 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of On-Ground Chestnuts Using Artificial Intelligence Toward Automated Picking
Feb 15, 2026Traditional mechanized chestnut harvesting is too costly for small producers, non-selective, and prone to damaging nuts. Accurate, reliable detection of chestnuts on the orchard floor is crucial for developing low-cost, vision-guided automated harvesting technology. However, developing a reliable chestnut detection system faces challenges in complex environments with shading, varying natural light conditions, and interference from weeds, fallen leaves, stones, and other foreign on-ground objects, which have remained unaddressed. This study collected 319 images of chestnuts on the orchard floor, containing 6524 annotated chestnuts. A comprehensive set of 29 state-of-the-art real-time object detectors, including 14 in the YOLO (v11-13) and 15 in the RT-DETR (v1-v4) families at varied model scales, was systematically evaluated through replicated modeling experiments for chestnut detection. Experimental results show that the YOLOv12m model achieves the best mAP@0.5 of 95.1% among all the evaluated models, while the RT-DETRv2-R101 was the most accurate variant among RT-DETR models, with mAP@0.5 of 91.1%. In terms of mAP@[0.5:0.95], the YOLOv11x model achieved the best accuracy of 80.1%. All models demonstrate significant potential for real-time chestnut detection, and YOLO models outperformed RT-DETR models in terms of both detection accuracy and inference, making them better suited for on-board deployment. Both the dataset and software programs in this study have been made publicly available at https://github.com/AgFood-Sensing-and-Intelligence-Lab/ChestnutDetection.
Semi-Supervised Weed Detection in Vegetable Fields: In-domain and Cross-domain Experiments
Feb 24, 2025
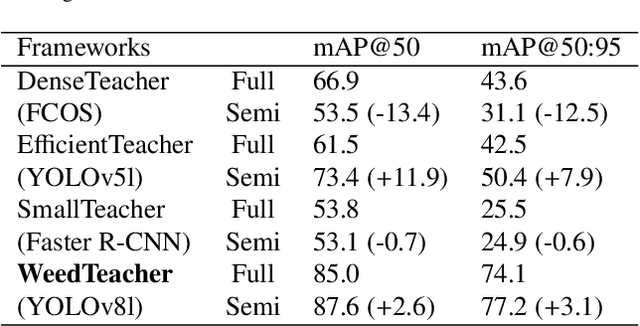

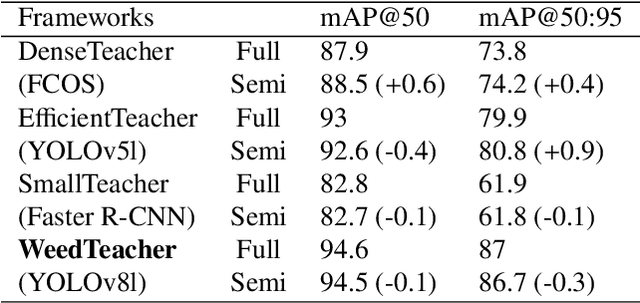
Robust weed detection remains a challenging task in precision weeding, requiring not only potent weed detection models but also large-scale, labeled data. However, the labeled data adequate for model training is practically difficult to come by due to the time-consuming, labor-intensive process that requires specialized expertise to recognize plant species. This study introduces semi-supervised object detection (SSOD) methods for leveraging unlabeled data for enhanced weed detection and proposes a new YOLOv8-based SSOD method, i.e., WeedTeacher. An experimental comparison of four SSOD methods, including three existing frameworks (i.e., DenseTeacher, EfficientTeacher, and SmallTeacher) and WeedTeacher, alongside fully supervised baselines, was conducted for weed detection in both in-domain and cross-domain contexts. A new, diverse weed dataset was created as the testbed, comprising a total of 19,931 field images from two differing domains, including 8,435 labeled (basic-domain) images acquired by handholding devices from 2021 to 2023 and 11,496 unlabeled (new-domain) images acquired by a ground-based mobile platform in 2024. The in-domain experiment with models trained using 10% of the labeled, basic-domain images and tested on the remaining 90% of the data, showed that the YOLOv8-basedWeedTeacher achieved the highest accuracy among all four SSOD methods, with an improvement of 2.6% mAP@50 and 3.1% mAP@50:95 over its supervised baseline (i.e., YOLOv8l). In the cross-domain experiment where the unlabeled new-domain data was incorporated, all four SSOD methods, however, resulted in no or limited improvements over their supervised counterparts. Research is needed to address the difficulty of cross-domain data utilization for robust weed detection.
