 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparities in LLM Reasoning Accuracy and Explanations: A Case Study on African American English
Mar 06, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning tasks, leading to their widespread deployment. However, recent studies have highlighted concerning biases in these models, particularly in their handling of dialectal variations like African American English (AAE). In this work, we systematically investigate dialectal disparities in LLM reasoning tasks. We develop an experimental framework comparing LLM performance given Standard American English (SAE) and AAE prompts, combining LLM-based dialect conversion with established linguistic analyses. We find that LLMs consistently produce less accurate responses and simpler reasoning chains and explanations for AAE inputs compared to equivalent SAE questions, with disparities most pronounced in social science and humanities domains. These findings highlight systematic differences in how LLMs process and reason about different language varieties, raising important questions about the development and deployment of these systems in our multilingual and multidialectal world. Our code repository is publicly available at https://github.com/Runtaozhou/dialect_bias_eval.
SegPrompt: Using Segmentation Map as a Better Prompt to Finetune Deep Models for Kidney Stone Classification
Mar 15, 2023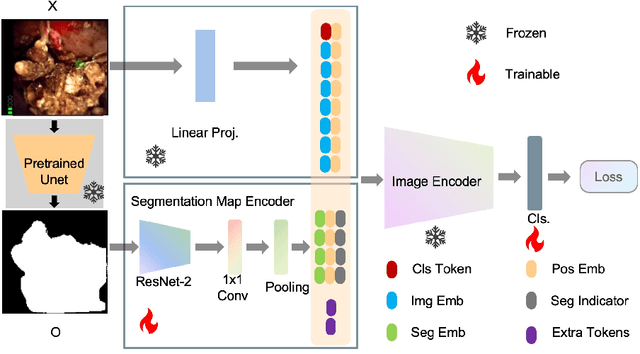
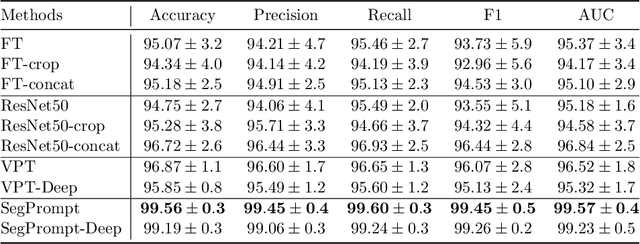
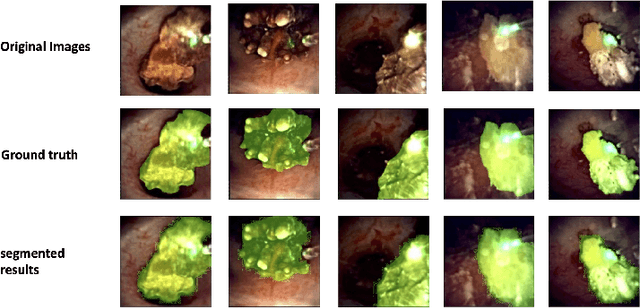
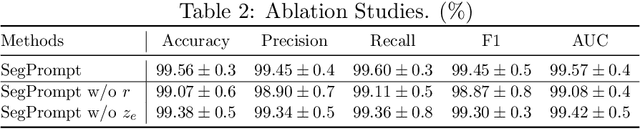
Recently, deep learning has produced encouraging results for kidney stone classification using endoscope images. However, the shortage of annotated training data poses a severe problem in improving the performance and generalization ability of the trained model. It is thus crucial to fully exploit the limited data at hand. In this paper, we propose SegPrompt to alleviate the data shortage problems by exploiting segmentation maps from two aspects. First, SegPrompt integrates segmentation maps to facilitate classification training so that the classification model is aware of the regions of interest. The proposed method allows the image and segmentation tokens to interact with each other to fully utilize the segmentation map information. Second, we use the segmentation maps as prompts to tune the pretrained deep model, resulting in much fewer trainable parameters than vanilla finetuning. We perform extensive experiments on the collected kidney stone dataset. The results show that SegPrompt can achieve an advantageous balance between the model fitting ability and the generalization ability, eventually leading to an effective model with limited training data.