 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Rule Discovery Through Bilevel Optimization of Split-Rules of Nonlinear Decision Trees for Classification Problems
Paper and Code
Aug 02, 2020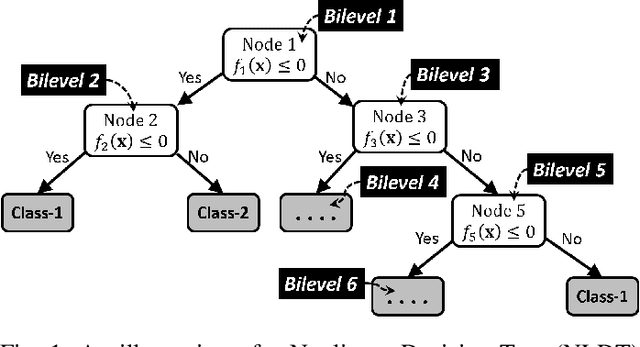
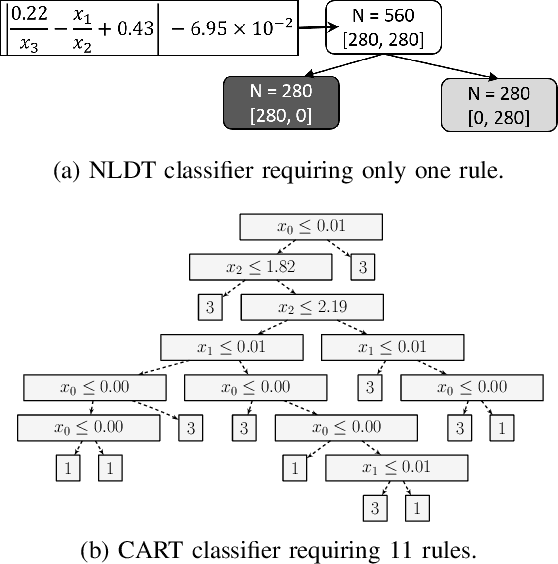
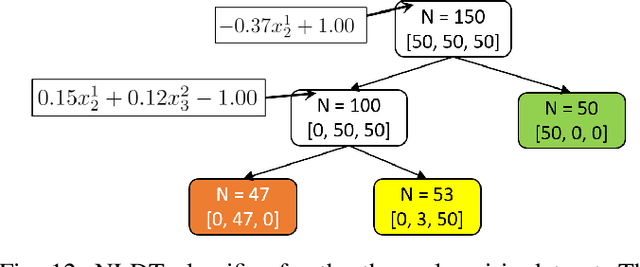

For supervised classification problems involving design, control, other practical purposes, users are not only interested in finding a highly accurate classifier, but they also demand that the obtained classifier be easily interpretable. While the definition of interpretability of a classifier can vary from case to case, here, by a humanly interpretable classifier we restrict it to be expressed in simplistic mathematical terms. As a novel approach, we represent a classifier as an assembly of simple mathematical rules using a non-linear decision tree (NLDT). Each conditional (non-terminal) node of the tree represents a non-linear mathematical rule (split-rule) involving features in order to partition the dataset in the given conditional node into two non-overlapping subsets. This partitioning is intended to minimize the impurity of the resulting child nodes. By restricting the structure of split-rule at each conditional node and depth of the decision tree, the interpretability of the classifier is assured. The non-linear split-rule at a given conditional node is obtained using an evolutionary bilevel optimization algorithm, in which while the upper-level focuses on arriving at an interpretable structure of the split-rule, the lower-level achieves the most appropriate weights (coefficients) of individual constituents of the rule to minimize the net impurity of two resulting child nodes. The performance of the proposed algorithm is demonstrated on a number of controlled test problems, existing benchmark problems, and industrial problems. Results on two to 500-feature problems are encouraging and open up further scopes of applying the proposed approach to more challenging and complex classification tasks.