 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025



Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.
Learning Event Completeness for Weakly Supervised Video Anomaly Detection
Jun 16, 2025Weakly supervised video anomaly detection (WS-VAD) is tasked with pinpointing temporal intervals containing anomalous events within untrimmed videos, utilizing only video-level annotations. However, a significant challenge arises due to the absence of dense frame-level annotations, often leading to incomplete localization in existing WS-VAD methods. To address this issue, we present a novel LEC-VAD, Learning Event Completeness for Weakly Supervised Video Anomaly Detection, which features a dual structure designed to encode both category-aware and category-agnostic semantics between vision and language. Within LEC-VAD, we devise semantic regularities that leverage an anomaly-aware Gaussian mixture to learn precise event boundaries, thereby yielding more complete event instances. Besides, we develop a novel memory bank-based prototype learning mechanism to enrich concise text descriptions associated with anomaly-event categories. This innovation bolsters the text's expressiveness, which is crucial for advancing WS-VAD. Our LEC-VAD demonstrates remarkable advancements over the current state-of-the-art methods on two benchmark datasets XD-Violence and UCF-Crime.
Distilling Fine-grained Sentiment Understanding from Large Language Models
Dec 24, 2024Fine-grained sentiment analysis (FSA) aims to extract and summarize user opinions from vast opinionated text. Recent studies demonstrate that large language models (LLMs) possess exceptional sentiment understanding capabilities. However, directly deploying LLMs for FSA applications incurs high inference costs. Therefore, this paper investigates the distillation of fine-grained sentiment understanding from LLMs into small language models (SLMs). We prompt LLMs to examine and interpret the sentiments of given reviews and then utilize the generated content to pretrain SLMs. Additionally, we develop a comprehensive FSA benchmark to evaluate both SLMs and LLMs. Extensive experiments on this benchmark reveal that: (1) distillation significantly enhances the performance of SLMs in FSA tasks, achieving a 6.00\% improvement in $F_1$-score, and the distilled model can outperform Llama-2-7b with only 220M parameters; (2) distillation equips SLMs with excellent zero-shot sentiment classification capabilities, enabling them to match or even exceed their teacher models. These results suggest that distillation from LLMs is a highly promising direction for FSA. We will release our code, data, and pretrained model weights at \url{https://github.com/HITSZ-HLT/FSA-Distillation}.
Self-Training with Pseudo-Label Scorer for Aspect Sentiment Quad Prediction
Jun 26, 2024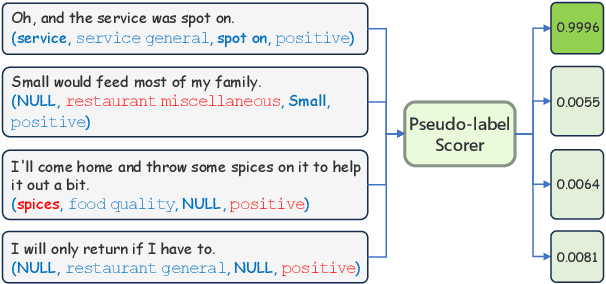
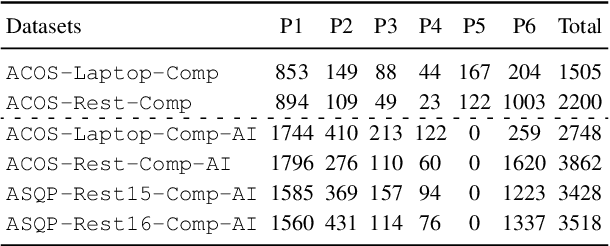
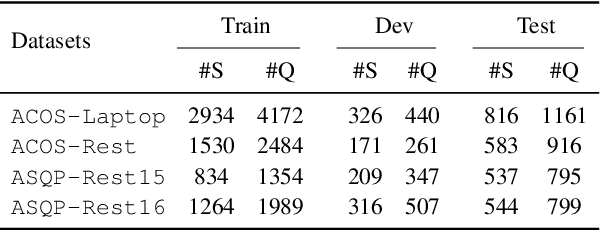
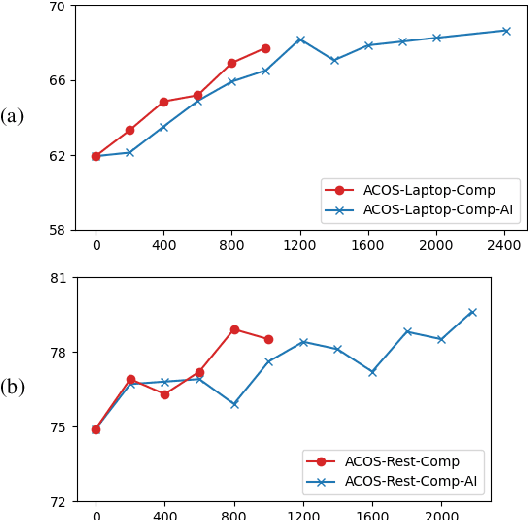
Aspect Sentiment Quad Prediction (ASQP) aims to predict all quads (aspect term, aspect category, opinion term, sentiment polarity) for a given review, which is the most representative and challenging task in aspect-based sentiment analysis. A key challenge in the ASQP task is the scarcity of labeled data, which limits the performance of existing methods. To tackle this issue, we propose a self-training framework with a pseudo-label scorer, wherein a scorer assesses the match between reviews and their pseudo-labels, aiming to filter out mismatches and thereby enhance the effectiveness of self-training. We highlight two critical aspects to ensure the scorer's effectiveness and reliability: the quality of the training dataset and its model architecture. To this end, we create a human-annotated comparison dataset and train a generative model on it using ranking-based objectives. Extensive experiments on public ASQP datasets reveal that using our scorer can greatly and consistently improve the effectiveness of self-training. Moreover, we explore the possibility of replacing humans with large language models for comparison dataset annotation, and experiments demonstrate its feasibility. We release our code and data at https://github.com/HITSZ-HLT/ST-w-Scorer-ABSA .
SafePaint: Anti-forensic Image Inpainting with Domain Adaptation
Apr 28, 2024



Existing image inpainting methods have achieved remarkable accomplishments in generating visually appealing results, often accompanied by a trend toward creating more intricate structural textures. However, while these models excel at creating more realistic image content, they often leave noticeable traces of tampering, posing a significant threat to security. In this work, we take the anti-forensic capabilities into consideration, firstly proposing an end-to-end training framework for anti-forensic image inpainting named SafePaint. Specifically, we innovatively formulated image inpainting as two major tasks: semantically plausible content completion and region-wise optimization. The former is similar to current inpainting methods that aim to restore the missing regions of corrupted images. The latter, through domain adaptation, endeavors to reconcile the discrepancies between the inpainted region and the unaltered area to achieve anti-forensic goals. Through comprehensive theoretical analysis, we validate the effectiveness of domain adaptation for anti-forensic performance. Furthermore, we meticulously crafted a region-wise separated attention (RWSA) module, which not only aligns with our objective of anti-forensics but also enhances the performance of the model. Extensive qualitative and quantitative evaluations show our approach achieves comparable results to existing image inpainting methods while offering anti-forensic capabilities not available in other methods.