 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Spatial Reasoning in MLLMs through Programmatic Data Synthesis
Dec 18, 2025
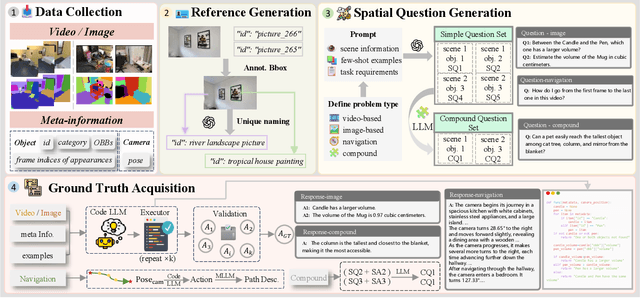

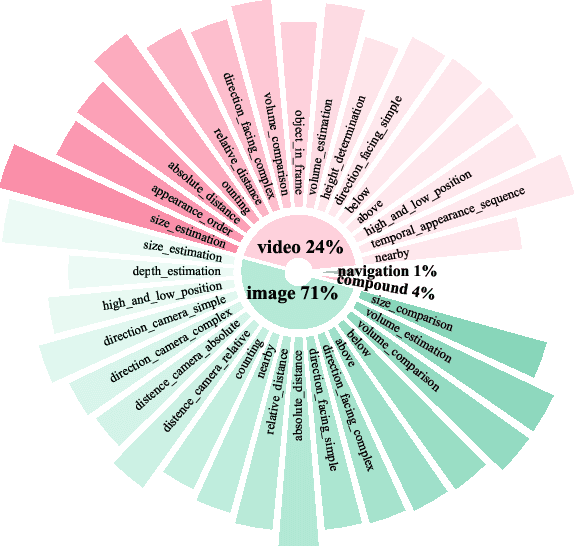
Embodied intelligence, a grand challenge in artificial intelligence, is fundamentally constrained by the limited spatial understanding and reasoning capabilities of current models. Prevailing efforts to address this through enhancing Vision-Language Models (VLMs) are trapped in a dilemma: template-based datasets are scalable but structurally rigid, while manual annotation is linguistically diverse but unscalable and, critically, computationally imprecise. We introduce SPRITE, a novel framework that overcomes this dilemma by leveraging simulators and large models to programmatically synthesize scalable, diverse, and high-quality spatial reasoning data. The core innovation of SPRITE is to reframe ground-truth generation as a code-generation task. We utilize LLMs to compile complex spatial questions into executable programs, which are then verified against high-precision scene meta-information extracted from simulators. This ensures our ground truth is both computationally precise and verifiable, while the generative power of LLMs provides vast linguistic diversity. Leveraging this pipeline, we have curated a dataset encompassing 3 simulators, 11k+ scenes, and 300k+ image/video instruction-tuning pairs. We demonstrate that a VLM trained on our data achieves significant performance gains on multiple spatial benchmarks and outperforms other open-source datasets of equivalent size. Furthermore, a scalability analysis confirms our hypothesis that overcoming the low-diversity nature of traditional template methods is essential for building robust, generalizable spatial intelligence. We will make the SPRITE framework code and the full 300k+ dataset publicly available to facilitate future research in spatial intelligence.
