 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Probe-based Steering for Robust LLM Jailbreaking
May 19, 2026Recent work has demonstrated the potential of contrastive steering for jailbreaking Large Language Models (LLMs). However, existing methods rely on limited and inherently biased contrastive prompts and require laborious manual tuning of steering strength, limiting their robustness and effectiveness. In this paper, we leverage the idea of model extraction to guide the learned steering vectors to approximate the ideal one and propose tuning the steering strength adaptively based on contrastive activations' statistics. Experiments demonstrate that our method notably improves the effectiveness and robustness of probe-based steering, without any extra contrastive prompts or laborious manual tuning. Being an attack paper, this paper focuses on revealing the breakdown of fortified LLMs, raising the average harmfulness score from 6\% to 70\%. Our code is available at https://github.com/fhdnskfbeuv/adaptiveSteering.
Mind the Trojan Horse: Image Prompt Adapter Enabling Scalable and Deceptive Jailbreaking
Apr 08, 2025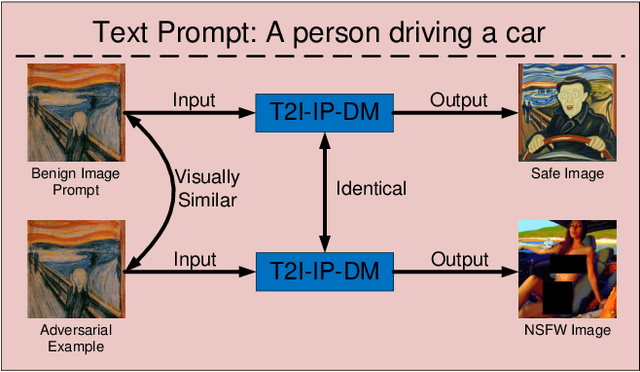
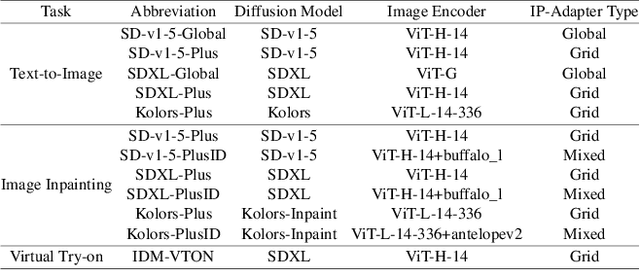
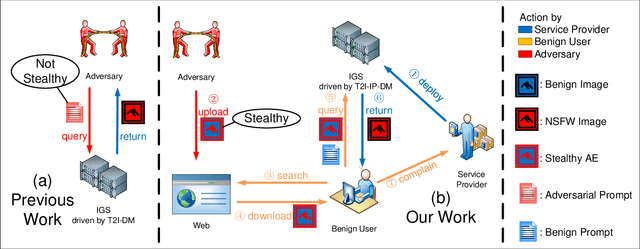
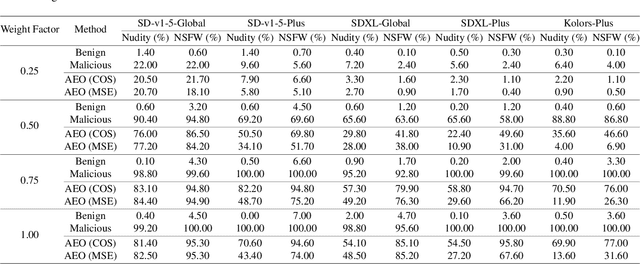
Recently, the Image Prompt Adapter (IP-Adapter) has been increasingly integrated into text-to-image diffusion models (T2I-DMs) to improve controllability. However, in this paper, we reveal that T2I-DMs equipped with the IP-Adapter (T2I-IP-DMs) enable a new jailbreak attack named the hijacking attack. We demonstrate that, by uploading imperceptible image-space adversarial examples (AEs), the adversary can hijack massive benign users to jailbreak an Image Generation Service (IGS) driven by T2I-IP-DMs and mislead the public to discredit the service provider. Worse still, the IP-Adapter's dependency on open-source image encoders reduces the knowledge required to craft AEs. Extensive experiments verify the technical feasibility of the hijacking attack. In light of the revealed threat, we investigate several existing defenses and explore combining the IP-Adapter with adversarially trained models to overcome existing defenses' limitations. Our code is available at https://github.com/fhdnskfbeuv/attackIPA.
Exploring Adversarial Attacks against Latent Diffusion Model from the Perspective of Adversarial Transferability
Jan 13, 2024Recently, many studies utilized adversarial examples (AEs) to raise the cost of malicious image editing and copyright violation powered by latent diffusion models (LDMs). Despite their successes, a few have studied the surrogate model they used to generate AEs. In this paper, from the perspective of adversarial transferability, we investigate how the surrogate model's property influences the performance of AEs for LDMs. Specifically, we view the time-step sampling in the Monte-Carlo-based (MC-based) adversarial attack as selecting surrogate models. We find that the smoothness of surrogate models at different time steps differs, and we substantially improve the performance of the MC-based AEs by selecting smoother surrogate models. In the light of the theoretical framework on adversarial transferability in image classification, we also conduct a theoretical analysis to explain why smooth surrogate models can also boost AEs for LDMs.
