 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis Using Simplified Long Short-term Memory Recurrent Neural Networks
May 08, 2020

LSTM or Long Short Term Memory Networks is a specific type of Recurrent Neural Network (RNN) that is very effective in dealing with long sequence data and learning long term dependencies. In this work, we perform sentiment analysis on a GOP Debate Twitter dataset. To speed up training and reduce the computational cost and time, six different parameter reduced slim versions of the LSTM model (slim LSTM) are proposed. We evaluate two of these models on the dataset. The performance of these two LSTM models along with the standard LSTM model is compared. The effect of Bidirectional LSTM Layers is also studied. The work also consists of a study to choose the best architecture, apart from establishing the best set of hyper parameters for different LSTM Models.
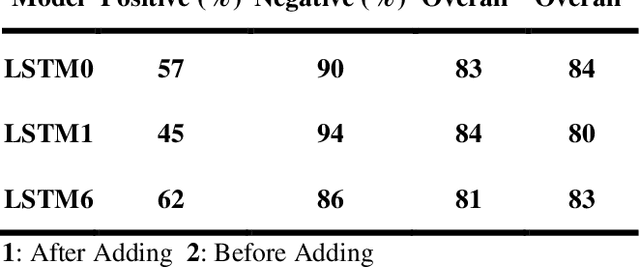
Slim LSTM networks: LSTM_6 and LSTM_C6
Jan 18, 2019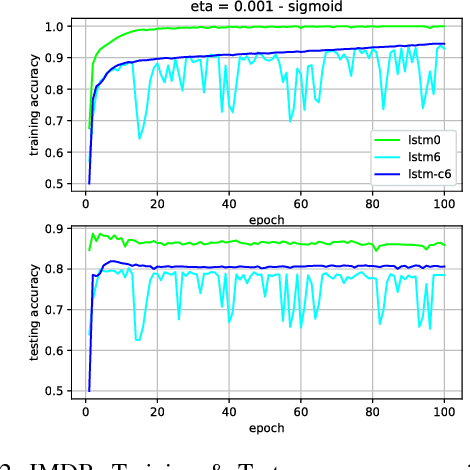
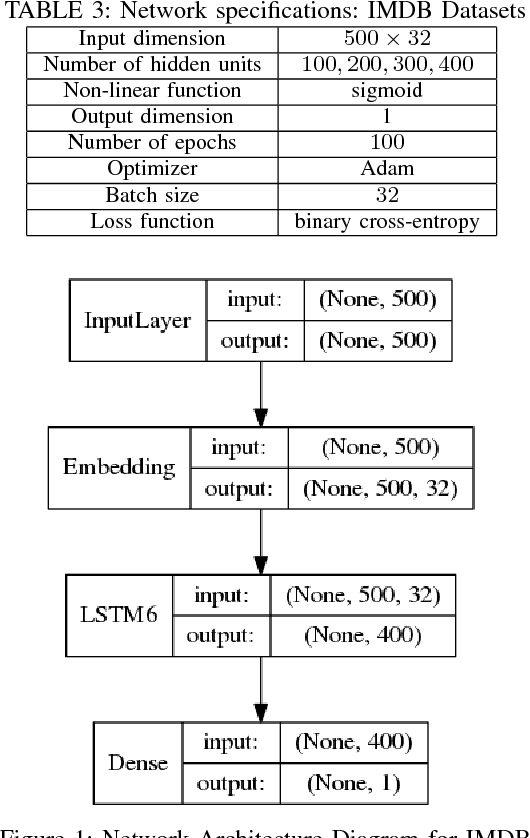
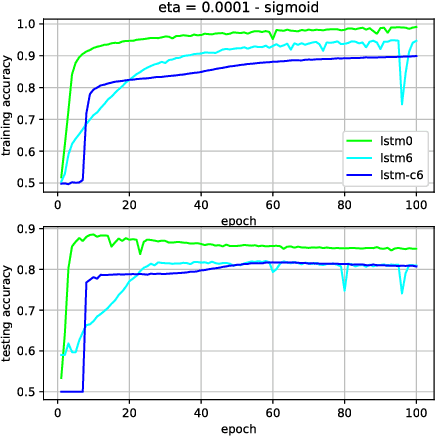

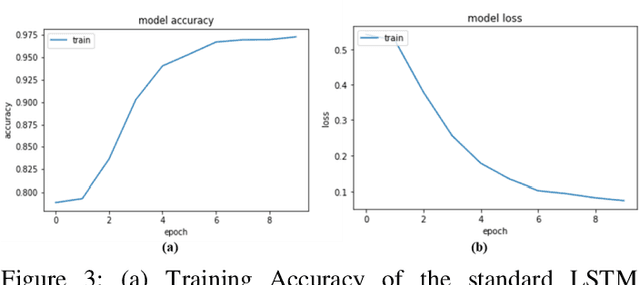
We have shown previously that our parameter-reduced variants of Long Short-Term Memory (LSTM) Recurrent Neural Networks (RNN) are comparable in performance to the standard LSTM RNN on the MNIST dataset. In this study, we show that this is also the case for two diverse benchmark datasets, namely, the review sentiment IMDB and the 20 Newsgroup datasets. Specifically, we focus on two of the simplest variants, namely LSTM_6 (i.e., standard LSTM with three constant fixed gates) and LSTM_C6 (i.e., LSTM_6 with further reduced cell body input block). We demonstrate that these two aggressively reduced-parameter variants are competitive with the standard LSTM when hyper-parameters, e.g., learning parameter, number of hidden units and gate constants are set properly. These architectures enable speeding up training computations and hence, these networks would be more suitable for online training and inference onto portable devices with relatively limited computational resources.
