 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning to navigate turbulence without a map
Apr 26, 2024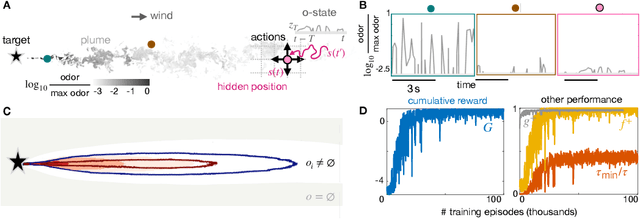


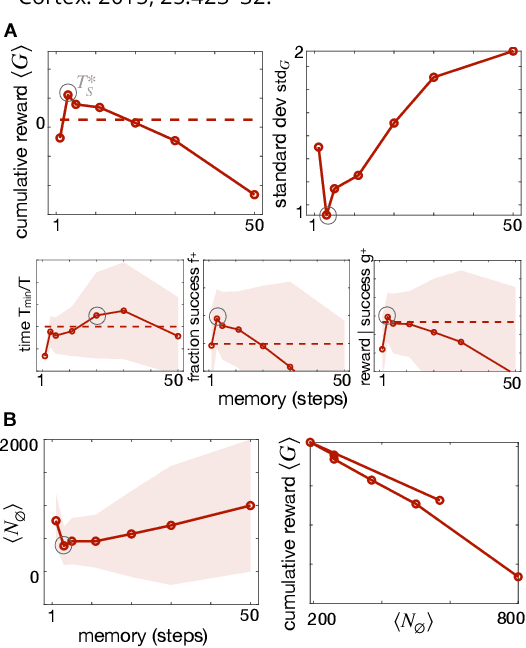
We consider the problem of olfactory searches in a turbulent environment. We focus on agents that respond solely to odor stimuli, with no access to spatial perception nor prior information about the odor location. We ask whether navigation strategies to a target can be learned robustly within a sequential decision making framework. We develop a reinforcement learning algorithm using a small set of interpretable olfactory states and train it with realistic turbulent odor cues. By introducing a temporal memory, we demonstrate that two salient features of odor traces, discretized in few olfactory states, are sufficient to learn navigation in a realistic odor plume. Performance is dictated by the sparse nature of turbulent plumes. An optimal memory exists which ignores blanks within the plume and activates a recovery strategy outside the plume. We obtain the best performance by letting agents learn their recovery strategy and show that it is mostly casting cross wind, similar to behavior observed in flying insects. The optimal strategy is robust to substantial changes in the odor plumes, suggesting minor parameter tuning may be sufficient to adapt to different environments.
The effect of data augmentation and 3D-CNN depth on Alzheimer's Disease detection
Sep 13, 2023
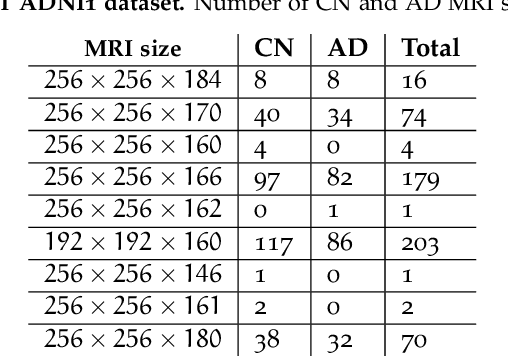
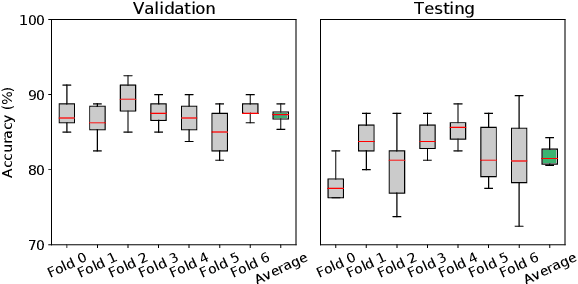
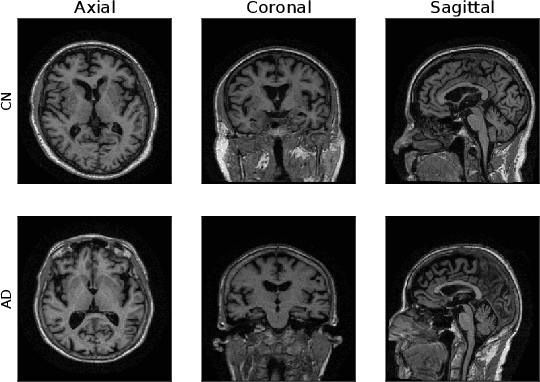
Machine Learning (ML) has emerged as a promising approach in healthcare, outperforming traditional statistical techniques. However, to establish ML as a reliable tool in clinical practice, adherence to best practices regarding data handling, experimental design, and model evaluation is crucial. This work summarizes and strictly