 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood Image Recognition by Using Convolutional Neural Networks (CNNs)
Paper and Code
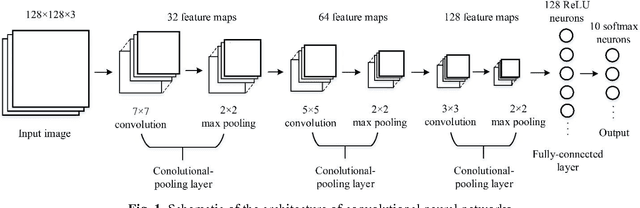


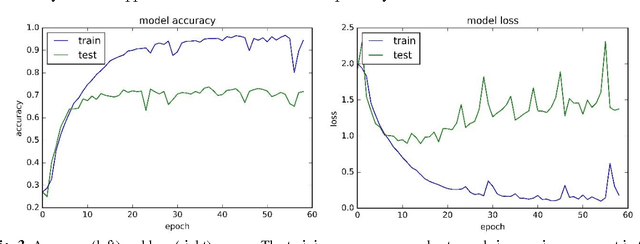
Food image recognition is one of the promising applications of visual object recognition in computer vision. In this study, a small-scale dataset consisting of 5822 images of ten categories and a five-layer CNN was constructed to recognize these images. The bag-of-features (BoF) model coupled with support vector machine was first tested as comparison, resulting in an overall accuracy of 56%, while the CNN performed much better with an overall accuracy of 74%. Data expansion techniques were applied to increase the size of training images, which achieved a significantly improved accuracy of more than 90% and prevent the overfitting issue that occurred to the CNN without using data expansion. Further improvement is within reach by collecting more images and optimizing the network architecture and relevant hyper-parameters.