Public Computer Vision Datasets for Precision Livestock Farming: A Systematic Survey
Jun 15, 2024



Technology-driven precision livestock farming (PLF) empowers practitioners to monitor and analyze animal growth and health conditions for improved productivity and welfare. Computer vision (CV) is indispensable in PLF by using cameras and computer algorithms to supplement or supersede manual efforts for livestock data acquisition. Data availability is crucial for developing innovative monitoring and analysis systems through artificial intelligence-based techniques. However, data curation processes are tedious, time-consuming, and resource intensive. This study presents the first systematic survey of publicly available livestock CV datasets (https://github.com/Anil-Bhujel/Public-Computer-Vision-Dataset-A-Systematic-Survey). Among 58 public datasets identified and analyzed, encompassing different species of livestock, almost half of them are for cattle, followed by swine, poultry, and other animals. Individual animal detection and color imaging are the dominant application and imaging modality for livestock. The characteristics and baseline applications of the datasets are discussed, emphasizing the implications for animal welfare advocates. Challenges and opportunities are also discussed to inspire further efforts in developing livestock CV datasets. This study highlights that the limited quantity of high-quality annotated datasets collected from diverse environments, animals, and applications, the absence of contextual metadata, are a real bottleneck in PLF.
Deep Data Augmentation for Weed Recognition Enhancement: A Diffusion Probabilistic Model and Transfer Learning Based Approach
Oct 18, 2022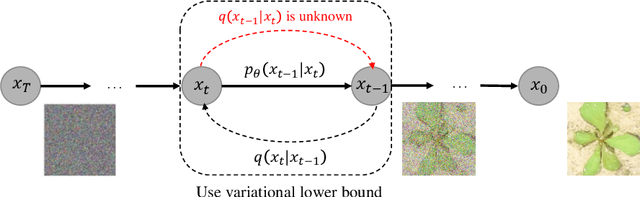
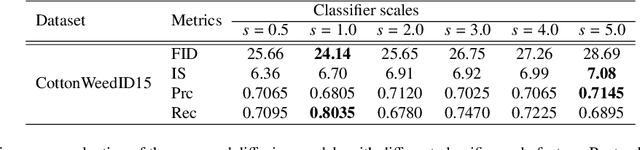
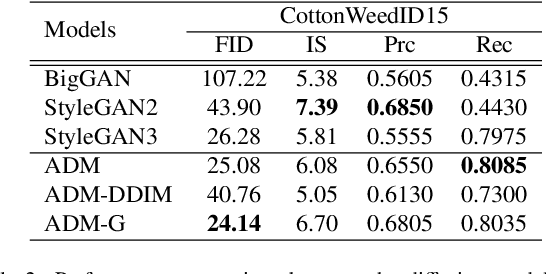

Weed management plays an important role in many modern agricultural applications. Conventional weed control methods mainly rely on chemical herbicides or hand weeding, which are often cost-ineffective, environmentally unfriendly, or even posing a threat to food safety and human health. Recently, automated/robotic weeding using machine vision systems has seen increased research attention with its potential for precise and individualized weed treatment. However, dedicated, large-scale, and labeled weed image datasets are required to develop robust and effective weed identification systems but they are often difficult and expensive to obtain. To address this issue, data augmentation approaches, such as generative adversarial networks (GANs), have been explored to generate highly realistic images for agricultural applications. Yet, despite some progress, those approaches are often complicated to train or have difficulties preserving fine details in images. In this paper, we present the first work of applying diffusion probabilistic models (also known as diffusion models) to generate high-quality synthetic weed images based on transfer learning. Comprehensive experimental results show that the developed approach consistently outperforms several state-of-the-art GAN models, representing the best trade-off between sample fidelity and diversity and highest FID score on a common weed dataset, CottonWeedID15. In addition, the expanding dataset with synthetic weed images can apparently boost model performance on four deep learning (DL) models for the weed classification tasks. Furthermore, the DL models trained on CottonWeedID15 dataset with only 10% of real images and 90% of synthetic weed images achieve a testing accuracy of over 94%, showing high-quality of the generated weed samples. The codes of this study are made publicly available at https://github.com/DongChen06/DMWeeds.
