 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Adversarial Robustness via Uncertainty-Aware Distributional Adversarial Training
Paper and Code
Nov 05, 2024

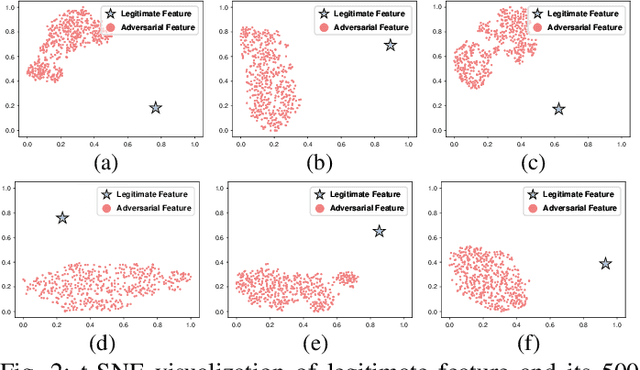
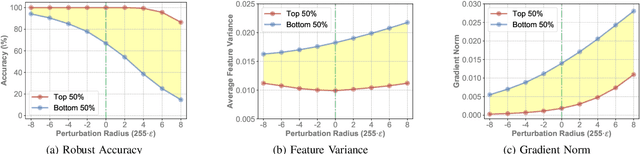
Despite remarkable achievements in deep learning across various domains, its inherent vulnerability to adversarial examples still remains a critical concern for practical deployment. Adversarial training has emerged as one of the most effective defensive techniques for improving model robustness against such malicious inputs. However, existing adversarial training schemes often lead to limited generalization ability against underlying adversaries with diversity due to their overreliance on a point-by-point augmentation strategy by mapping each clean example to its adversarial counterpart during training. In addition, adversarial examples can induce significant disruptions in the statistical information w.r.t. the target model, thereby introducing substantial uncertainty and challenges to modeling the distribution of adversarial examples. To circumvent these issues, in this paper, we propose a novel uncertainty-aware distributional adversarial training method, which enforces adversary modeling by leveraging both the statistical information of adversarial examples and its corresponding uncertainty estimation, with the goal of augmenting the diversity of adversaries. Considering the potentially negative impact induced by aligning adversaries to misclassified clean examples, we also refine the alignment reference based on the statistical proximity to clean examples during adversarial training, thereby reframing adversarial training within a distribution-to-distribution matching framework interacted between the clean and adversarial domains. Furthermore, we design an introspective gradient alignment approach via matching input gradients between these domains without introducing external models. Extensive experiments across four benchmark datasets and various network architectures demonstrate that our approach achieves state-of-the-art adversarial robustness and maintains natural performance.