 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: The Alternating Reading Task Corpus for Speech Entrainment and Imitation
Apr 03, 2024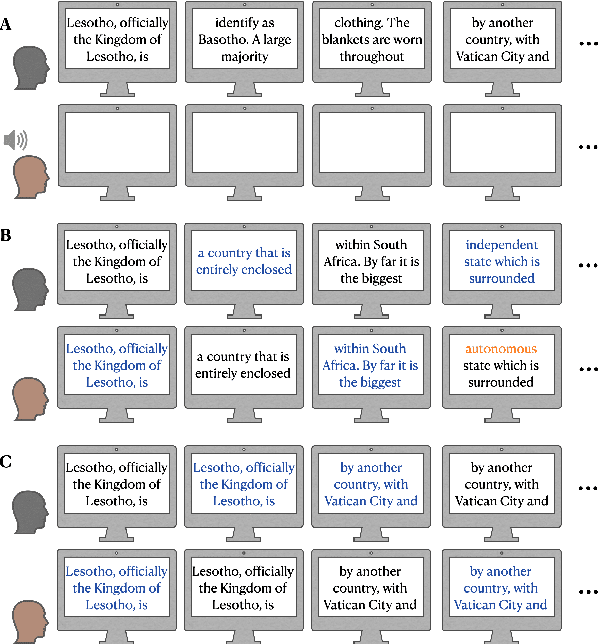
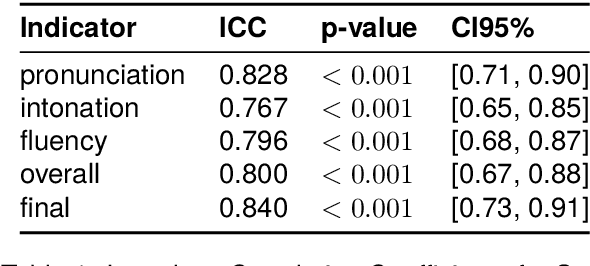
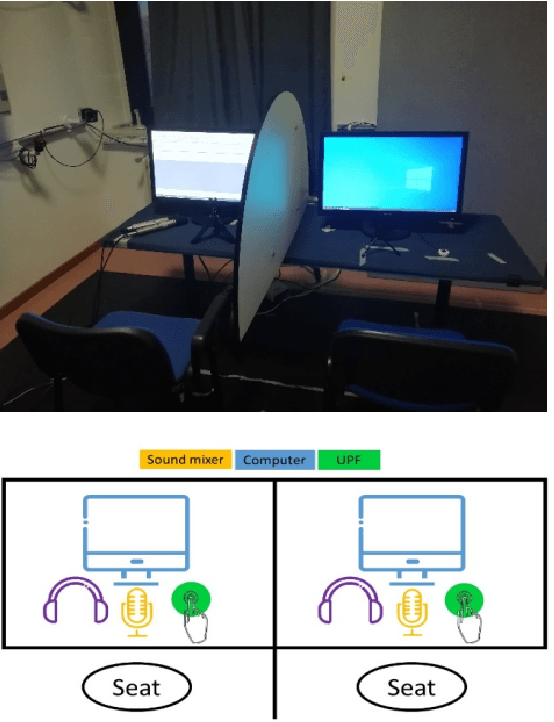
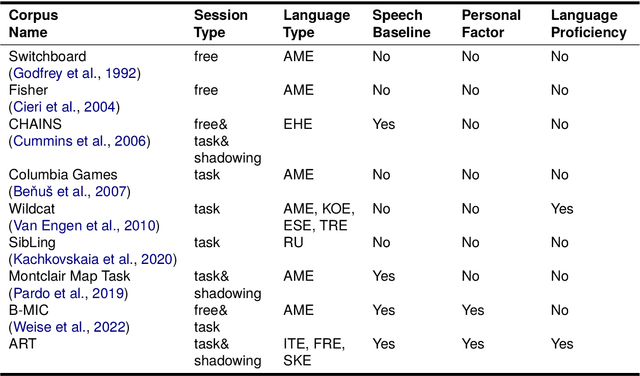
We introduce the Alternating Reading Task (ART) Corpus, a collection of dyadic sentence reading for studying the entrainment and imitation behaviour in speech communication. The ART corpus features three experimental conditions - solo reading, alternating reading, and deliberate imitation - as well as three sub-corpora encompassing French-, Italian-, and Slovak-accented English. This design allows systematic investigation of speech entrainment in a controlled and less-spontaneous setting. Alongside detailed transcriptions, it includes English proficiency scores, demographics, and in-experiment questionnaires for probing linguistic, personal and interpersonal influences on entrainment. Our presentation covers its design, collection, annotation processes, initial analysis, and future research prospects.