Generative Adversarial Networks for Image Augmentation in Agriculture: A Systematic Review
Apr 12, 2022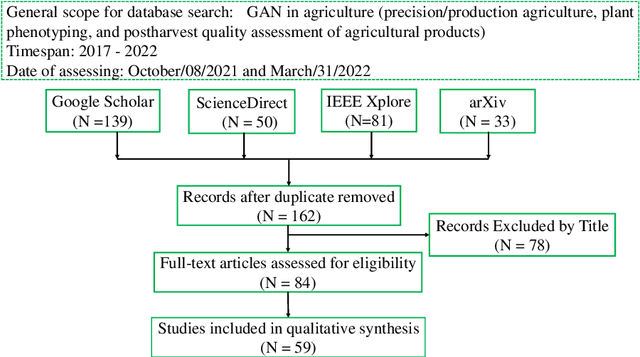

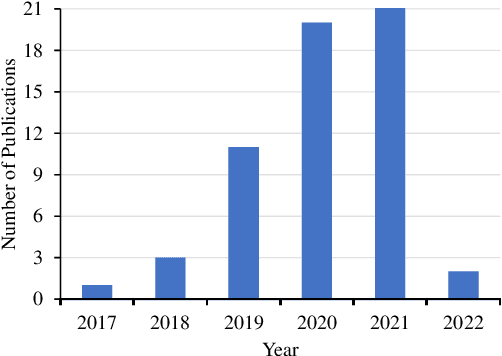
In agricultural image analysis, optimal model performance is keenly pursued for better fulfilling visual recognition tasks (e.g., image classification, segmentation, object detection and localization), in the presence of challenges with biological variability and unstructured environments. Large-scale, balanced and ground-truthed image datasets, however, are often difficult to obtain to fuel the development of advanced, high-performance models. As artificial intelligence through deep learning is impacting analysis and modeling of agricultural images, data augmentation plays a crucial role in boosting model performance while reducing manual efforts for data preparation, by algorithmically expanding training datasets. Beyond traditional data augmentation techniques, generative adversarial network (GAN) invented in 2014 in the computer vision community, provides a suite of novel approaches that can learn good data representations and generate highly realistic samples. Since 2017, there has been a growth of research into GANs for image augmentation or synthesis in agriculture for improved model performance. This paper presents an overview of the evolution of GAN architectures followed by a systematic review of their application to agriculture (https://github.com/Derekabc/GANs-Agriculture), involving various vision tasks for plant health, weeds, fruits, aquaculture, animal farming, plant phenotyping as well as postharvest detection of fruit defects. Challenges and opportunities of GANs are discussed for future research.