Performance of Three Slim Variants of The Long Short-Term Memory Layer
Jan 02, 2019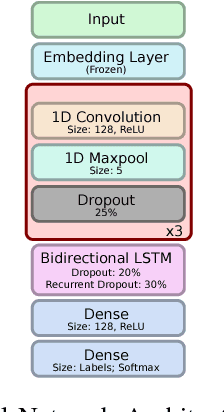
The Long Short-Term Memory (LSTM) layer is an important advancement in the field of neural networks and machine learning, allowing for effective training and impressive inference performance. LSTM-based neural networks have been successfully employed in various applications such as speech processing and language translation. The LSTM layer can be simplified by removing certain components, potentially speeding up training and runtime with limited change in performance. In particular, the recently introduced variants, called SLIM LSTMs, have shown success in initial experiments to support this view. Here, we perform computational analysis of the validation accuracy of a convolutional plus recurrent neural network architecture using comparatively the standard LSTM and three SLIM LSTM layers. We have found that some realizations of the SLIM LSTM layers can potentially perform as well as the standard LSTM layer for our considered architecture.
SLIM LSTMs
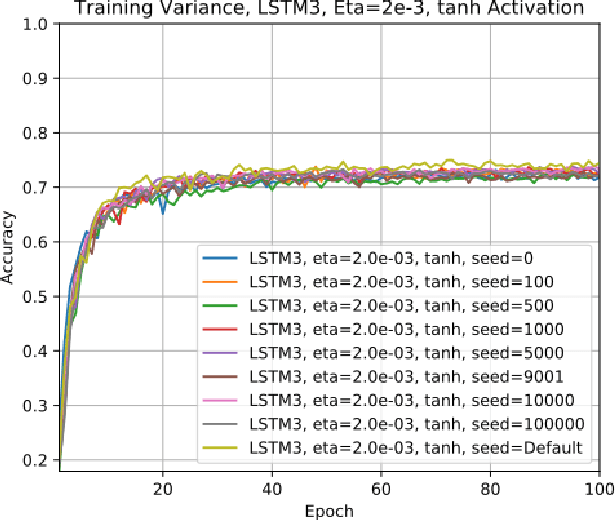
Dec 29, 2018Long Short-Term Memory (LSTM) Recurrent Neural networks (RNNs) rely on gating signals, each driven by a function of a weighted sum of at least 3 components: (i) one of an adaptive weight matrix multiplied by the incoming external input vector sequence, (ii) one adaptive weight matrix multiplied by the previous memory/state vector, and (iii) one adaptive bias vector. In effect, they augment the simple Recurrent Neural Networks (sRNNs) structure with the addition of a "memory cell" and the incorporation of at most 3 gating signals. The standard LSTM structure and components encompass redundancy and overly increased parameterization. In this paper, we systemically introduce variants of the LSTM RNNs, referred to as SLIM LSTMs. These variants express aggressively reduced parameterizations to achieve computational saving and/or speedup in (training) performance---while necessarily retaining (validation accuracy) performance comparable to the standard LSTM RNN.
