 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve-Refine-Calibrate: A Framework for Complex Claim Fact-Checking
Jan 23, 2026Fact-checking aims to verify the truthfulness of a claim based on the retrieved evidence. Existing methods typically follow a decomposition paradigm, in which a claim is broken down into sub-claims that are individually verified. However, the decomposition paradigm may introduce noise to the verification process due to irrelevant entities or evidence, ultimately degrading verification accuracy. To address this problem, we propose a Retrieve-Refine-Calibrate (RRC) framework based on large language models (LLMs). Specifically, the framework first identifies the entities mentioned in the claim and retrieves evidence relevant to them. Then, it refines the retrieved evidence based on the claim to reduce irrelevant information. Finally, it calibrates the verification process by re-evaluating low-confidence predictions. Experiments on two popular fact-checking datasets (HOVER and FEVEROUS-S) demonstrate that our framework achieves superior performance compared with competitive baselines.
Targeted Distillation for Sentiment Analysis
Mar 05, 2025This paper presents a compact model that achieves strong sentiment analysis capabilities through targeted distillation from advanced large language models (LLMs). Our methodology decouples the distillation target into two key components: sentiment-related knowledge and task alignment. To transfer these components, we propose a two-stage distillation framework. The first stage, knowledge-driven distillation (\textsc{KnowDist}), transfers sentiment-related knowledge to enhance fundamental sentiment analysis capabilities. The second stage, in-context learning distillation (\textsc{ICLDist}), transfers task-specific prompt-following abilities to optimize task alignment. For evaluation, we introduce \textsc{SentiBench}, a comprehensive sentiment analysis benchmark comprising 3 task categories across 12 datasets. Experiments on this benchmark demonstrate that our model effectively balances model size and performance, showing strong competitiveness compared to existing small-scale LLMs.
Distilling Fine-grained Sentiment Understanding from Large Language Models
Dec 24, 2024Fine-grained sentiment analysis (FSA) aims to extract and summarize user opinions from vast opinionated text. Recent studies demonstrate that large language models (LLMs) possess exceptional sentiment understanding capabilities. However, directly deploying LLMs for FSA applications incurs high inference costs. Therefore, this paper investigates the distillation of fine-grained sentiment understanding from LLMs into small language models (SLMs). We prompt LLMs to examine and interpret the sentiments of given reviews and then utilize the generated content to pretrain SLMs. Additionally, we develop a comprehensive FSA benchmark to evaluate both SLMs and LLMs. Extensive experiments on this benchmark reveal that: (1) distillation significantly enhances the performance of SLMs in FSA tasks, achieving a 6.00\% improvement in $F_1$-score, and the distilled model can outperform Llama-2-7b with only 220M parameters; (2) distillation equips SLMs with excellent zero-shot sentiment classification capabilities, enabling them to match or even exceed their teacher models. These results suggest that distillation from LLMs is a highly promising direction for FSA. We will release our code, data, and pretrained model weights at \url{https://github.com/HITSZ-HLT/FSA-Distillation}.
DS$^2$-ABSA: Dual-Stream Data Synthesis with Label Refinement for Few-Shot Aspect-Based Sentiment Analysis
Dec 19, 2024



Recently developed large language models (LLMs) have presented promising new avenues to address data scarcity in low-resource scenarios. In few-shot aspect-based sentiment analysis (ABSA), previous efforts have explored data augmentation techniques, which prompt LLMs to generate new samples by modifying existing ones. However, these methods fail to produce adequately diverse data, impairing their effectiveness. Besides, some studies apply in-context learning for ABSA by using specific instructions and a few selected examples as prompts. Though promising, LLMs often yield labels that deviate from task requirements. To overcome these limitations, we propose DS$^2$-ABSA, a dual-stream data synthesis framework targeted for few-shot ABSA. It leverages LLMs to synthesize data from two complementary perspectives: \textit{key-point-driven} and \textit{instance-driven}, which effectively generate diverse and high-quality ABSA samples in low-resource settings. Furthermore, a \textit{label refinement} module is integrated to improve the synthetic labels. Extensive experiments demonstrate that DS$^2$-ABSA significantly outperforms previous few-shot ABSA solutions and other LLM-oriented data generation methods.
Improving In-Context Learning with Prediction Feedback for Sentiment Analysis
Jun 05, 2024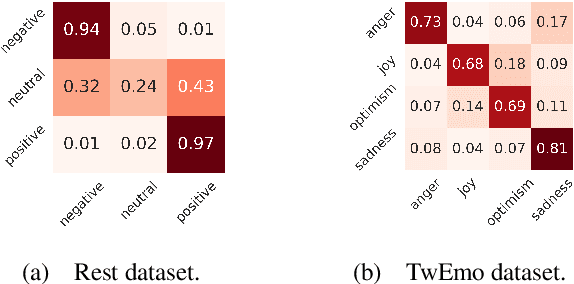
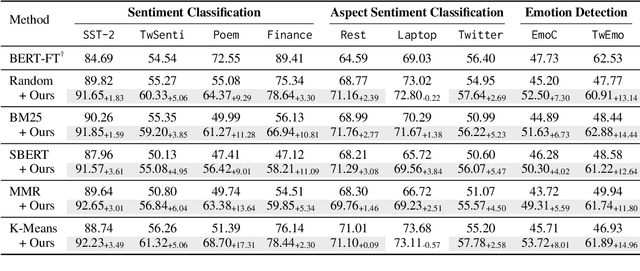

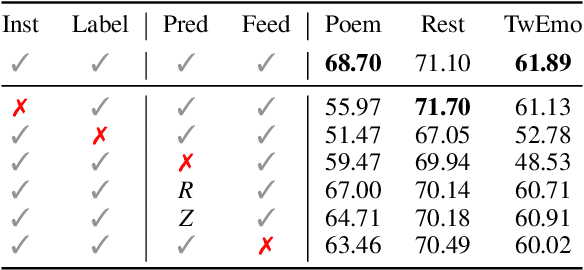
Large language models (LLMs) have achieved promising results in sentiment analysis through the in-context learning (ICL) paradigm. However, their ability to distinguish subtle sentiments still remains a challenge. Inspired by the human ability to adjust understanding via feedback, this paper enhances ICL by incorporating prior predictions and feedback, aiming to rectify sentiment misinterpretation of LLMs. Specifically, the proposed framework consists of three steps: (1) acquiring prior predictions of LLMs, (2) devising predictive feedback based on correctness, and (3) leveraging a feedback-driven prompt to refine sentiment understanding. Experimental results across nine sentiment analysis datasets demonstrate the superiority of our framework over conventional ICL methods, with an average F1 improvement of 5.95%.