Performance Evaluation of Deep Transfer Learning on Multiclass Identification of Common Weed Species in Cotton Production Systems
Oct 11, 2021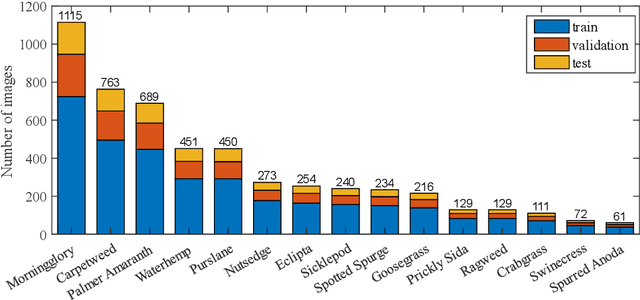
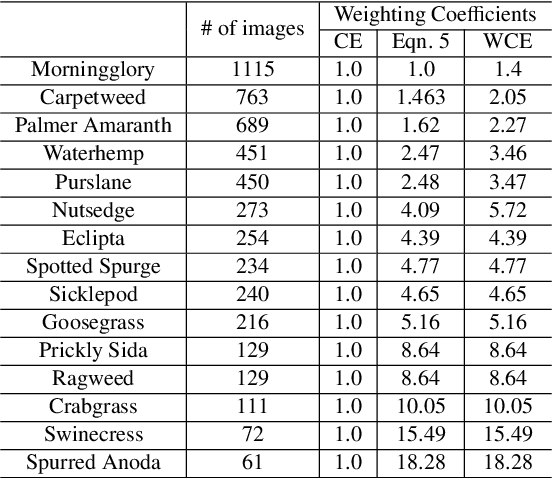

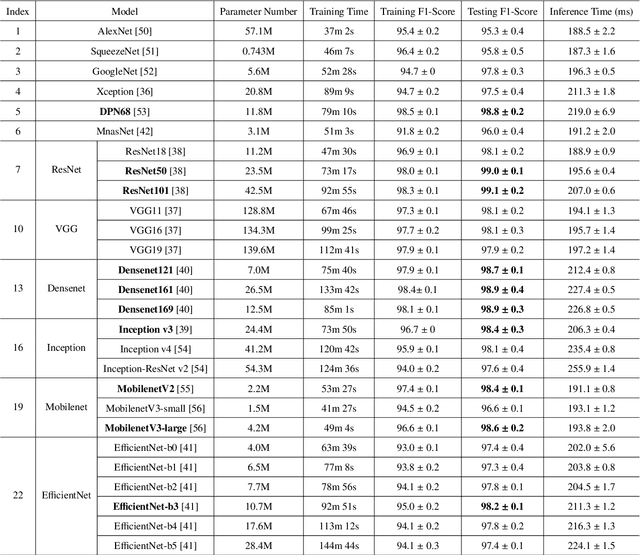
Precision weed management offers a promising solution for sustainable cropping systems through the use of chemical-reduced/non-chemical robotic weeding techniques, which apply suitable control tactics to individual weeds. Therefore, accurate identification of weed species plays a crucial role in such systems to enable precise, individualized weed treatment. This paper makes a first comprehensive evaluation of deep transfer learning (DTL) for identifying common weeds specific to cotton production systems in southern United States. A new dataset for weed identification was created, consisting of 5187 color images of 15 weed classes collected under natural lighting conditions and at varied weed growth stages, in cotton fields during the 2020 and 2021 field seasons. We evaluated 27 state-of-the-art deep learning models through transfer learning and established an extensive benchmark for the considered weed identification task. DTL achieved high classification accuracy of F1 scores exceeding 95%, requiring reasonably short training time (less than 2.5 hours) across models. ResNet101 achieved the best F1-score of 99.1% whereas 14 out of the 27 models achieved F1 scores exceeding 98.0%. However, the performance on minority weed classes with few training samples was less satisfactory for models trained with a conventional, unweighted cross entropy loss function. To address this issue, a weighted cross entropy loss function was adopted, which achieved substantially improved accuracies for minority weed classes. Furthermore, a deep learning-based cosine similarity metrics was employed to analyze the similarity among weed classes, assisting in the interpretation of classifications. Both the codes for model benchmarking and the weed dataset are made publicly available, which expect to be be a valuable resource for future research in weed identification and beyond.
