 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effect of data augmentation and 3D-CNN depth on Alzheimer's Disease detection
Sep 13, 2023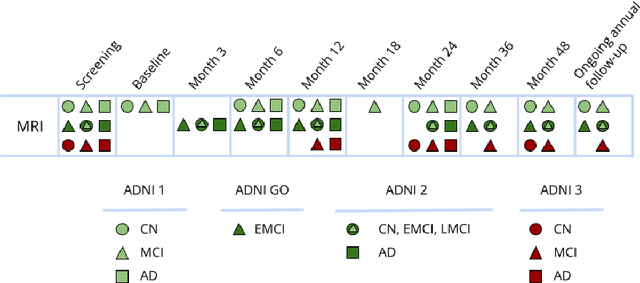
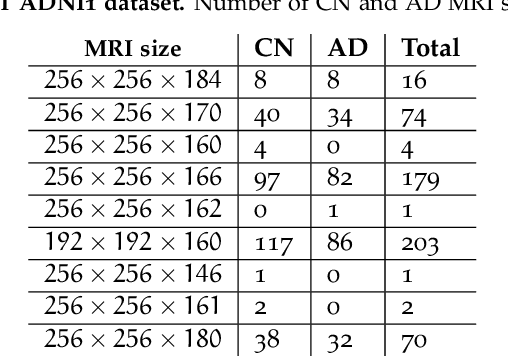
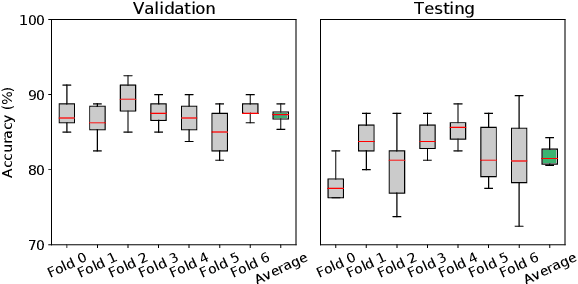
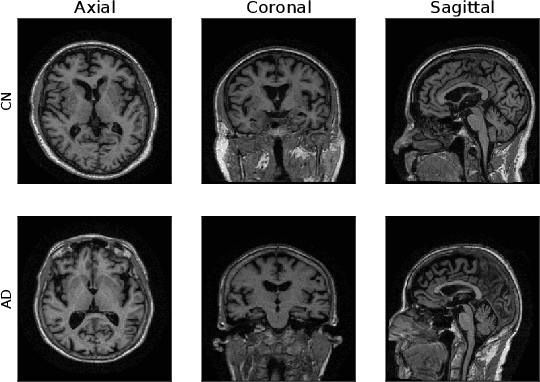
Machine Learning (ML) has emerged as a promising approach in healthcare, outperforming traditional statistical techniques. However, to establish ML as a reliable tool in clinical practice, adherence to best practices regarding data handling, experimental design, and model evaluation is crucial. This work summarizes and strictly observes such practices to ensure reproducible and reliable ML. Specifically, we focus on Alzheimer's Disease (AD) detection, which serves as a paradigmatic example of challenging problem in healthcare. We investigate the impact of different data augmentation techniques and model complexity on the overall performance. We consider MRI data from ADNI dataset to address a classification problem employing 3D Convolutional Neural Network (CNN). The experiments are designed to compensate for data scarcity and initial random parameters by utilizing cross-validation and multiple training trials. Within this framework, we train 15 predictive models, considering three different data augmentation strategies and five distinct 3D CNN architectures, each varying in the number of convolutional layers. Specifically, the augmentation strategies are based on affine transformations, such as zoom, shift, and rotation, applied concurrently or separately. The combined effect of data augmentation and model complexity leads to a variation in prediction performance up to 10% of accuracy. When affine transformation are applied separately, the model is more accurate, independently from the adopted architecture. For all strategies, the model accuracy followed a concave behavior at increasing number of convolutional layers, peaking at an intermediate value of layers. The best model (8 CL, (B)) is the most stable across cross-validation folds and training trials, reaching excellent performance both on the testing set and on an external test set.
Beyond original Research Articles Categorization via NLP
Sep 13, 2023This work proposes a novel approach to text categorization -- for unknown categories -- in the context of scientific literature, using Natural Language Processing techniques. The study leverages the power of pre-trained language models, specifically SciBERT, to extract meaningful representations of abstracts from the ArXiv dataset. Text categorization is performed using the K-Means algorithm, and the optimal number of clusters is determined based on the Silhouette score. The results demonstrate that the proposed approach captures subject information more effectively than the traditional arXiv labeling system, leading to improved text categorization. The approach offers potential for better navigation and recommendation systems in the rapidly growing landscape of scientific research literature.