Simplified Long Short-term Memory Recurrent Neural Networks: part III
Jul 14, 2017


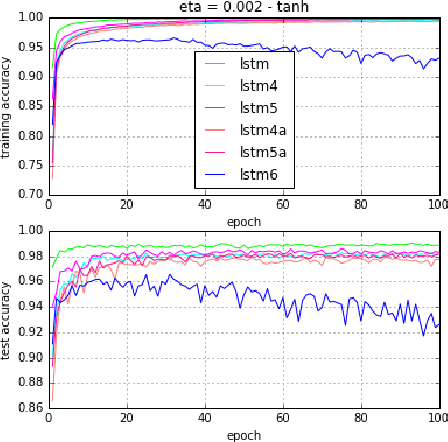
This is part III of three-part work. In parts I and II, we have presented eight variants for simplified Long Short Term Memory (LSTM) recurrent neural networks (RNNs). It is noted that fast computation, specially in constrained computing resources, are an important factor in processing big time-sequence data. In this part III paper, we present and evaluate two new LSTM model variants which dramatically reduce the computational load while retaining comparable performance to the base (standard) LSTM RNNs. In these new variants, we impose (Hadamard) pointwise state multiplications in the cell-memory network in addition to the gating signal networks.
Simplified Long Short-term Memory Recurrent Neural Networks: part II
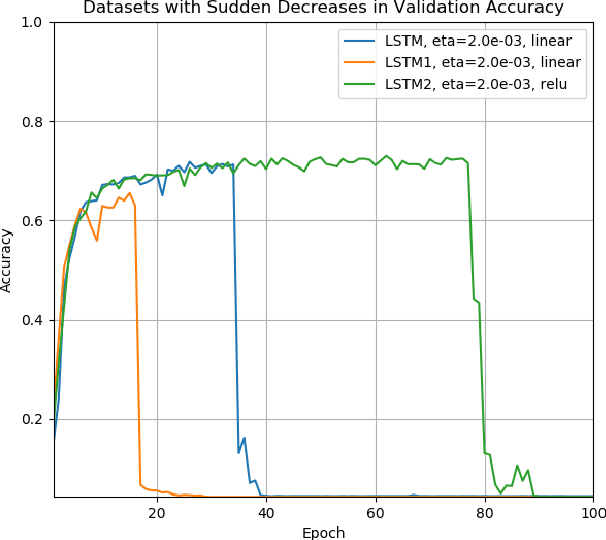
Jul 14, 2017This is part II of three-part work. Here, we present a second set of inter-related five variants of simplified Long Short-term Memory (LSTM) recurrent neural networks by further reducing adaptive parameters. Two of these models have been introduced in part I of this work. We evaluate and verify our model variants on the benchmark MNIST dataset and assert that these models are comparable to the base LSTM model while use progressively less number of parameters. Moreover, we observe that in case of using the ReLU activation, the test accuracy performance of the standard LSTM will drop after a number of epochs when learning parameter become larger. However all of the new model variants sustain their performance.
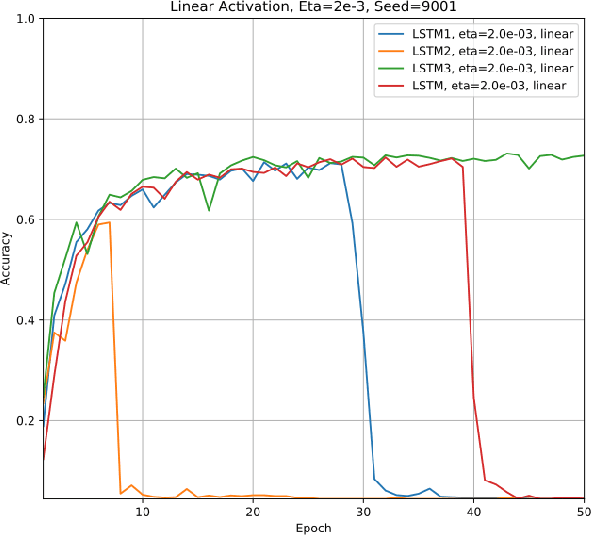
Simplified Long Short-term Memory Recurrent Neural Networks: part I
Jul 14, 2017We present five variants of the standard Long Short-term Memory (LSTM) recurrent neural networks by uniformly reducing blocks of adaptive parameters in the gating mechanisms. For simplicity, we refer to these models as LSTM1, LSTM2, LSTM3, LSTM4, and LSTM5, respectively. Such parameter-reduced variants enable speeding up data training computations and would be more suitable for implementations onto constrained embedded platforms. We comparatively evaluate and verify our five variant models on the classical MNIST dataset and demonstrate that these variant models are comparable to a standard implementation of the LSTM model while using less number of parameters. Moreover, we observe that in some cases the standard LSTM's accuracy performance will drop after a number of epochs when using the ReLU nonlinearity; in contrast, however, LSTM3, LSTM4 and LSTM5 will retain their performance.