Out-of-focus Blur: Image De-blurring
Nov 02, 2017

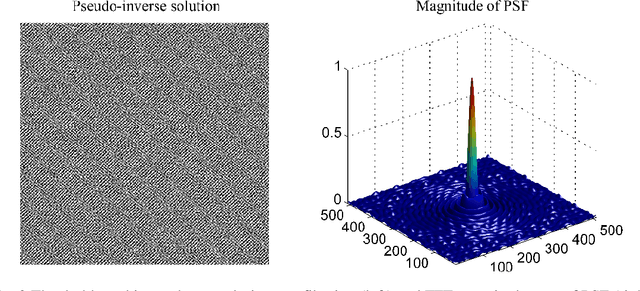

Image de-blurring is important in many cases of imaging a real scene or object by a camera. This project focuses on de-blurring an image distorted by an out-of-focus blur through a simulation study. A pseudo-inverse filter is first explored but it fails because of severe noise amplification. Then Tikhonov regularization methods are employed, which produce greatly improved results compared to the pseudo-inverse filter. In Tikhonov regularization, the choice of the regularization parameter plays a critical rule in obtaining a high-quality image, and the regularized solutions possess a semi-convergence property. The best result, with the relative restoration error of 8.49%, is achieved when the prescribed discrepancy principle is used to decide an optimal value. Furthermore, an iterative method, Conjugated Gradient, is employed for image de-blurring, which is fast in computation and leads to an even better result with the relative restoration error of 8.22%. The number of iteration in CG acts as a regularization parameter, and the iterates have a semi-convergence property as well.
Simplified Gating in Long Short-term Memory Recurrent Neural Networks
Jan 12, 2017



The standard LSTM recurrent neural networks while very powerful in long-range dependency sequence applications have highly complex structure and relatively large (adaptive) parameters. In this work, we present empirical comparison between the standard LSTM recurrent neural network architecture and three new parameter-reduced variants obtained by eliminating combinations of the input signal, bias, and hidden unit signals from individual gating signals. The experiments on two sequence datasets show that the three new variants, called simply as LSTM1, LSTM2, and LSTM3, can achieve comparable performance to the standard LSTM model with less (adaptive) parameters.
