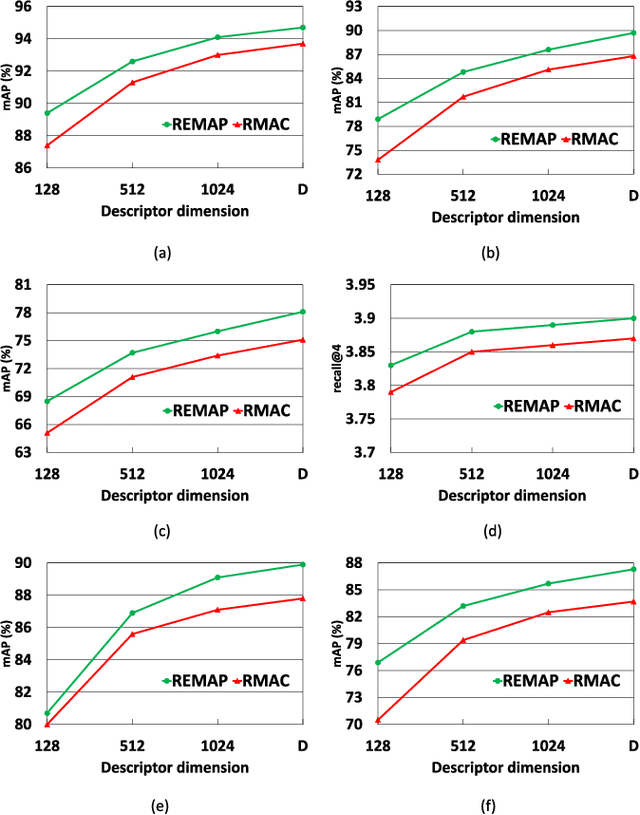
This paper addresses the problem of very large-scale image retrieval, focusing on improving its accuracy and robustness. We target enhanced robustness of search to factors such as variations in illumination, object appearance and scale, partial occlusions, and cluttered backgrounds - particularly important when search is performed across very large datasets with significant variability. We propose a novel CNN-based global descriptor, called REMAP, which learns and aggregates a hierarchy of deep features from multiple CNN layers, and is trained end-to-end with a triplet loss. REMAP explicitly learns discriminative features which are mutually-supportive and complementary at various semantic levels of visual abstraction. These dense local features are max-pooled spatially at each layer, within multi-scale overlapping regions, before aggregation into a single image-level descriptor. To identify the semantically useful regions and layers for retrieval, we propose to measure the information gain of each region and layer using KL-divergence. Our system effectively learns during training how useful various regions and layers are and weights them accordingly. We show that such relative entropy-guided aggregation outperforms classical CNN-based aggregation controlled by SGD. The entire framework is trained in an end-to-end fashion, outperforming the latest state-of-the-art results. On image retrieval datasets Holidays, Oxford and MPEG, the REMAP descriptor achieves mAP of 95.5%, 91.5%, and 80.1% respectively, outperforming any results published to date. REMAP also formed the core of the winning submission to the Google Landmark Retrieval Challenge on Kaggle.
* Submitted to IEEE Trans. Image Processing on 24 May 2018, published 22 May 2019