Releasing Inequality Phenomena in $L_{\infty}$-Adversarial Training via Input Gradient Distillation
May 17, 2023Since adversarial examples appeared and showed the catastrophic degradation they brought to DNN, many adversarial defense methods have been devised, among which adversarial training is considered the most effective. However, a recent work showed the inequality phenomena in $l_{\infty}$-adversarial training and revealed that the $l_{\infty}$-adversarially trained model is vulnerable when a few important pixels are perturbed by i.i.d. noise or occluded. In this paper, we propose a simple yet effective method called Input Gradient Distillation (IGD) to release the inequality phenomena in $l_{\infty}$-adversarial training. Experiments show that while preserving the model's adversarial robustness, compared to PGDAT, IGD decreases the $l_{\infty}$-adversarially trained model's error rate to inductive noise and inductive occlusion by up to 60\% and 16.53\%, and to noisy images in Imagenet-C by up to 21.11\%. Moreover, we formally explain why the equality of the model's saliency map can improve such robustness.
Adversarial Attack and Defense for Medical Image Analysis: Methods and Applications
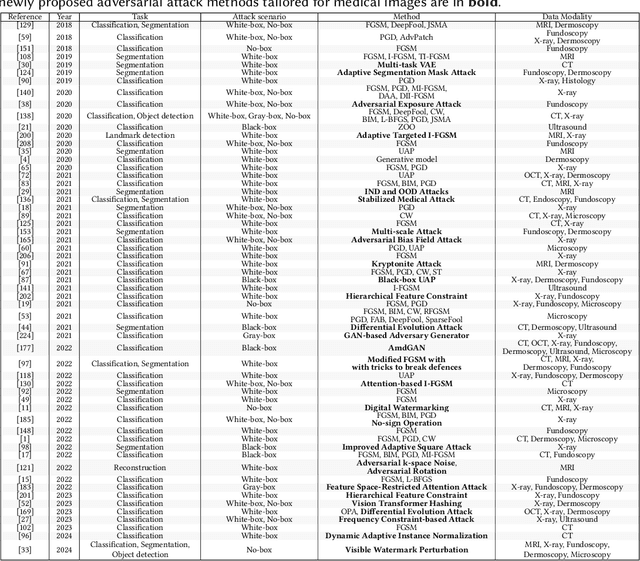
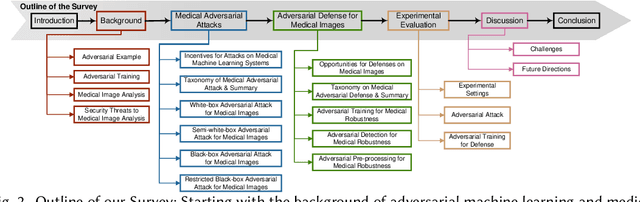
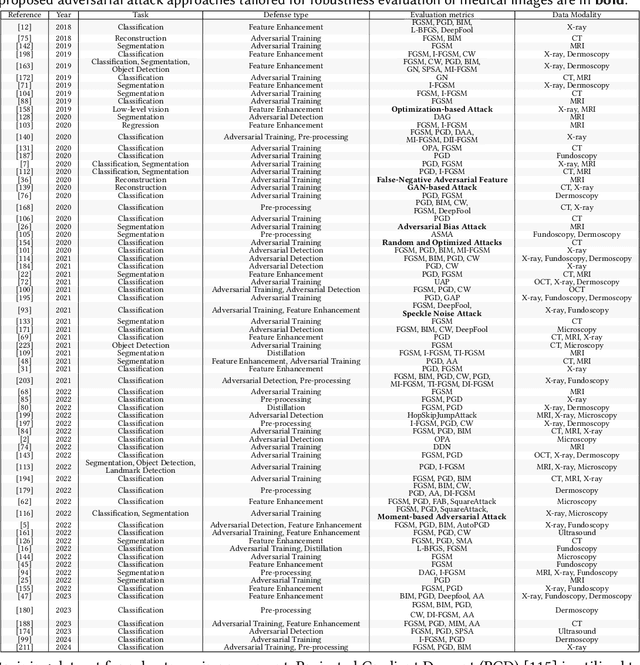
Mar 24, 2023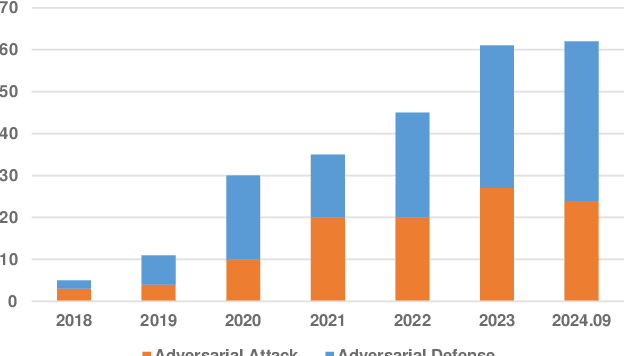
Deep learning techniques have achieved superior performance in computer-aided medical image analysis, yet they are still vulnerable to imperceptible adversarial attacks, resulting in potential misdiagnosis in clinical practice. Oppositely, recent years have also witnessed remarkable progress in defense against these tailored adversarial examples in deep medical diagnosis systems. In this exposition, we present a comprehensive survey on recent advances in adversarial attack and defense for medical image analysis with a novel taxonomy in terms of the application scenario. We also provide a unified theoretical framework for different types of adversarial attack and defense methods for medical image analysis. For a fair comparison, we establish a new benchmark for adversarially robust medical diagnosis models obtained by adversarial training under various scenarios. To the best of our knowledge, this is the first survey paper that provides a thorough evaluation of adversarially robust medical diagnosis models. By analyzing qualitative and quantitative results, we conclude this survey with a detailed discussion of current challenges for adversarial attack and defense in medical image analysis systems to shed light on future research directions.