 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyJuice Makes It Real: Black-Box, Universal Red Teaming for Synthetic Image Detectors
Sep 19, 2025Synthetic image detectors (SIDs) are a key defense against the risks posed by the growing realism of images from text-to-image (T2I) models. Red teaming improves SID's effectiveness by identifying and exploiting their failure modes via misclassified synthetic images. However, existing red-teaming solutions (i) require white-box access to SIDs, which is infeasible for proprietary state-of-the-art detectors, and (ii) generate image-specific attacks through expensive online optimization. To address these limitations, we propose PolyJuice, the first black-box, image-agnostic red-teaming method for SIDs, based on an observed distribution shift in the T2I latent space between samples correctly and incorrectly classified by the SID. PolyJuice generates attacks by (i) identifying the direction of this shift through a lightweight offline process that only requires black-box access to the SID, and (ii) exploiting this direction by universally steering all generated images towards the SID's failure modes. PolyJuice-steered T2I models are significantly more effective at deceiving SIDs (up to 84%) compared to their unsteered counterparts. We also show that the steering directions can be estimated efficiently at lower resolutions and transferred to higher resolutions using simple interpolation, reducing computational overhead. Finally, tuning SID models on PolyJuice-augmented datasets notably enhances the performance of the detectors (up to 30%).
DiverseFlow: Sample-Efficient Diverse Mode Coverage in Flows
