 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval
Paper and Code
Jun 15, 2019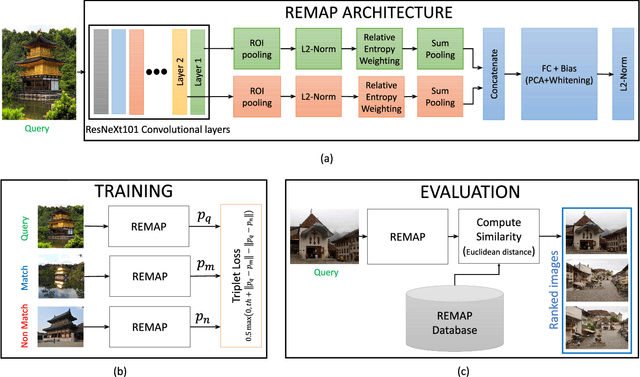
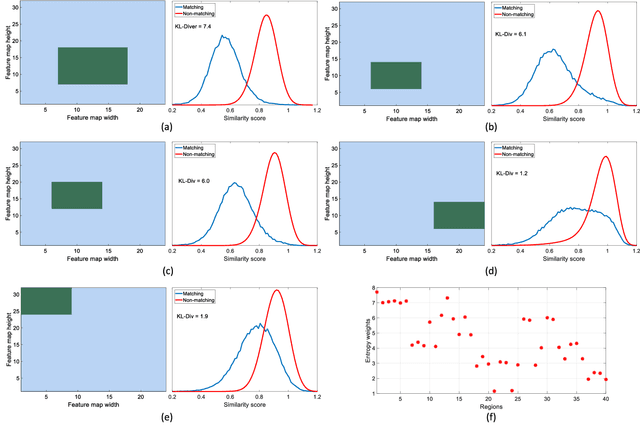

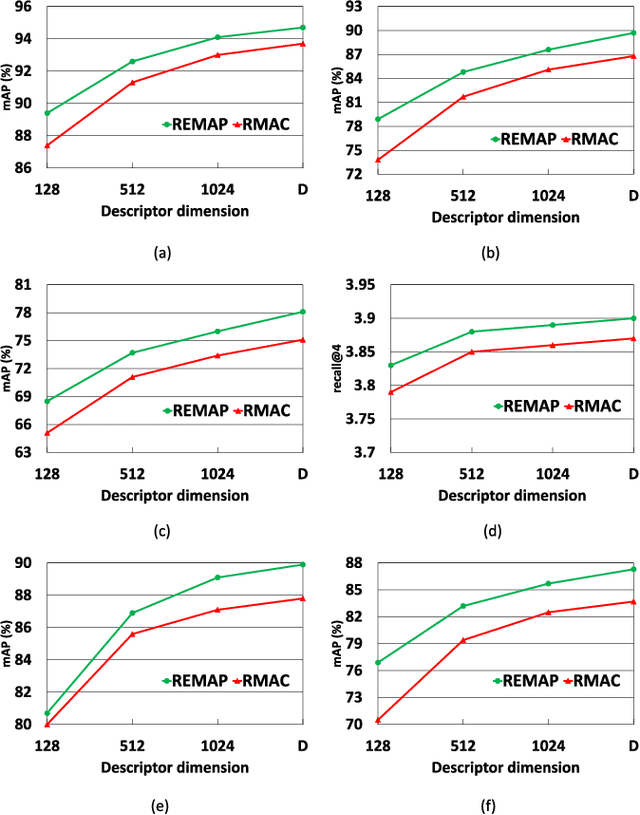
This paper addresses the problem of very large-scale image retrieval, focusing on improving its accuracy and robustness. We target enhanced robustness of search to factors such as variations in illumination, object appearance and scale, partial occlusions, and cluttered backgrounds - particularly important when search is performed across very large datasets with significant variability. We propose a novel CNN-based global descriptor, called REMAP, which learns and aggregates a hierarchy of deep features from multiple CNN layers, and is trained end-to-end with a triplet loss. REMAP explicitly learns discriminative features which are mutually-supportive and complementary at various semantic levels of visual abstraction. These dense local features are max-pooled spatially at each layer, within multi-scale overlapping regions, before aggregation into a single image-level descriptor. To identify the semantically useful regions and layers for retrieval, we propose to measure the information gain of each region and layer using KL-divergence. Our system effectively learns during training how useful various regions and layers are and weights them accordingly. We show that such relative entropy-guided aggregation outperforms classical CNN-based aggregation controlled by SGD. The entire framework is trained in an end-to-end fashion, outperforming the latest state-of-the-art results. On image retrieval datasets Holidays, Oxford and MPEG, the REMAP descriptor achieves mAP of 95.5%, 91.5%, and 80.1% respectively, outperforming any results published to date. REMAP also formed the core of the winning submission to the Google Landmark Retrieval Challenge on Kaggle.