 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study on the impact of pre-trained model on Just-In-Time defect prediction
Sep 05, 2023
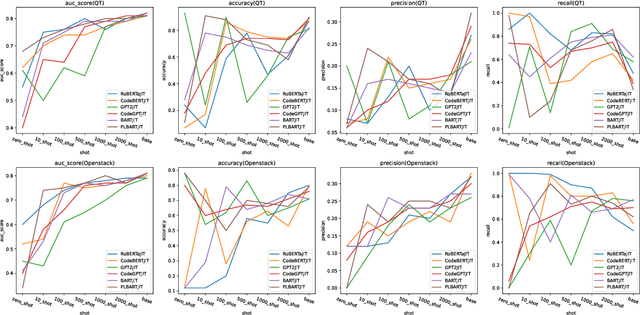
Previous researchers conducting Just-In-Time (JIT) defect prediction tasks have primarily focused on the performance of individual pre-trained models, without exploring the relationship between different pre-trained models as backbones. In this study, we build six models: RoBERTaJIT, CodeBERTJIT, BARTJIT, PLBARTJIT, GPT2JIT, and CodeGPTJIT, each with a distinct pre-trained model as its backbone. We systematically explore the differences and connections between these models. Specifically, we investigate the performance of the models when using Commit code and Commit message as inputs, as well as the relationship between training efficiency and model distribution among these six models. Additionally, we conduct an ablation experiment to explore the sensitivity of each model to inputs. Furthermore, we investigate how the models perform in zero-shot and few-shot scenarios. Our findings indicate that each model based on different backbones shows improvements, and when the backbone's pre-training model is similar, the training resources that need to be consumed are much more closer. We also observe that Commit code plays a significant role in defect detection, and different pre-trained models demonstrate better defect detection ability with a balanced dataset under few-shot scenarios. These results provide new insights for optimizing JIT defect prediction tasks using pre-trained models and highlight the factors that require more attention when constructing such models. Additionally, CodeGPTJIT and GPT2JIT achieved better performance than DeepJIT and CC2Vec on the two datasets respectively under 2000 training samples. These findings emphasize the effectiveness of transformer-based pre-trained models in JIT defect prediction tasks, especially in scenarios with limited training data.
Wasserstein Distance Regularized Sequence Representation for Text Matching in Asymmetrical Domains
Oct 17, 2020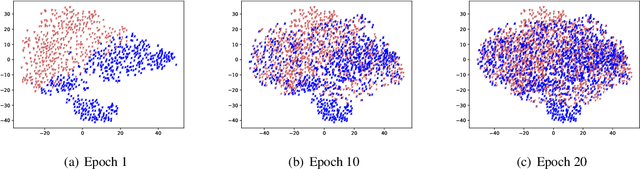

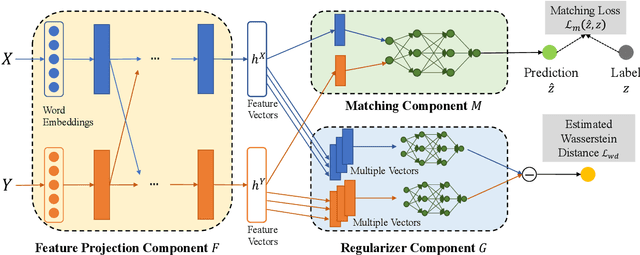
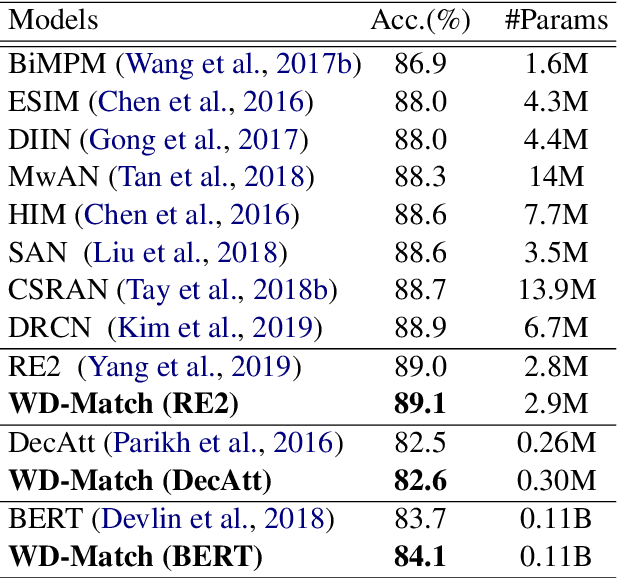
One approach to matching texts from asymmetrical domains is projecting the input sequences into a common semantic space as feature vectors upon which the matching function can be readily defined and learned. In real-world matching practices, it is often observed that with the training goes on, the feature vectors projected from different domains tend to be indistinguishable. The phenomenon, however, is often overlooked in existing matching models. As a result, the feature vectors are constructed without any regularization, which inevitably increases the difficulty of learning the downstream matching functions. In this paper, we propose a novel match method tailored for text matching in asymmetrical domains, called WD-Match. In WD-Match, a Wasserstein distance-based regularizer is defined to regularize the features vectors projected from different domains. As a result, the method enforces the feature projection function to generate vectors such that those correspond to different domains cannot be easily discriminated. The training process of WD-Match amounts to a game that minimizes the matching loss regularized by the Wasserstein distance. WD-Match can be used to improve different text matching methods, by using the method as its underlying matching model. Four popular text matching methods have been exploited in the paper. Experimental results based on four publicly available benchmarks showed that WD-Match consistently outperformed the underlying methods and the baselines.