* Workshop on Human-in-the-Loop Applied Machine Learning (HITLAML), 2023
Interpretable Dysarthric Speaker Adaptation based on Optimal-Transport
Mar 14, 2022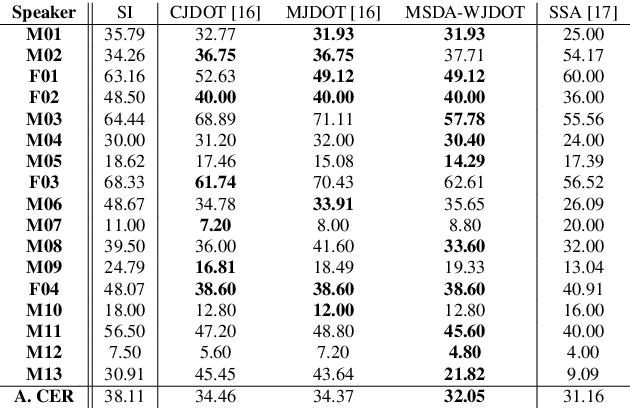
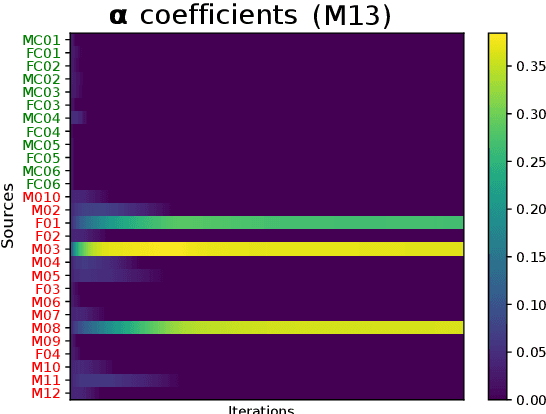
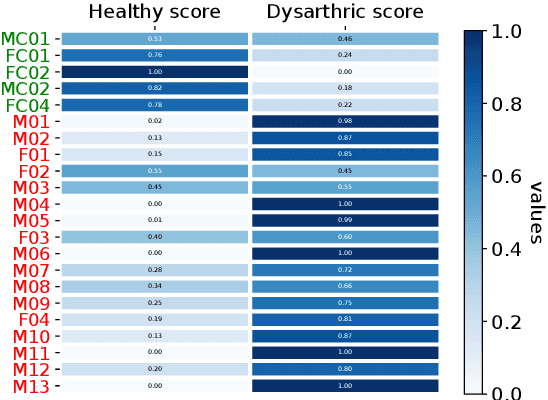
This work addresses the mismatch problem between the distribution of training data (source) and testing data (target), in the challenging context of dysarthric speech recognition. We focus on Speaker Adaptation (SA) in command speech recognition, where data from multiple sources (i.e., multiple speakers) are available. Specifically, we propose an unsupervised Multi-Source Domain Adaptation (MSDA) algorithm based on optimal-transport, called MSDA via Weighted Joint Optimal Transport (MSDA-WJDOT). We achieve a Command Error Rate relative reduction of 16% and 7% over the speaker-independent model and the best competitor method, respectively. The strength of the proposed approach is that, differently from any other existing SA method, it offers an interpretable model that can also be exploited, in this context, to diagnose dysarthria without any specific training. Indeed, it provides a closeness measure between the target and the source speakers, reflecting their similarity in terms of speech characteristics. Based on the similarity between the target speaker and the healthy/dysarthric source speakers, we then define the healthy/dysarthric score of the target speaker that we leverage to perform dysarthria detection. This approach does not require any additional training and achieves a 95% accuracy in the dysarthria diagnosis.
EasyCall corpus: a dysarthric speech dataset
Apr 06, 2021

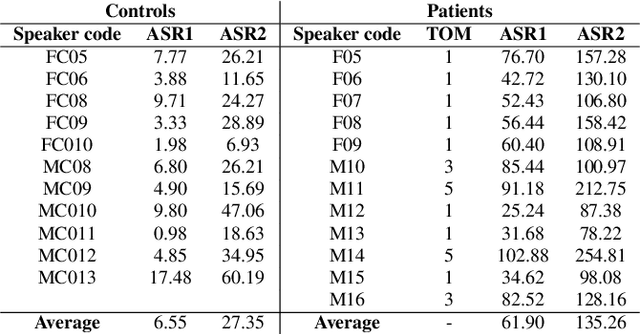
This paper introduces a new dysarthric speech command dataset in Italian, called EasyCall corpus. The dataset consists of 21386 audio recordings from 24 healthy and 31 dysarthric speakers, whose individual degree of speech impairment was assessed by neurologists through the Therapy Outcome Measure. The corpus aims at providing a resource for the development of ASR-based assistive technologies for patients with dysarthria. In particular, it may be exploited to develop a voice-controlled contact application for commercial smartphones, aiming at improving dysarthric patients' ability to communicate with their family and caregivers. Before recording the dataset, participants were administered a survey to evaluate which commands are more likely to be employed by dysarthric individuals in a voice-controlled contact application. In addition, the dataset includes a list of non-commands (i.e., words near/inside commands or phonetically close to commands) that can be leveraged to build a more robust command recognition system. At present commercial ASR systems perform poorly on the EasyCall Corpus as we report in this paper. This result corroborates the need for dysarthric speech corpora for developing effective assistive technologies. To the best of our knowledge, this database represents the richest corpus of dysarthric speech to date.
