Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Free Keyword Spotting
Paper and Code
Oct 18, 2021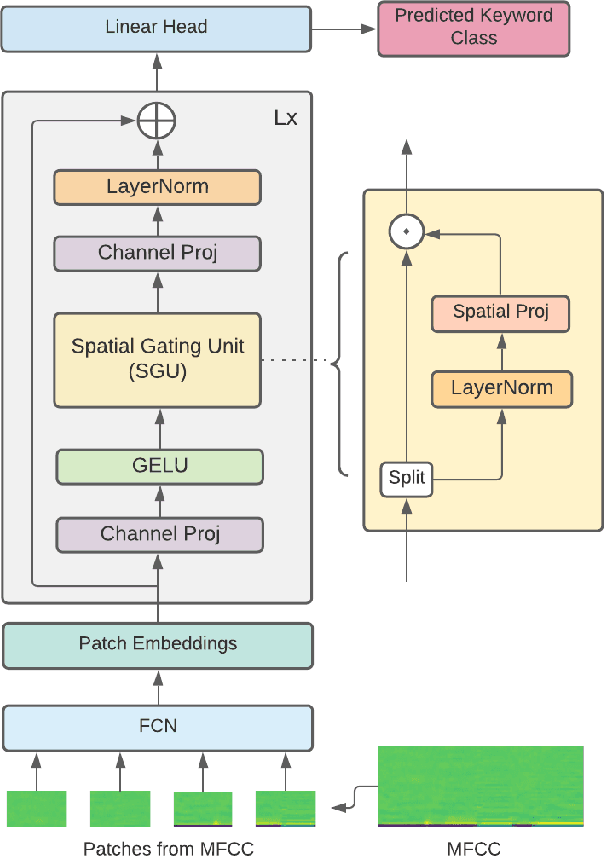
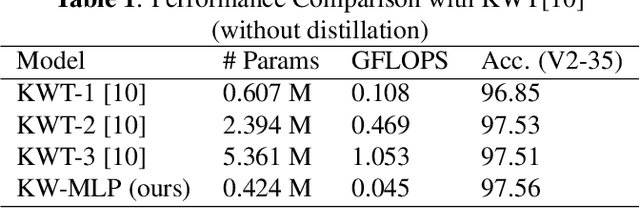
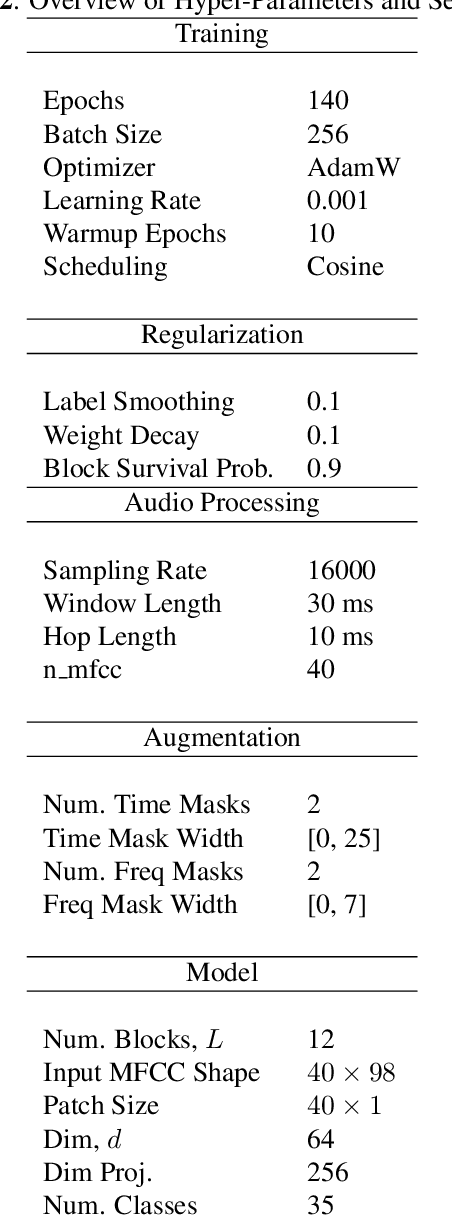
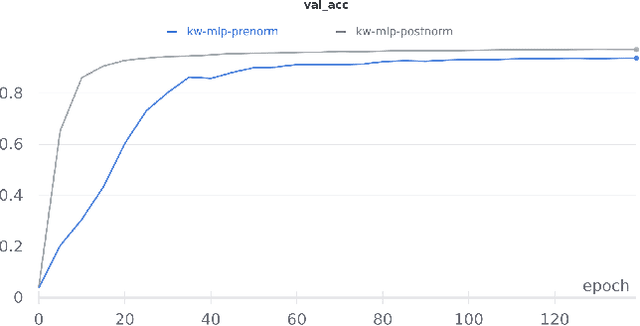
Till now, attention-based models have been used with great success in the keyword spotting problem domain. However, in light of recent advances in deep learning, the question arises whether self-attention is truly irreplaceable for recognizing speech keywords. We thus explore the usage of gated MLPs -- previously shown to be alternatives to transformers in vision tasks -- for the keyword spotting task. We verify our approach on the Google Speech Commands V2-35 dataset and show that it is possible to obtain performance comparable to the state of the art without any apparent usage of self-attention.
* Submitted to ICASSP-2022 (5 pages)
View paper on