Gate-Variants of Gated Recurrent Unit Neural Networks
Jan 20, 2017
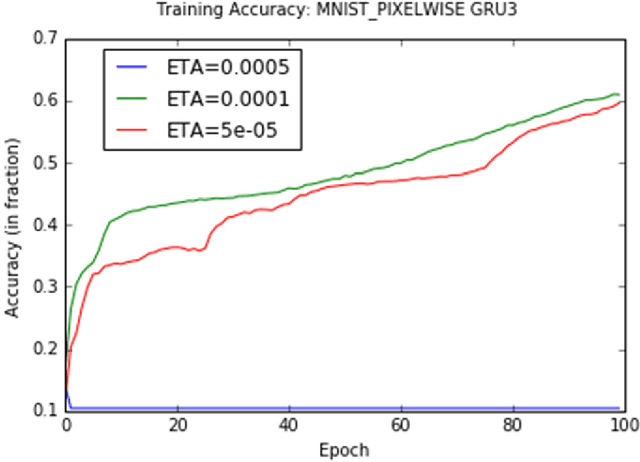
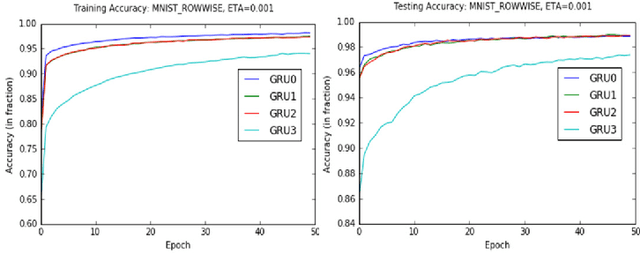
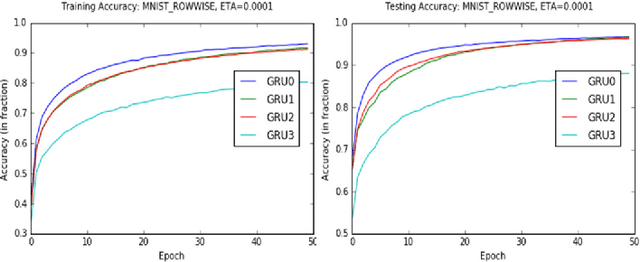
The paper evaluates three variants of the Gated Recurrent Unit (GRU) in recurrent neural networks (RNN) by reducing parameters in the update and reset gates. We evaluate the three variant GRU models on MNIST and IMDB datasets and show that these GRU-RNN variant models perform as well as the original GRU RNN model while reducing the computational expense.
Simplified Minimal Gated Unit Variations for Recurrent Neural Networks
Jan 12, 2017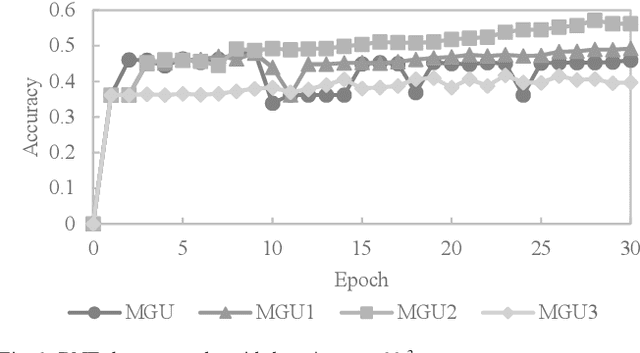

Recurrent neural networks with various types of hidden units have been used to solve a diverse range of problems involving sequence data. Two of the most recent proposals, gated recurrent units (GRU) and minimal gated units (MGU), have shown comparable promising results on example public datasets. In this paper, we introduce three model variants of the minimal gated unit (MGU) which further simplify that design by reducing the number of parameters in the forget-gate dynamic equation. These three model variants, referred to simply as MGU1, MGU2, and MGU3, were tested on sequences generated from the MNIST dataset and from the Reuters Newswire Topics (RNT) dataset. The new models have shown similar accuracy to the MGU model while using fewer parameters and thus lowering training expense. One model variant, namely MGU2, performed better than MGU on the datasets considered, and thus may be used as an alternate to MGU or GRU in recurrent neural networks.
Simplified Gating in Long Short-term Memory Recurrent Neural Networks
Jan 12, 2017



The standard LSTM recurrent neural networks while very powerful in long-range dependency sequence applications have highly complex structure and relatively large (adaptive) parameters. In this work, we present empirical comparison between the standard LSTM recurrent neural network architecture and three new parameter-reduced variants obtained by eliminating combinations of the input signal, bias, and hidden unit signals from individual gating signals. The experiments on two sequence datasets show that the three new variants, called simply as LSTM1, LSTM2, and LSTM3, can achieve comparable performance to the standard LSTM model with less (adaptive) parameters.