Optimal Transport-based Adaptation in Dysarthric Speech Tasks
Apr 06, 2021
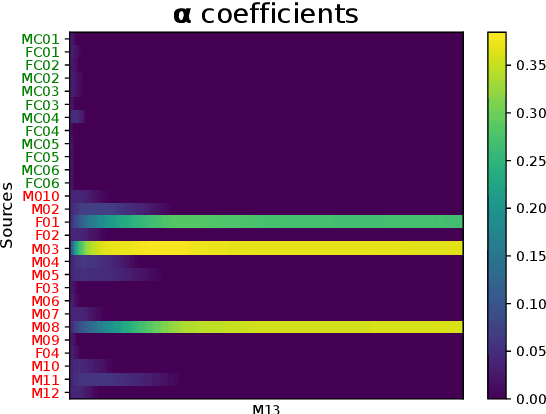
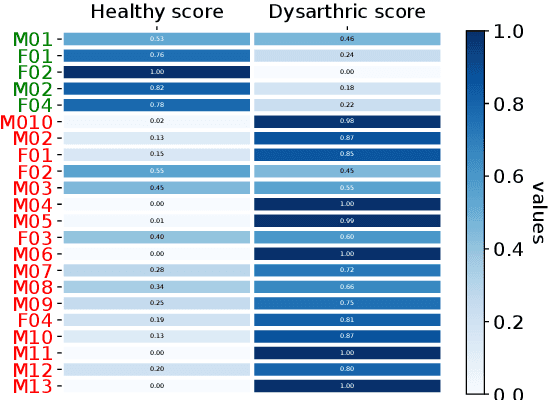
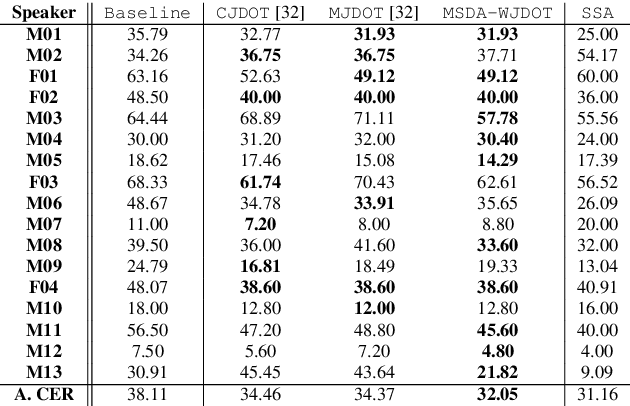
In many real-world applications, the mismatch between distributions of training data (source) and test data (target) significantly degrades the performance of machine learning algorithms. In speech data, causes of this mismatch include different acoustic environments or speaker characteristics. In this paper, we address this issue in the challenging context of dysarthric speech, by multi-source domain/speaker adaptation (MSDA/MSSA). Specifically, we propose the use of an optimal-transport based approach, called MSDA via Weighted Joint Optimal Transport (MSDA-WDJOT). We confront the mismatch problem in dysarthria detection for which the proposed approach outperforms both the Baseline and the state-of-the-art MSDA models, improving the detection accuracy of 0.9% over the best competitor method. We then employ MSDA-WJDOT for dysarthric speaker adaptation in command speech recognition. This provides a Command Error Rate relative reduction of 16% and 7% over the baseline and the best competitor model, respectively. Interestingly, MSDA-WJDOT provides a similarity score between the source and the target, i.e. between speakers in this case. We leverage this similarity measure to define a Dysarthric and Healthy score of the target speaker and diagnose the dysarthria with an accuracy of 95%.