observes such practices to ensure reproducible and reliable ML. Specifically, we focus on Alzheimer's Disease (AD) detection, which serves as a paradigmatic example of challenging problem in healthcare. We investigate the impact of different data augmentation techniques and model complexity on the overall performance. We consider MRI data from ADNI dataset to address a classification problem employing 3D Convolutional Neural Network (CNN). The experiments are designed to compensate for data scarcity and initial random parameters by utilizing cross-validation and multiple training trials. Within this framework, we train 15 predictive models, considering three different data augmentation strategies and five distinct 3D CNN architectures, each varying in the number of convolutional layers. Specifically, the augmentation strategies are based on affine transformations, such as zoom, shift, and rotation, applied concurrently or separately. The combined effect of data augmentation and model complexity leads to a variation in prediction performance up to 10% of accuracy. When affine transformation are applied separately, the model is more accurate, independently from the adopted architecture. For all strategies, the model accuracy followed a concave behavior at increasing number of convolutional layers, peaking at an intermediate value of layers. The best model (8 CL, (B)) is the most stable across cross-validation folds and training trials, reaching excellent performance both on the testing set and on an external test set.
Physics Informed Shallow Machine Learning for Wind Speed Prediction
Apr 01, 2022
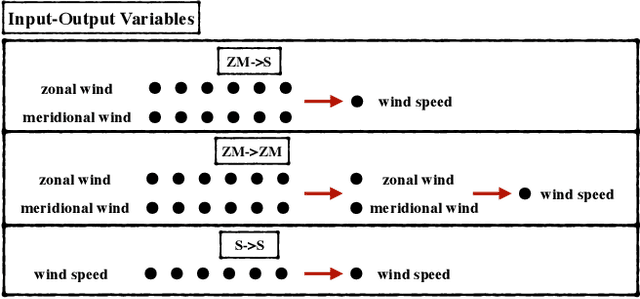
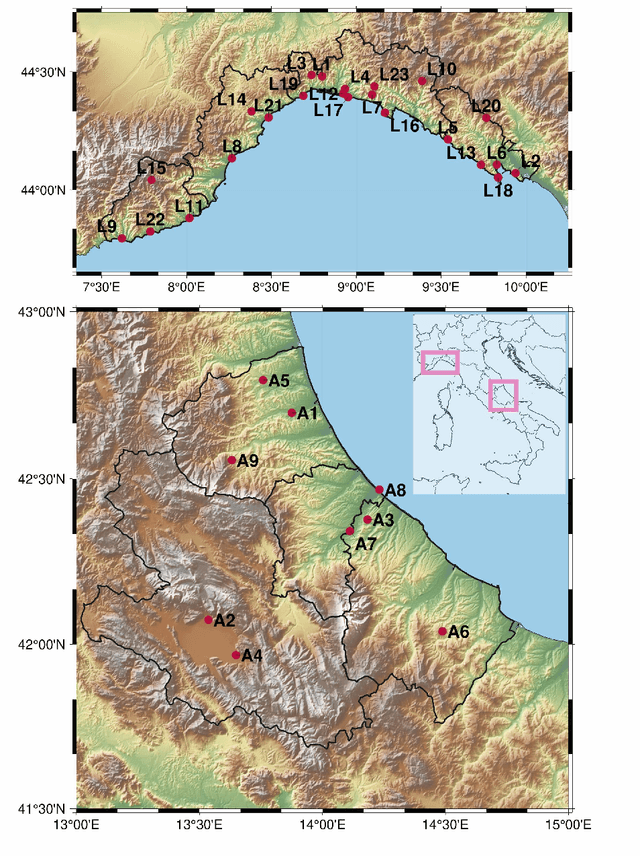
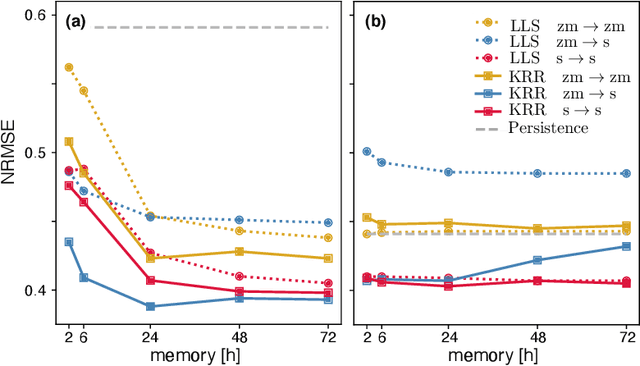
