 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYYDS: Visible-Infrared Person Re-Identification with Coarse Descriptions
Paper and Code

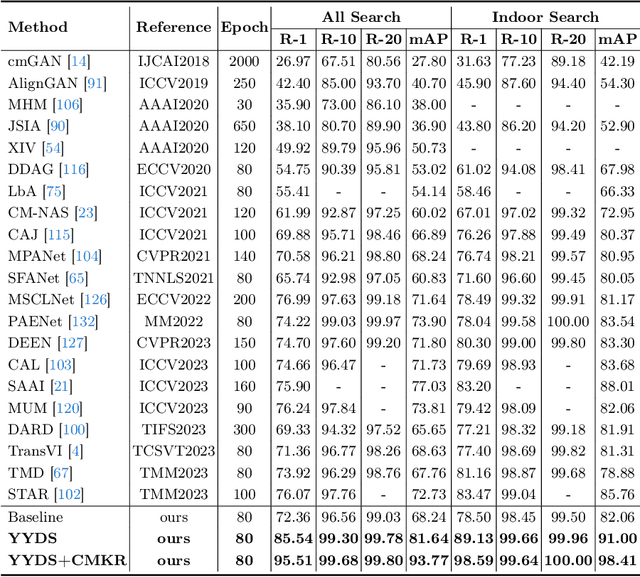


Visible-infrared person re-identification (VI-ReID) is challenging due to considerable cross-modality discrepancies. Existing works mainly focus on learning modality-invariant features while suppressing modality-specific ones. However, retrieving visible images only depends on infrared samples is an extreme problem because of the absence of color information. To this end, we present the Refer-VI-ReID settings, which aims to match target visible images from both infrared images and coarse language descriptions (e.g., "a man with red top and black pants") to complement the missing color information. To address this task, we design a Y-Y-shape decomposition structure, dubbed YYDS, to decompose and aggregate texture and color features of targets. Specifically, the text-IoU regularization strategy is firstly presented to facilitate the decomposition training, and a joint relation module is then proposed to infer the aggregation. Furthermore, the cross-modal version of k-reciprocal re-ranking algorithm is investigated, named CMKR, in which three neighbor search strategies and one local query expansion method are explored to alleviate the modality bias problem of the near neighbors. We conduct experiments on SYSU-MM01, RegDB and LLCM datasets with our manually annotated descriptions. Both YYDS and CMKR achieve remarkable improvements over SOTA methods on all three datasets. Codes are available at https://github.com/dyhBUPT/YYDS.