Multi-source Domain Adaptation via Weighted Joint Distributions Optimal Transport
Jun 23, 2020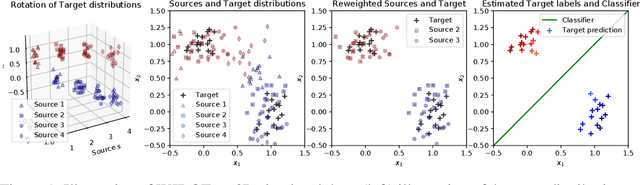
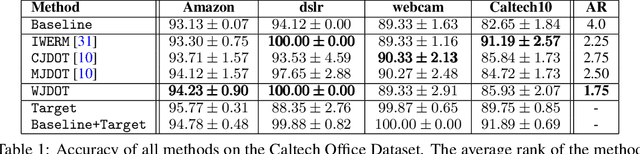
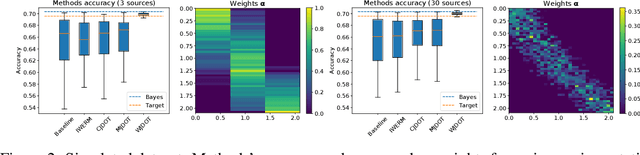
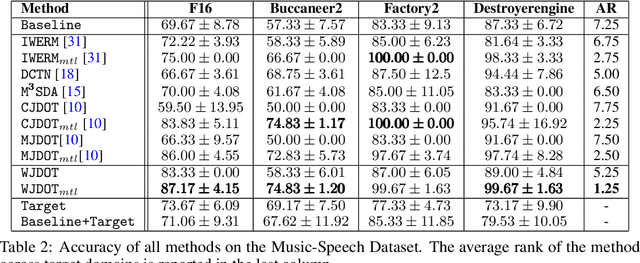
The problem of domain adaptation on an unlabeled target dataset using knowledge from multiple labelled source datasets is becoming increasingly important. A key challenge is to design an approach that overcomes the covariate and target shift both among the sources, and between the source and target domains. In this paper, we address this problem from a new perspective: instead of looking for a latent representation invariant between source and target domains, we exploit the diversity of source distributions by tuning their weights to the target task at hand. Our method, named Weighted Joint Distribution Optimal Transport (WJDOT), aims at finding simultaneously an Optimal Transport-based alignment between the source and target distributions and a re-weighting of the sources distributions. We discuss the theoretical aspects of the method and propose a conceptually simple algorithm. Numerical experiments indicate that the proposed method achieves state-of-the-art performance on simulated and real-life datasets.
Improving generalization of vocal tract feature reconstruction: from augmented acoustic inversion to articulatory feature reconstruction without articulatory data
Sep 04, 2018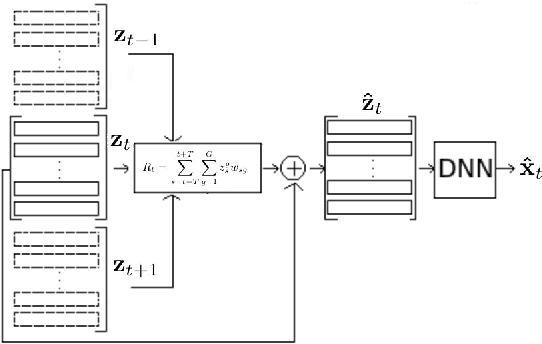
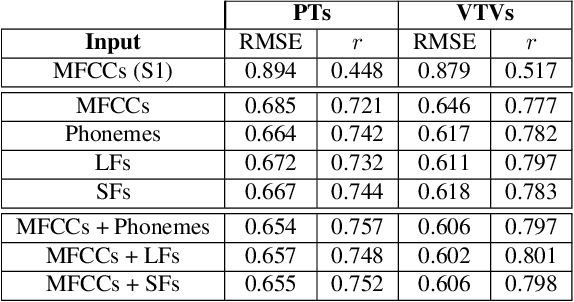
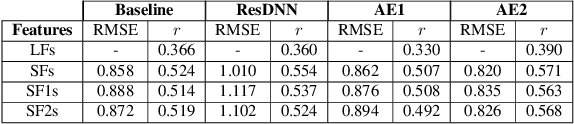
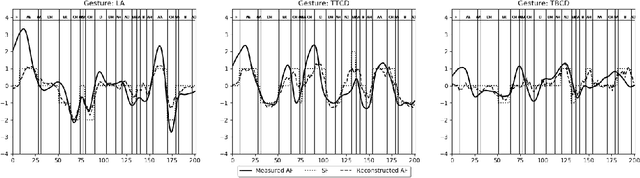
We address the problem of reconstructing articulatory movements, given audio and/or phonetic labels. The scarce availability of multi-speaker articulatory data makes it difficult to learn a reconstruction that generalizes to new speakers and across datasets. We first consider the XRMB dataset where audio, articulatory measurements and phonetic transcriptions are available. We show that phonetic labels, used as input to deep recurrent neural networks that reconstruct articulatory features, are in general more helpful than acoustic features in both matched and mismatched training-testing conditions. In a second experiment, we test a novel approach that attempts to build articulatory features from prior articulatory information extracted from phonetic labels. Such approach recovers vocal tract movements directly from an acoustic-only dataset without using any articulatory measurement. Results show that articulatory features generated by this approach can correlate up to 0.59 Pearson product-moment correlation with measured articulatory features.