Uncertainty Guided Refinement for Fine-Grained Salient Object Detection
Apr 13, 2025



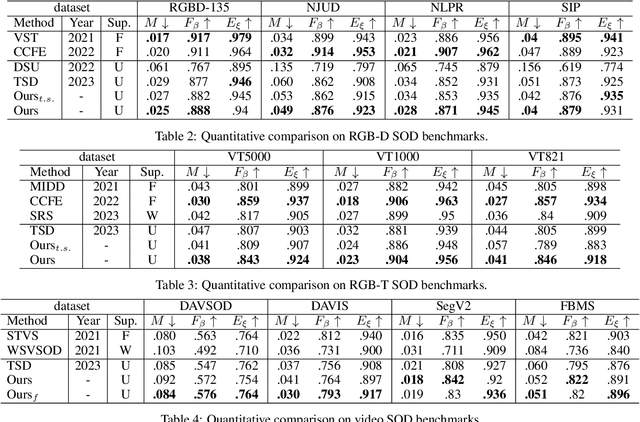
Recently, salient object detection (SOD) methods have achieved impressive performance. However, salient regions predicted by existing methods usually contain unsaturated regions and shadows, which limits the model for reliable fine-grained predictions. To address this, we introduce the uncertainty guidance learning approach to SOD, intended to enhance the model's perception of uncertain regions. Specifically, we design a novel Uncertainty Guided Refinement Attention Network (UGRAN), which incorporates three important components, i.e., the Multilevel Interaction Attention (MIA) module, the Scale Spatial-Consistent Attention (SSCA) module, and the Uncertainty Refinement Attention (URA) module. Unlike conventional methods dedicated to enhancing features, the proposed MIA facilitates the interaction and perception of multilevel features, leveraging the complementary characteristics among multilevel features. Then, through the proposed SSCA, the salient information across diverse scales within the aggregated features can be integrated more comprehensively and integrally. In the subsequent steps, we utilize the uncertainty map generated from the saliency prediction map to enhance the model's perception capability of uncertain regions, generating a highly-saturated fine-grained saliency prediction map. Additionally, we devise an adaptive dynamic partition (ADP) mechanism to minimize the computational overhead of the URA module and improve the utilization of uncertainty guidance. Experiments on seven benchmark datasets demonstrate the superiority of the proposed UGRAN over the state-of-the-art methodologies. Codes will be released at https://github.com/I2-Multimedia-Lab/UGRAN.
Unified Unsupervised Salient Object Detection via Knowledge Transfer
Apr 23, 2024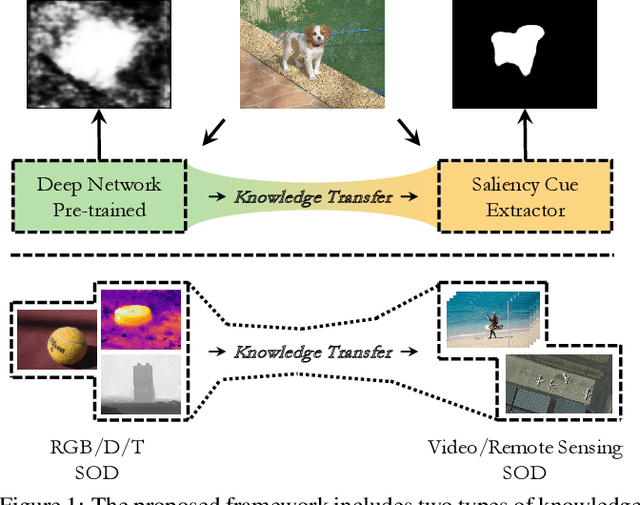
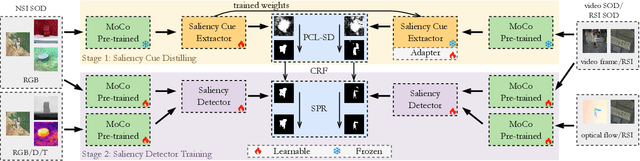
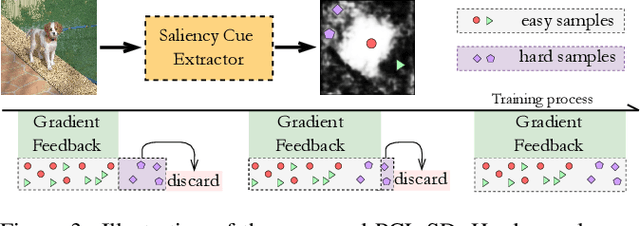
Recently, unsupervised salient object detection (USOD) has gained increasing attention due to its annotation-free nature. However, current methods mainly focus on specific tasks such as RGB and RGB-D, neglecting the potential for task migration. In this paper, we propose a unified USOD framework for generic USOD tasks. Firstly, we propose a Progressive Curriculum Learning-based Saliency Distilling (PCL-SD) mechanism to extract saliency cues from a pre-trained deep network. This mechanism starts with easy samples and progressively moves towards harder ones, to avoid initial interference caused by hard samples. Afterwards, the obtained saliency cues are utilized to train a saliency detector, and we employ a Self-rectify Pseudo-label Refinement (SPR) mechanism to improve the quality of pseudo-labels. Finally, an adapter-tuning method is devised to transfer the acquired saliency knowledge, leveraging shared knowledge to attain superior transferring performance on the target tasks. Extensive experiments on five representative SOD tasks confirm the effectiveness and feasibility of our proposed method. Code and supplement materials are available at https://github.com/I2-Multimedia-Lab/A2S-v3.