Apr 10, 2025Many real-world applications of flow-based generative models desire a diverse set of samples that cover multiple modes of the target distribution. However, the predominant approach for obtaining diverse sets is not sample-efficient, as it involves independently obtaining many samples from the source distribution and mapping them through the flow until the desired mode coverage is achieved. As an alternative to repeated sampling, we introduce DiverseFlow: a training-free approach to improve the diversity of flow models. Our key idea is to employ a determinantal point process to induce a coupling between the samples that drives diversity under a fixed sampling budget. In essence, DiverseFlow allows exploration of more variations in a learned flow model with fewer samples. We demonstrate the efficacy of our method for tasks where sample-efficient diversity is desirable, such as text-guided image generation with polysemous words, inverse problems like large-hole inpainting, and class-conditional image synthesis.
Learning Audio Representations with MLPs
Mar 16, 2022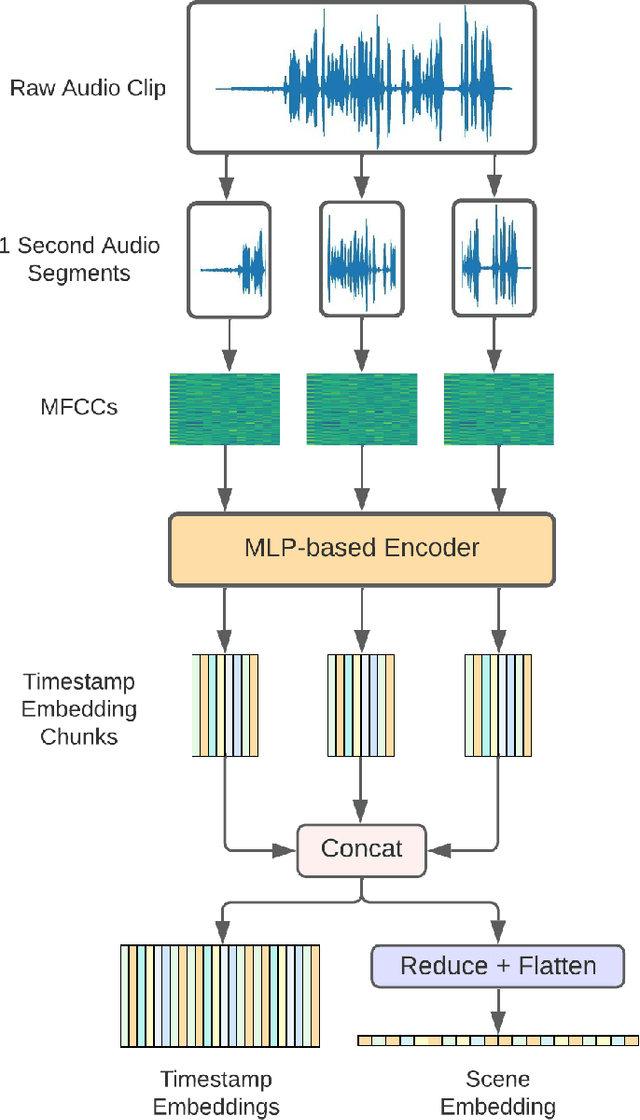
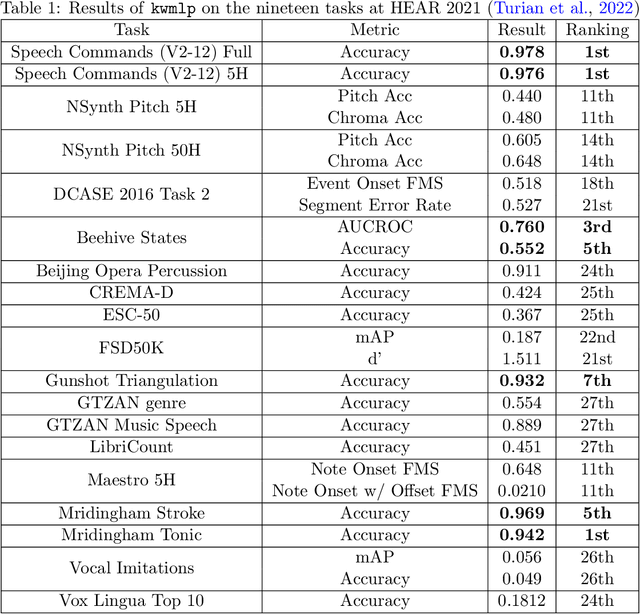
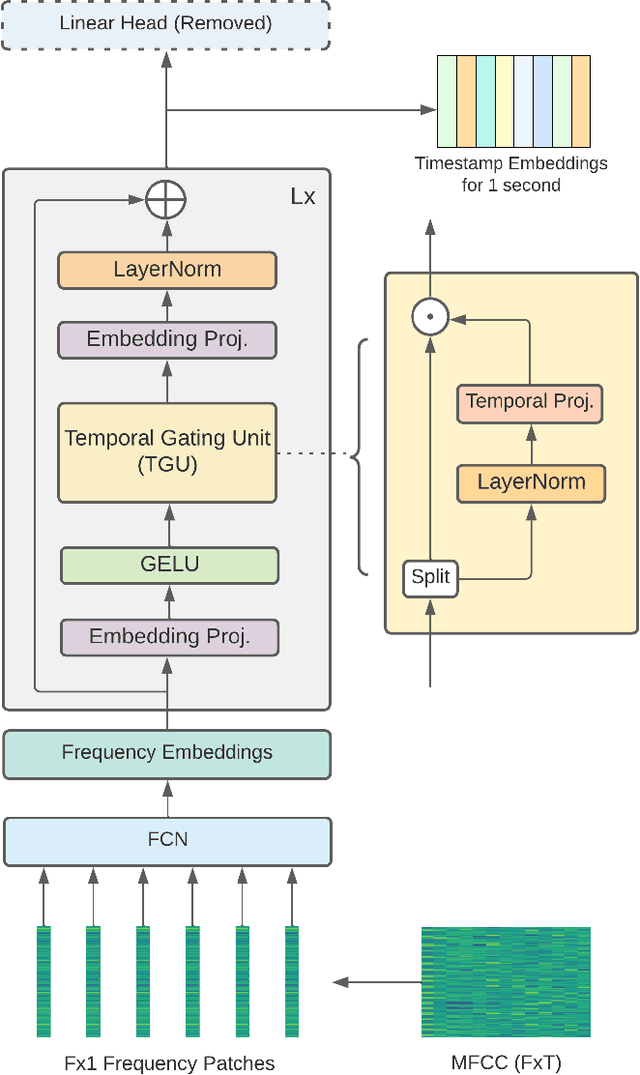
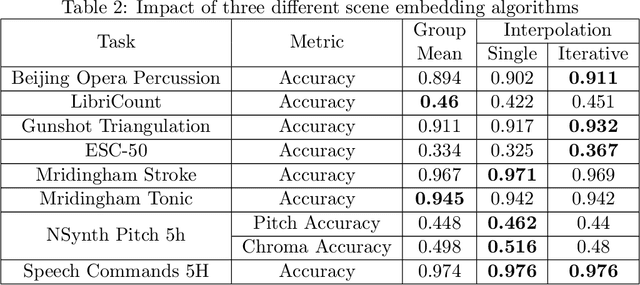
In this paper, we propose an efficient MLP-based approach for learning audio representations, namely timestamp and scene-level audio embeddings. We use an encoder consisting of sequentially stacked gated MLP blocks, which accept 2D MFCCs as inputs. In addition, we also provide a simple temporal interpolation-based algorithm for computing scene-level embeddings from timestamp embeddings. The audio representations generated by our method are evaluated across a diverse set of benchmarks at the Holistic Evaluation of Audio Representations (HEAR) challenge, hosted at the NeurIPS 2021 competition track. We achieved first place on the Speech Commands (full), Speech Commands (5 hours), and the Mridingham Tonic benchmarks. Furthermore, our approach is also the most resource-efficient among all the submitted methods, in terms of both the number of model parameters and the time required to compute embeddings.
