 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCartan Networks: Group theoretical Hyperbolic Deep Learning
May 30, 2025Hyperbolic deep learning leverages the metric properties of hyperbolic spaces to develop efficient and informative embeddings of hierarchical data. Here, we focus on the solvable group structure of hyperbolic spaces, which follows naturally from their construction as symmetric spaces. This dual nature of Lie group and Riemannian manifold allows us to propose a new class of hyperbolic deep learning algorithms where group homomorphisms are interleaved with metric-preserving diffeomorphisms. The resulting algorithms, which we call Cartan networks, show promising results on various benchmark data sets and open the way to a novel class of hyperbolic deep learning architectures.
iCub World: Friendly Robots Help Building Good Vision Data-Sets
Jun 15, 2013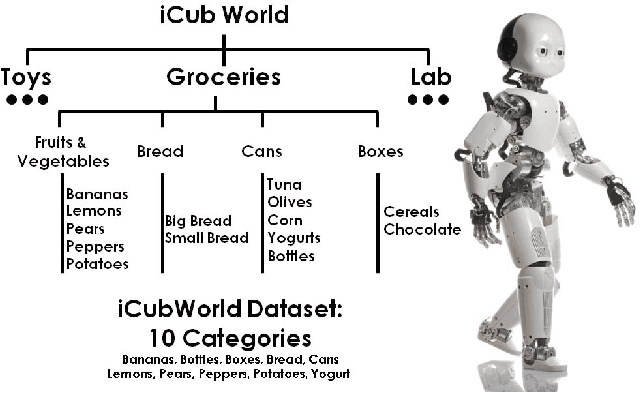
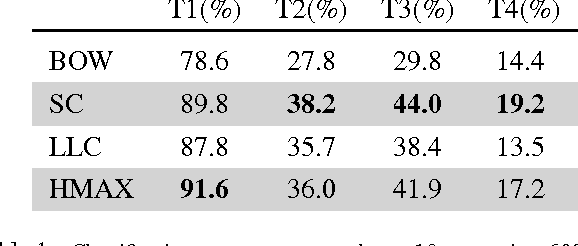

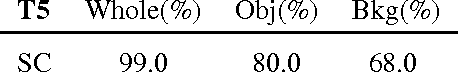
In this paper we present and start analyzing the iCub World data-set, an object recognition data-set, we acquired using a Human-Robot Interaction (HRI) scheme and the iCub humanoid robot platform. Our set up allows for rapid acquisition and annotation of data with corresponding ground truth. While more constrained in its scopes -- the iCub world is essentially a robotics research lab -- we demonstrate how the proposed data-set poses challenges to current recognition systems. The iCubWorld data-set is publicly available. The data-set can be downloaded from: http://www.iit.it/en/projects/data-sets.html.
GURLS: a Least Squares Library for Supervised Learning
Mar 05, 2013


We present GURLS, a least squares, modular, easy-to-extend software library for efficient supervised learning. GURLS is targeted to machine learning practitioners, as well as non-specialists. It offers a number state-of-the-art training strategies for medium and large-scale learning, and routines for efficient model selection. The library is particularly well suited for multi-output problems (multi-category/multi-label). GURLS is currently available in two independent implementations: Matlab and C++. It takes advantage of the favorable properties of regularized least squares algorithm to exploit advanced tools in linear algebra. Routines to handle computations with very large matrices by means of memory-mapped storage and distributed task execution are available. The package is distributed under the BSD licence and is available for download at https://github.com/CBCL/GURLS.
Nonparametric sparsity and regularization
Aug 13, 2012



In this work we are interested in the problems of supervised learning and variable selection when the input-output dependence is described by a nonlinear function depending on a few variables. Our goal is to consider a sparse nonparametric model, hence avoiding linear or additive models. The key idea is to measure the importance of each variable in the model by making use of partial derivatives. Based on this intuition we propose a new notion of nonparametric sparsity and a corresponding least squares regularization scheme. Using concepts and results from the theory of reproducing kernel Hilbert spaces and proximal methods, we show that the proposed learning algorithm corresponds to a minimization problem which can be provably solved by an iterative procedure. The consistency properties of the obtained estimator are studied both in terms of prediction and selection performance. An extensive empirical analysis shows that the proposed method performs favorably with respect to the state-of-the-art methods.
PADDLE: Proximal Algorithm for Dual Dictionaries LEarning
Nov 16, 2010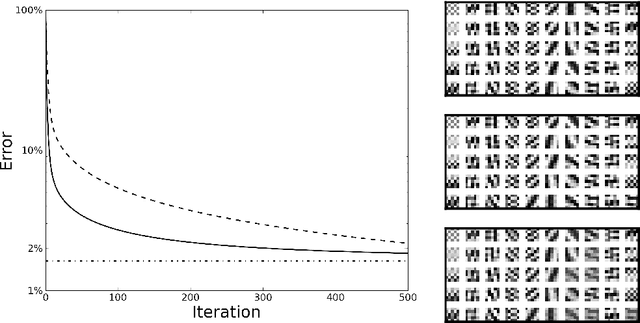


Recently, considerable research efforts have been devoted to the design of methods to learn from data overcomplete dictionaries for sparse coding. However, learned dictionaries require the solution of an optimization problem for coding new data. In order to overcome this drawback, we propose an algorithm aimed at learning both a dictionary and its dual: a linear mapping directly performing the coding. By leveraging on proximal methods, our algorithm jointly minimizes the reconstruction error of the dictionary and the coding error of its dual; the sparsity of the representation is induced by an $\ell_1$-based penalty on its coefficients. The results obtained on synthetic data and real images show that the algorithm is capable of recovering the expected dictionaries. Furthermore, on a benchmark dataset, we show that the image features obtained from the dual matrix yield state-of-the-art classification performance while being much less computational intensive.