 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Distillation for Sentiment Analysis
Mar 05, 2025This paper presents a compact model that achieves strong sentiment analysis capabilities through targeted distillation from advanced large language models (LLMs). Our methodology decouples the distillation target into two key components: sentiment-related knowledge and task alignment. To transfer these components, we propose a two-stage distillation framework. The first stage, knowledge-driven distillation (\textsc{KnowDist}), transfers sentiment-related knowledge to enhance fundamental sentiment analysis capabilities. The second stage, in-context learning distillation (\textsc{ICLDist}), transfers task-specific prompt-following abilities to optimize task alignment. For evaluation, we introduce \textsc{SentiBench}, a comprehensive sentiment analysis benchmark comprising 3 task categories across 12 datasets. Experiments on this benchmark demonstrate that our model effectively balances model size and performance, showing strong competitiveness compared to existing small-scale LLMs.
Improving In-Context Learning with Prediction Feedback for Sentiment Analysis
Jun 05, 2024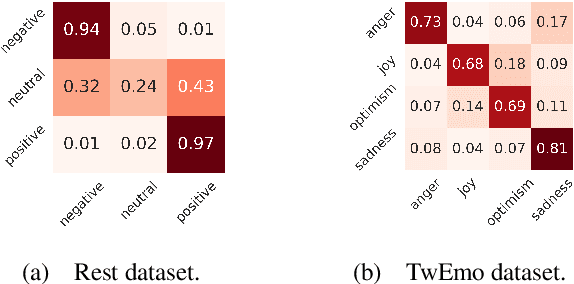
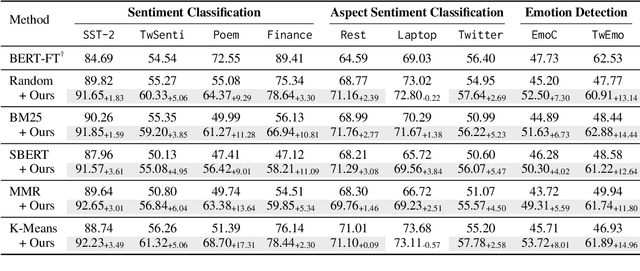

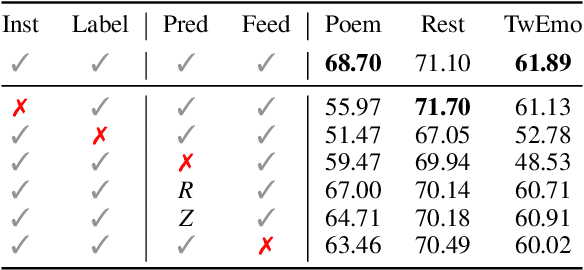
Large language models (LLMs) have achieved promising results in sentiment analysis through the in-context learning (ICL) paradigm. However, their ability to distinguish subtle sentiments still remains a challenge. Inspired by the human ability to adjust understanding via feedback, this paper enhances ICL by incorporating prior predictions and feedback, aiming to rectify sentiment misinterpretation of LLMs. Specifically, the proposed framework consists of three steps: (1) acquiring prior predictions of LLMs, (2) devising predictive feedback based on correctness, and (3) leveraging a feedback-driven prompt to refine sentiment understanding. Experimental results across nine sentiment analysis datasets demonstrate the superiority of our framework over conventional ICL methods, with an average F1 improvement of 5.95%.
Mitigating Biases of Large Language Models in Stance Detection with Calibration
Feb 22, 2024



Large language models (LLMs) have achieved remarkable progress in many natural language processing tasks. However, our experiment reveals that, in stance detection tasks, LLMs may generate biased stances due to spurious sentiment-stance correlation and preference towards certain individuals and topics, thus harming their performance. Therefore, in this paper, we propose to Mitigate Biases of LLMs in stance detection with Calibration (MB-Cal). In which, a novel gated calibration network is devised to mitigate the biases on the stance reasoning results from LLMs. Further, to make the calibration more accurate and generalizable, we construct counterfactual augmented data to rectify stance biases. Experimental results on in-target and zero-shot stance detection tasks show that the proposed MB-Cal can effectively mitigate biases of LLMs, achieving state-of-the-art results.