The ability to predict wind is crucial for both energy production and weather forecasting. Mechanistic models that form the basis of traditional forecasting perform poorly near the ground. In this paper, we take an alternative data-driven approach based on supervised learning. We analyze a massive dataset of wind measured from anemometers located at 10 m height in 32 locations in two central and north west regions of Italy (Abruzzo and Liguria). We train supervised learning algorithms using the past history of wind to predict its value at a future time (horizon). Using data from a single location and time horizon we compare systematically several algorithms where we vary the input/output variables, the memory of the input and the linear vs non-linear learning model. We then compare performance of the best algorithms across all locations and forecasting horizons. We find that the optimal design as well as its performance vary with the location. We demonstrate that the presence of a reproducible diurnal cycle provides a rationale to understand this variation. We conclude with a systematic comparison with state of the art algorithms and show that, when the model is accurately designed, shallow algorithms are competitive with more complex deep architectures.
Latent Variable Time-varying Network Inference
Aug 02, 2018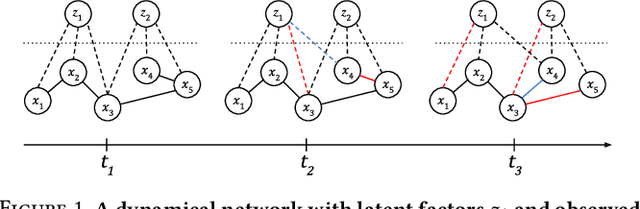
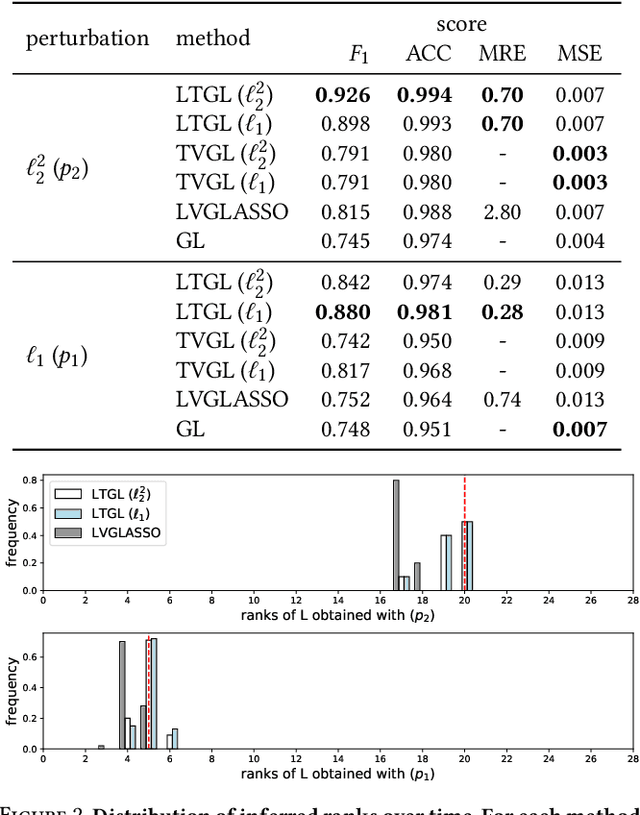

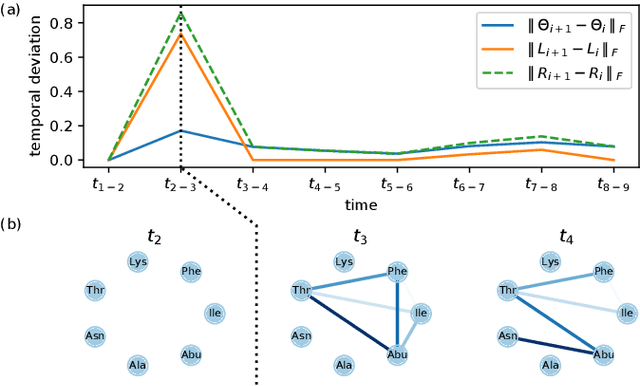
In many applications of finance, biology and sociology, complex systems involve entities interacting with each other. These processes have the peculiarity of evolving over time and of comprising latent factors, which influence the system without being explicitly measured. In this work we present latent variable time-varying graphical lasso (LTGL), a method for multivariate time-series graphical modelling that considers the influence of hidden or unmeasurable factors. The estimation of the contribution of the latent factors is embedded in the model which produces both sparse and low-rank components for each time point. In particular, the first component