M$^3$Net: Multilevel, Mixed and Multistage Attention Network for Salient Object Detection
Sep 15, 2023Most existing salient object detection methods mostly use U-Net or feature pyramid structure, which simply aggregates feature maps of different scales, ignoring the uniqueness and interdependence of them and their respective contributions to the final prediction. To overcome these, we propose the M$^3$Net, i.e., the Multilevel, Mixed and Multistage attention network for Salient Object Detection (SOD). Firstly, we propose Multiscale Interaction Block which innovatively introduces the cross-attention approach to achieve the interaction between multilevel features, allowing high-level features to guide low-level feature learning and thus enhancing salient regions. Secondly, considering the fact that previous Transformer based SOD methods locate salient regions only using global self-attention while inevitably overlooking the details of complex objects, we propose the Mixed Attention Block. This block combines global self-attention and window self-attention, aiming at modeling context at both global and local levels to further improve the accuracy of the prediction map. Finally, we proposed a multilevel supervision strategy to optimize the aggregated feature stage-by-stage. Experiments on six challenging datasets demonstrate that the proposed M$^3$Net surpasses recent CNN and Transformer-based SOD arts in terms of four metrics. Codes are available at https://github.com/I2-Multimedia-Lab/M3Net.
SegPrompt: Using Segmentation Map as a Better Prompt to Finetune Deep Models for Kidney Stone Classification
Mar 15, 2023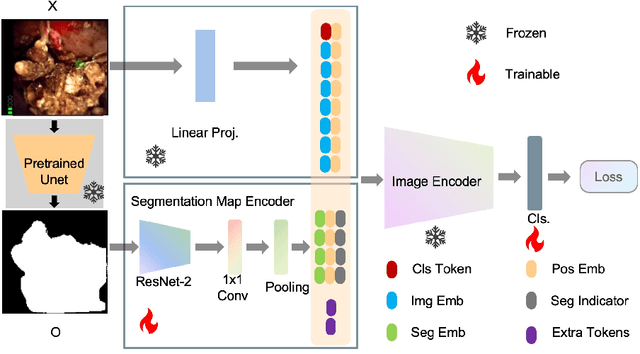
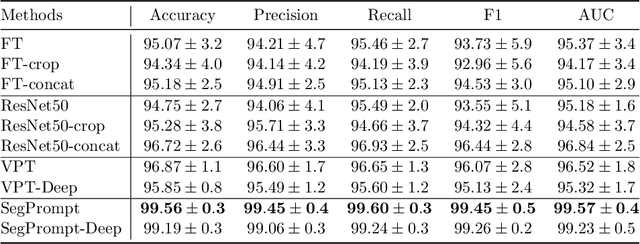
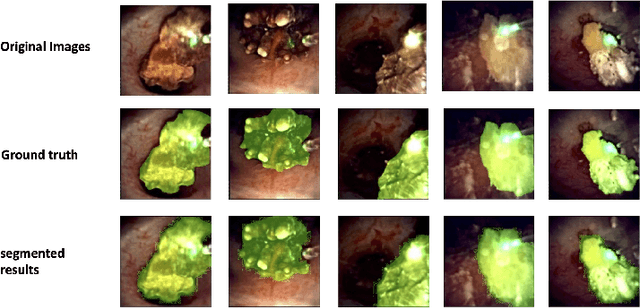
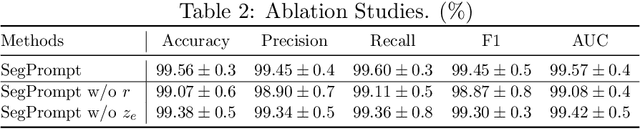
Recently, deep learning has produced encouraging results for kidney stone classification using endoscope images. However, the shortage of annotated training data poses a severe problem in improving the performance and generalization ability of the trained model. It is thus crucial to fully exploit the limited data at hand. In this paper, we propose SegPrompt to alleviate the data shortage problems by exploiting segmentation maps from two aspects. First, SegPrompt integrates segmentation maps to facilitate classification training so that the classification model is aware of the regions of interest. The proposed method allows the image and segmentation tokens to interact with each other to fully utilize the segmentation map information. Second, we use the segmentation maps as prompts to tune the pretrained deep model, resulting in much fewer trainable parameters than vanilla finetuning. We perform extensive experiments on the collected kidney stone dataset. The results show that SegPrompt can achieve an advantageous balance between the model fitting ability and the generalization ability, eventually leading to an effective model with limited training data.