The ART of Conversation: Measuring Phonetic Convergence and Deliberate Imitation in L2-Speech with a Siamese RNN
Jun 08, 2023



Phonetic convergence describes the automatic and unconscious speech adaptation of two interlocutors in a conversation. This paper proposes a Siamese recurrent neural network (RNN) architecture to measure the convergence of the holistic spectral characteristics of speech sounds in an L2-L2 interaction. We extend an alternating reading task (the ART) dataset by adding 20 native Slovak L2 English speakers. We train and test the Siamese RNN model to measure phonetic convergence of L2 English speech from three different native language groups: Italian (9 dyads), French (10 dyads) and Slovak (10 dyads). Our results indicate that the Siamese RNN model effectively captures the dynamics of phonetic convergence and the speaker's imitation ability. Moreover, this text-independent model is scalable and capable of handling L1-induced speaker variability.
EasyCall corpus: a dysarthric speech dataset
Apr 06, 2021

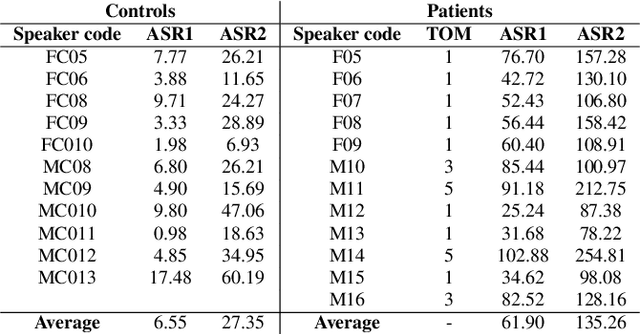
This paper introduces a new dysarthric speech command dataset in Italian, called EasyCall corpus. The dataset consists of 21386 audio recordings from 24 healthy and 31 dysarthric speakers, whose individual degree of speech impairment was assessed by neurologists through the Therapy Outcome Measure. The corpus aims at providing a resource for the development of ASR-based assistive technologies for patients with dysarthria. In particular, it may be exploited to develop a voice-controlled contact application for commercial smartphones, aiming at improving dysarthric patients' ability to communicate with their family and caregivers. Before recording the dataset, participants were administered a survey to evaluate which commands are more likely to be employed by dysarthric individuals in a voice-controlled contact application. In addition, the dataset includes a list of non-commands (i.e., words near/inside commands or phonetically close to commands) that can be leveraged to build a more robust command recognition system. At present commercial ASR systems perform poorly on the EasyCall Corpus as we report in this paper. This result corroborates the need for dysarthric speech corpora for developing effective assistive technologies. To the best of our knowledge, this database represents the richest corpus of dysarthric speech to date.
Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
Nov 06, 2018
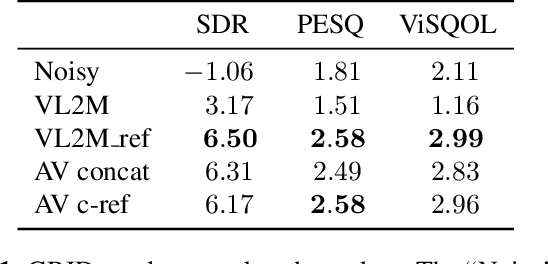
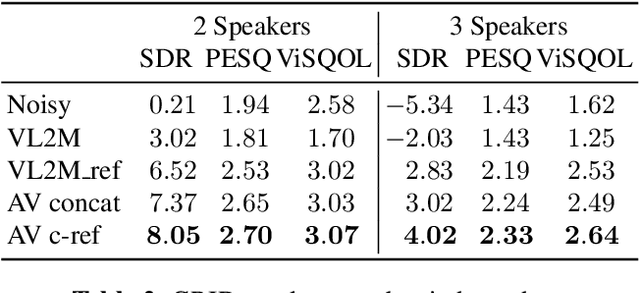
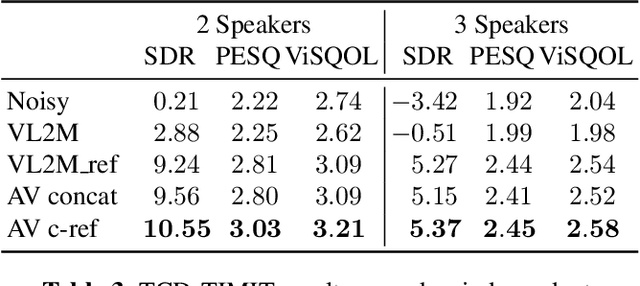
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset). The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) landmark motion features are very effective features for this task, (ii) similarly to previous work, reconstruction of the target speaker's spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. To the best of our knowledge, our proposed models are the first models trained and evaluated on the limited size GRID and TCD-TIMIT datasets, that achieve speaker-independent speech enhancement in a multi-talker setting.