represents the connectivity structure of observable variables of the system, while the second represents the influence of hidden factors, assumed to be few with respect to the observed variables. Our model includes temporal consistency on both components, providing an accurate evolutionary pattern of the system. We derive a tractable optimisation algorithm based on alternating direction method of multipliers, and develop a scalable and efficient implementation which exploits proximity operators in closed form. LTGL is extensively validated on synthetic data, achieving optimal performance in terms of accuracy, structure learning and scalability with respect to ground truth and state-of-the-art methods for graphical inference. We conclude with the application of LTGL to real case studies, from biology and finance, to illustrate how our method can be successfully employed to gain insights on multivariate time-series data.
* 9 pages, 5 figures, 1 table
A temporal model for multiple sclerosis course evolution
Dec 02, 2016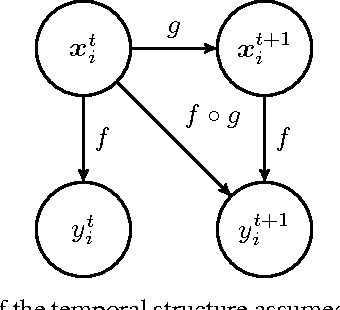

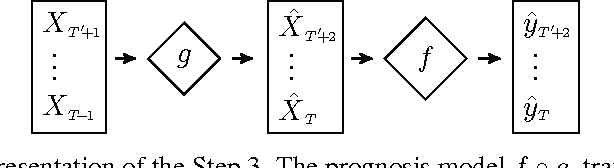
Multiple Sclerosis is a degenerative condition of the central nervous system that affects nearly 2.5 million of individuals in terms of their physical, cognitive, psychological and social capabilities. Researchers are currently investigating on the use of patient reported outcome measures for the assessment of impact and evolution of the disease on the life of the patients. To date, a clear understanding on the use of such measures to predict the evolution of the disease is still lacking. In this work we resort to regularized machine learning methods for binary classification and multiple output regression. We propose a pipeline that can be used to predict the disease progression from patient reported measures. The obtained model is tested on a data set collected from an ongoing clinical research project.