Empirical Evaluation of A New Approach to Simplifying Long Short-term Memory
Dec 12, 2016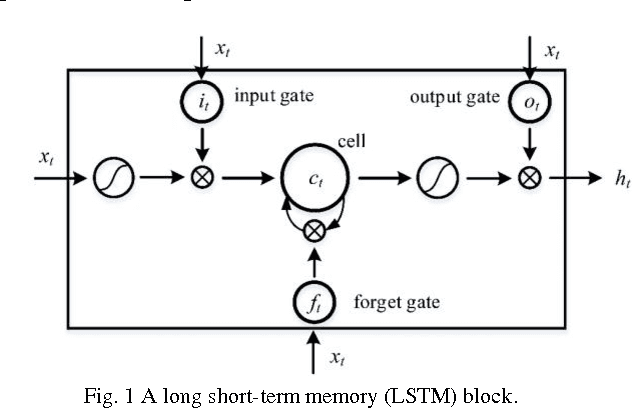
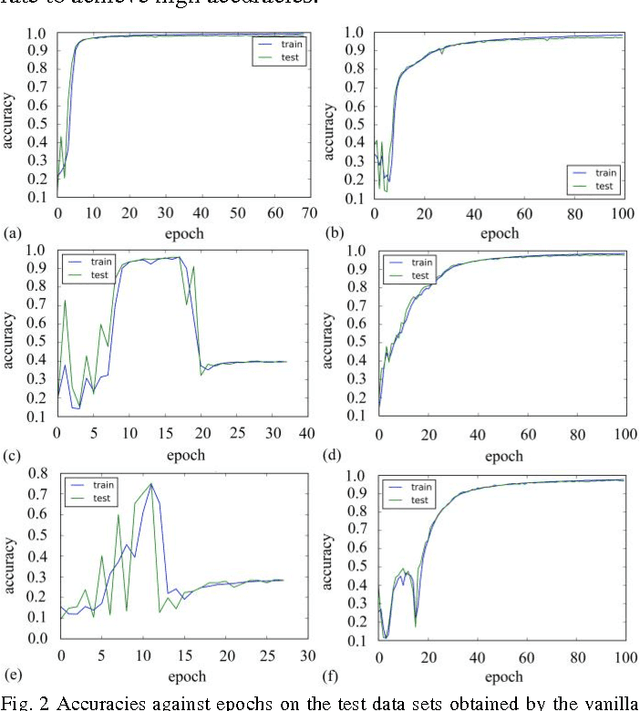
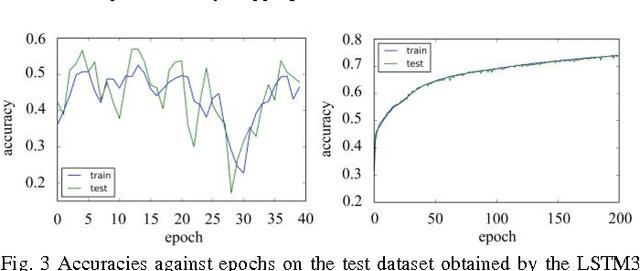
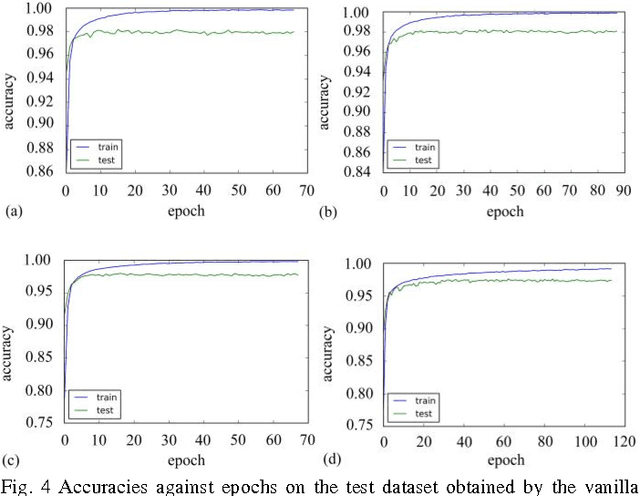
The standard LSTM, although it succeeds in the modeling long-range dependences, suffers from a highly complex structure that can be simplified through modifications to its gate units. This paper was to perform an empirical comparison between the standard LSTM and three new simplified variants that were obtained by eliminating input signal, bias and hidden unit signal from individual gates, on the tasks of modeling two sequence datasets. The experiments show that the three variants, with reduced parameters, can achieve comparable performance with the standard LSTM. Due attention should be paid to turning the learning rate to achieve high accuracies
Food Image Recognition by Using Convolutional Neural Networks (CNNs)
Dec 03, 2016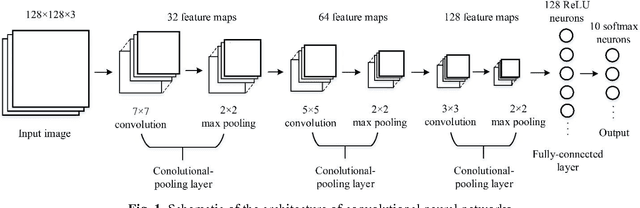


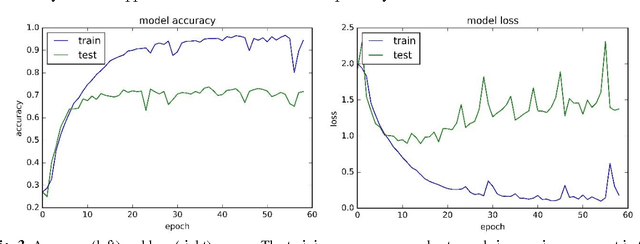
Food image recognition is one of the promising applications of visual object recognition in computer vision. In this study, a small-scale dataset consisting of 5822 images of ten categories and a five-layer CNN was constructed to recognize these images. The bag-of-features (BoF) model coupled with support vector machine was first tested as comparison, resulting in an overall accuracy of 56%, while the CNN performed much better with an overall accuracy of 74%. Data expansion techniques were applied to increase the size of training images, which achieved a significantly improved accuracy of more than 90% and prevent the overfitting issue that occurred to the CNN without using data expansion. Further improvement is within reach by collecting more images and optimizing the network architecture and relevant hyper-parameters.