Attention-Free Keyword Spotting
Oct 18, 2021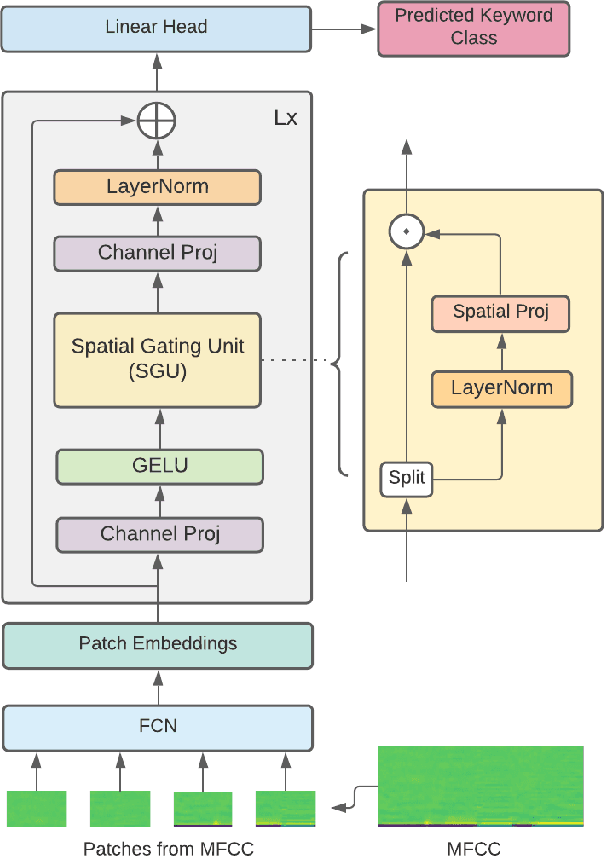
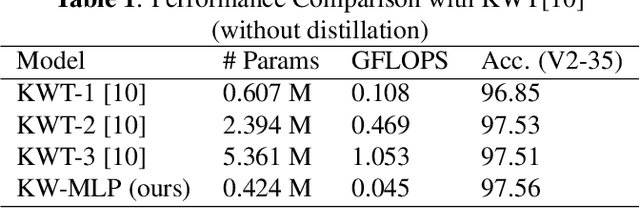
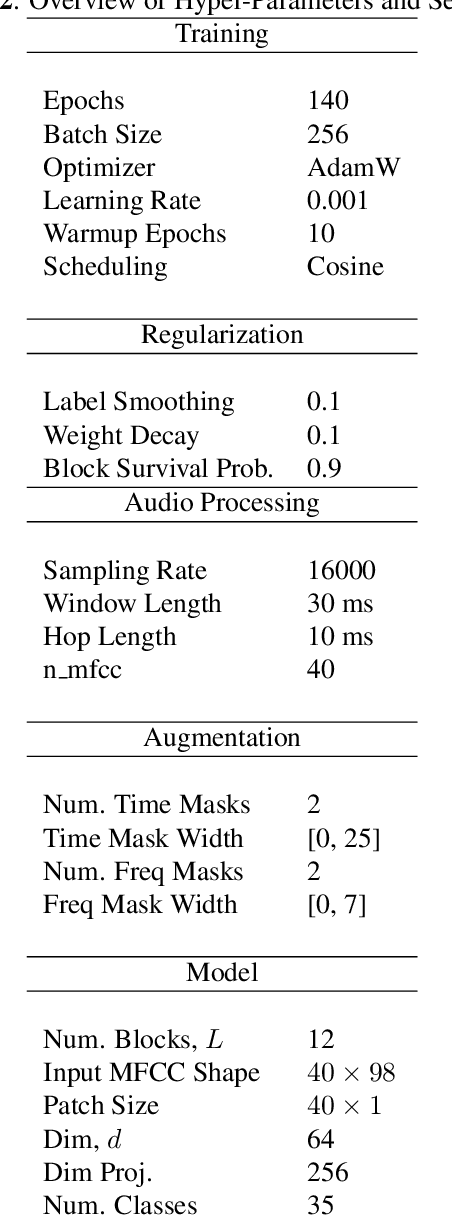
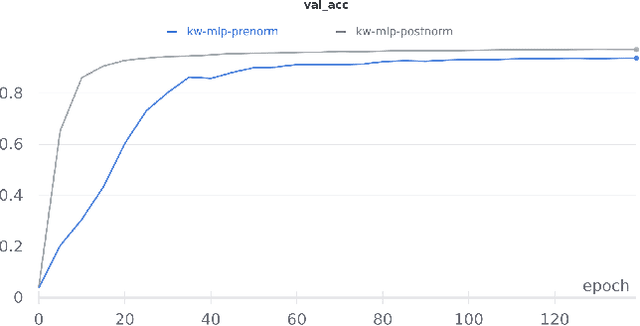
Till now, attention-based models have been used with great success in the keyword spotting problem domain. However, in light of recent advances in deep learning, the question arises whether self-attention is truly irreplaceable for recognizing speech keywords. We thus explore the usage of gated MLPs -- previously shown to be alternatives to transformers in vision tasks -- for the keyword spotting task. We verify our approach on the Google Speech Commands V2-35 dataset and show that it is possible to obtain performance comparable to the state of the art without any apparent usage of self-attention.