Real-time Automatic Emotion Recognition from Body Gestures
Feb 20, 2014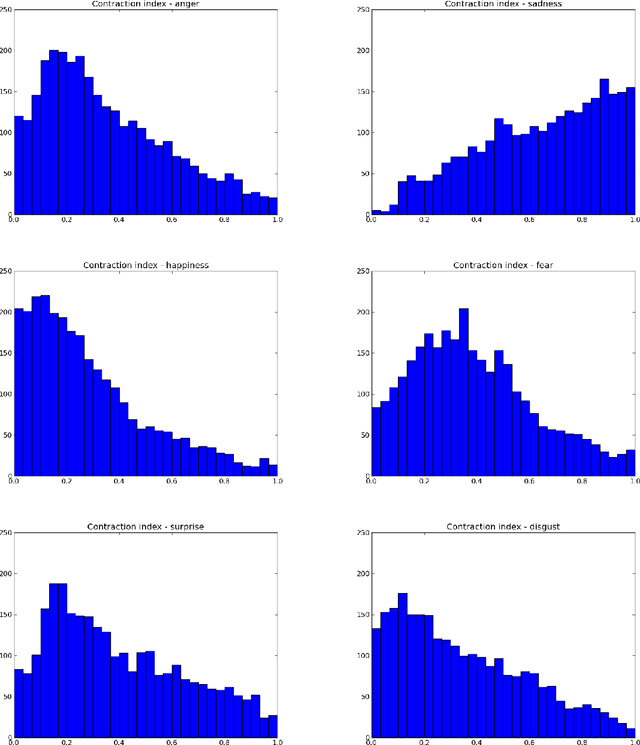
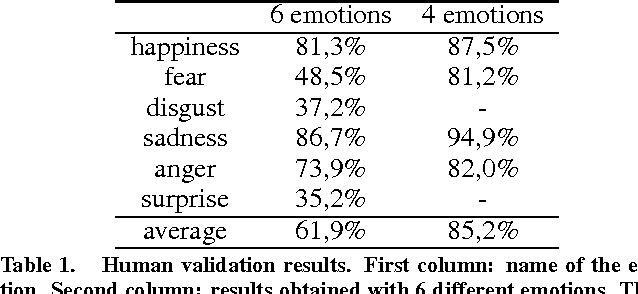

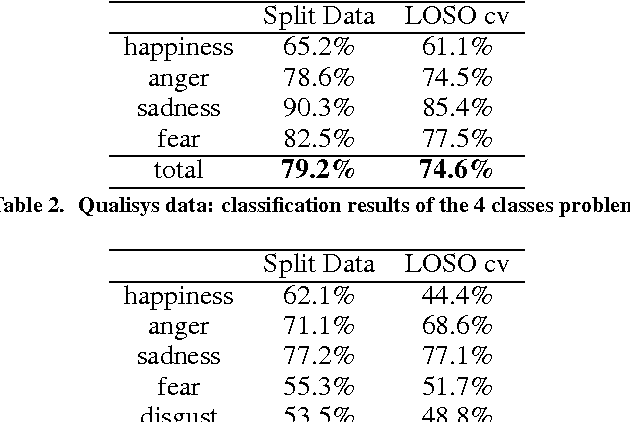
Although psychological research indicates that bodily expressions convey important affective information, to date research in emotion recognition focused mainly on facial expression or voice analysis. In this paper we propose an approach to realtime automatic emotion recognition from body movements. A set of postural, kinematic, and geometrical features are extracted from sequences 3D skeletons and fed to a multi-class SVM classifier. The proposed method has been assessed on data acquired through two different systems: a professionalgrade optical motion capture system, and Microsoft Kinect. The system has been assessed on a "six emotions" recognition problem, and using a leave-one-subject-out cross validation strategy, reached an overall recognition rate of 61.3% which is very close to the recognition rate of 61.9% obtained by human observers. To provide further testing of the system, two games were developed, where one or two users have to interact to understand and express emotions with their body.
