 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse 3D Reconstructions from a Single Occluded Face Image
Dec 01, 2021
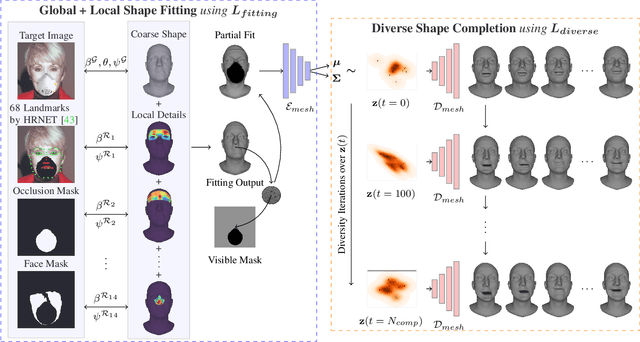


Occlusions are a common occurrence in unconstrained face images. Single image 3D reconstruction from such face images often suffers from corruption due to the presence of occlusions. Furthermore, while a plurality of 3D reconstructions is plausible in the occluded regions, existing approaches are limited to generating only a single solution. To address both of these challenges, we present Diverse3DFace, which is specifically designed to simultaneously generate a diverse and realistic set of 3D reconstructions from a single occluded face image. It consists of three components: a global+local shape fitting process, a graph neural network-based mesh VAE, and a Determinantal Point Process based diversity promoting iterative optimization procedure. Quantitative and qualitative comparisons of 3D reconstruction on occluded faces show that Diverse3DFace can estimate 3D shapes that are consistent with the visible regions in the target image while exhibiting high, yet realistic, levels of diversity on the occluded regions. On face images occluded by masks, glasses, and other random objects, Diverse3DFace generates a distribution of 3D shapes having ~50% higher diversity on the occluded regions compared to the baselines. Moreover, our closest sample to the ground truth has ~40% lower MSE than the singular reconstructions by existing approaches.
3DFaceFill: An Analysis-By-Synthesis Approach to Face Completion
Oct 20, 2021
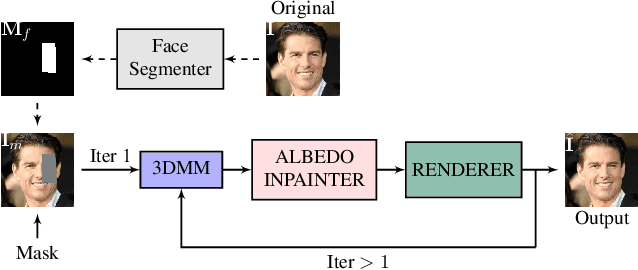


Existing face completion solutions are primarily driven by end-to-end models that directly generate 2D completions of 2D masked faces. By having to implicitly account for geometric and photometric variations in facial shape and appearance, such approaches result in unrealistic completions, especially under large variations in pose, shape, illumination and mask sizes. To alleviate these limitations, we introduce 3DFaceFill, an analysis-by-synthesis approach for face completion that explicitly considers the image formation process. It comprises three components, (1) an encoder that disentangles the face into its constituent 3D mesh, 3D pose, illumination and albedo factors, (2) an autoencoder that inpaints the UV representation of facial albedo, and (3) a renderer that resynthesizes the completed face. By operating on the UV representation, 3DFaceFill affords the power of correspondence and allows us to naturally enforce geometrical priors (e.g. facial symmetry) more effectively. Quantitatively, 3DFaceFill improves the state-of-the-art by up to 4dB higher PSNR and 25% better LPIPS for large masks. And, qualitatively, it leads to demonstrably more photorealistic face completions over a range of masks and occlusions while preserving consistency in global and component-wise shape, pose, illumination and eye-gaze.
RankGAN: A Maximum Margin Ranking GAN for Generating Faces
Dec 19, 2018



We present a new stage-wise learning paradigm for training generative adversarial networks (GANs). The goal of our work is to progressively strengthen the discriminator and thus, the generators, with each subsequent stage without changing the network architecture. We call this proposed method the RankGAN. We first propose a margin-based loss for the GAN discriminator. We then extend it to a margin-based ranking loss to train the multiple stages of RankGAN. We focus on face images from the CelebA dataset in our work and show visual as well as quantitative improvements in face generation and completion tasks over other GAN approaches, including WGAN and LSGAN.
Gate-Variants of Gated Recurrent Unit Neural Networks
Jan 20, 2017
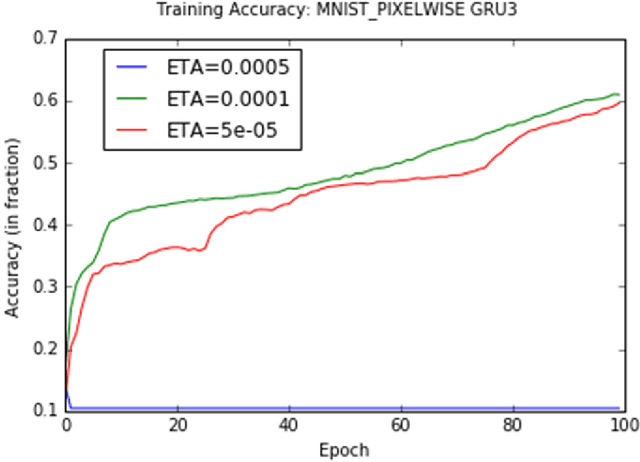
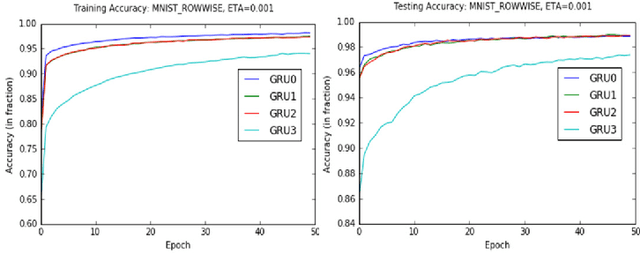
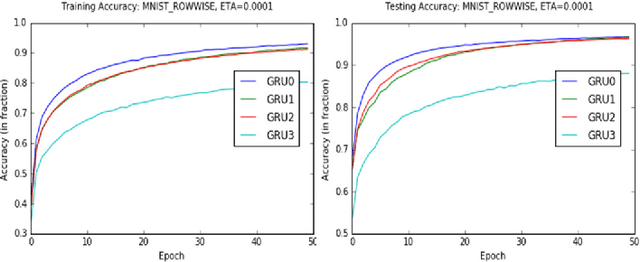
The paper evaluates three variants of the Gated Recurrent Unit (GRU) in recurrent neural networks (RNN) by reducing parameters in the update and reset gates. We evaluate the three variant GRU models on MNIST and IMDB datasets and show that these GRU-RNN variant models perform as well as the original GRU RNN model while reducing the computational expense.