Proximal methods for the latent group lasso penalty
Sep 03, 2012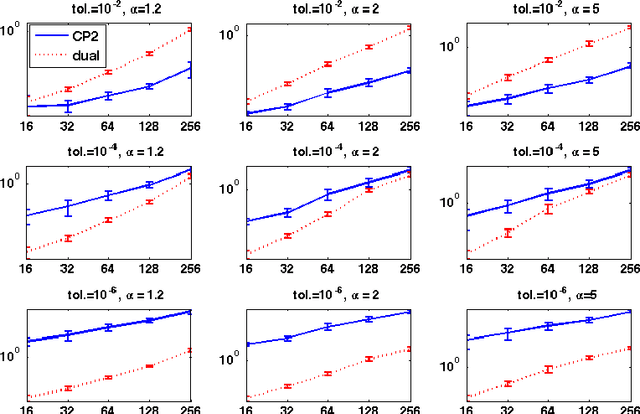
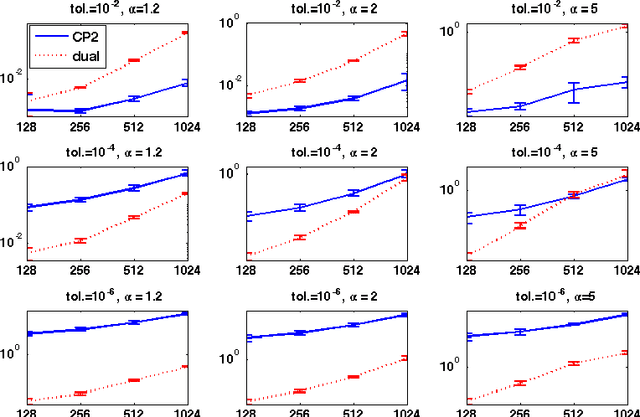
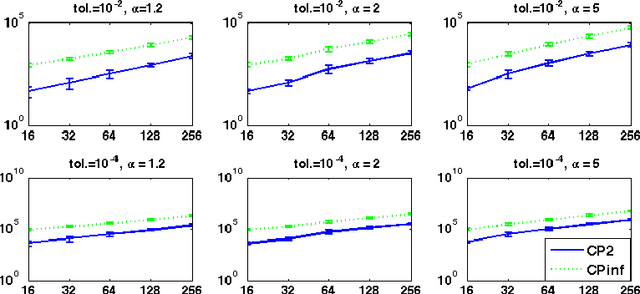
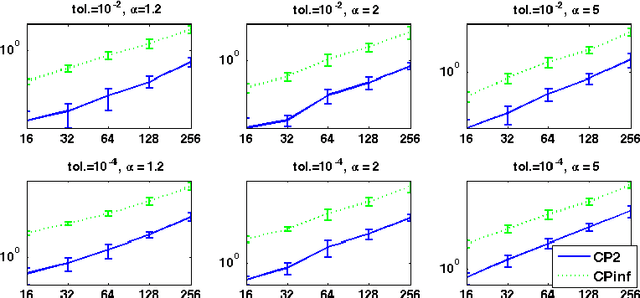
We consider a regularized least squares problem, with regularization by structured sparsity-inducing norms, which extend the usual $\ell_1$ and the group lasso penalty, by allowing the subsets to overlap. Such regularizations lead to nonsmooth problems that are difficult to optimize, and we propose in this paper a suitable version of an accelerated proximal method to solve them. We prove convergence of a nested procedure, obtained composing an accelerated proximal method with an inner algorithm for computing the proximity operator. By exploiting the geometrical properties of the penalty, we devise a new active set strategy, thanks to which the inner iteration is relatively fast, thus guaranteeing good computational performances of the overall algorithm. Our approach allows to deal with high dimensional problems without pre-processing for dimensionality reduction, leading to better computational and prediction performances with respect to the state-of-the art methods, as shown empirically both on toy and real data.
PADDLE: Proximal Algorithm for Dual Dictionaries LEarning
Nov 16, 2010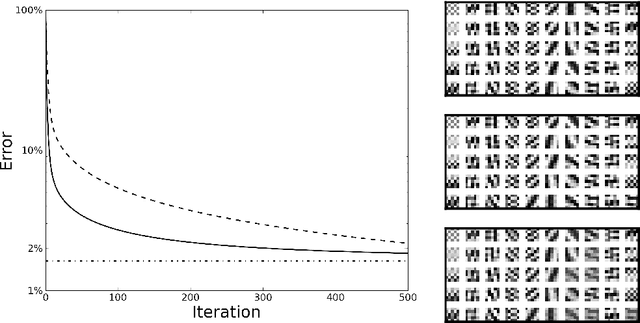


Recently, considerable research efforts have been devoted to the design of methods to learn from data overcomplete dictionaries for sparse coding. However, learned dictionaries require the solution of an optimization problem for coding new data. In order to overcome this drawback, we propose an algorithm aimed at learning both a dictionary and its dual: a linear mapping directly performing the coding. By leveraging on proximal methods, our algorithm jointly minimizes the reconstruction error of the dictionary and the coding error of its dual; the sparsity of the representation is induced by an $\ell_1$-based penalty on its coefficients. The results obtained on synthetic data and real images show that the algorithm is capable of recovering the expected dictionaries. Furthermore, on a benchmark dataset, we show that the image features obtained from the dual matrix yield state-of-the-art classification performance while being much less computational intensive.